从 CVE 学 Shiro 安全-2

CVE-2016-4437
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2016-4437 / CNVD-2016-03869 / SHIRO-550 |
| 影响版本 | shiro 1.x < 1.2.5 |
| 漏洞描述 | 如果程序未能正确配置 “remember me” 功能使用的密钥。 攻击者可通过发送带有特制参数的请求利用该漏洞执行任意代码或访问受限制内容。 |
| 漏洞关键字 | cookie | RememberMe | 反序列化 | 硬编码 | AES |
| 漏洞补丁 | Commit-4d5bb00 |
| 相关链接 | SHIRO-441 https://www.anquanke.com/post/id/192619 |
漏洞详解
Shiro 从 0.9 版本开始设计了 RememberMe 的功能,用来提供在应用中记住用户登陆状态的功能。
RememberMeManager
首先是接口 org.apache.shiro.mgt.RememberMeManager,这个接口提供了 5 个方法:
getRememberedPrincipals:在指定上下文中找到记住的 principals,也就是 RememberMe 的功能。forgetIdentity:忘记身份标识。onSuccessfulLogin:在登陆校验成功后调用,登陆成功时,保存对应的 principals 供程序未来进行访问。onFailedLogin:在登陆失败后调用,登陆失败时,在程序中“忘记”该 Subject 对应的 principals。onLogout: 在用户退出时调用,当一个 Subject 注销时,在程序中“忘记”该 Subject 对应的 principals。
之前曾在 DefaultSecurityManager 的成员变量中见到了 RememberMeManager 成员变量,会在登陆、认证等逻辑中调用其中的相关方法。
AbstractRememberMeManager
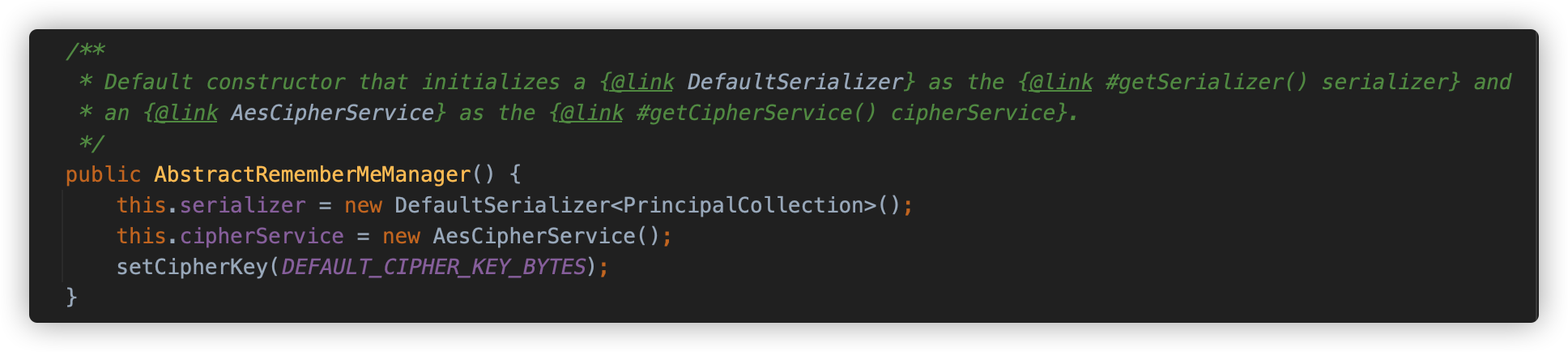
同时,Shiro 还提供了一个实现了 RememberMeManager 接口的抽象类 AbstractRememberMeManager,提供了一些实现技术细节。先介绍其中重要的几个成员变量:
DEFAULT_CIPHER_KEY_BYTES:一个 Base64 的硬编码的 AES Key,也是本次漏洞的关键点,这个 key 会被同时设置为加解密 key 成员变量:encryptionCipherKey/decryptionCipherKey 。serializer:Shiro 提供的序列化器,用来对序列化和反序列化标识用户身份的 PrincipalCollection 对象。cipherService:用来对数据加解密的类,实际上是org.apache.shiro.crypto.AesCipherService类,这是一个对称加密的实现,所以加解密的 key 是使用了同一个。
在其初始化时,会创建 DefaultSerializer 作为序列化器,AesCipherService 作为加解密实现类,DEFAULT_CIPHER_KEY_BYTES 作为加解密的 key。
CookieRememberMeManager
在 shiro-web 包中提供了具体的实现类 CookieRememberMeManager,实现了在 HTTP 无状态协议中使用 cookie 记录用户信息的相关能力。其中一个比较重要的方法是 getRememberedSerializedIdentity,具体逻辑如下图:
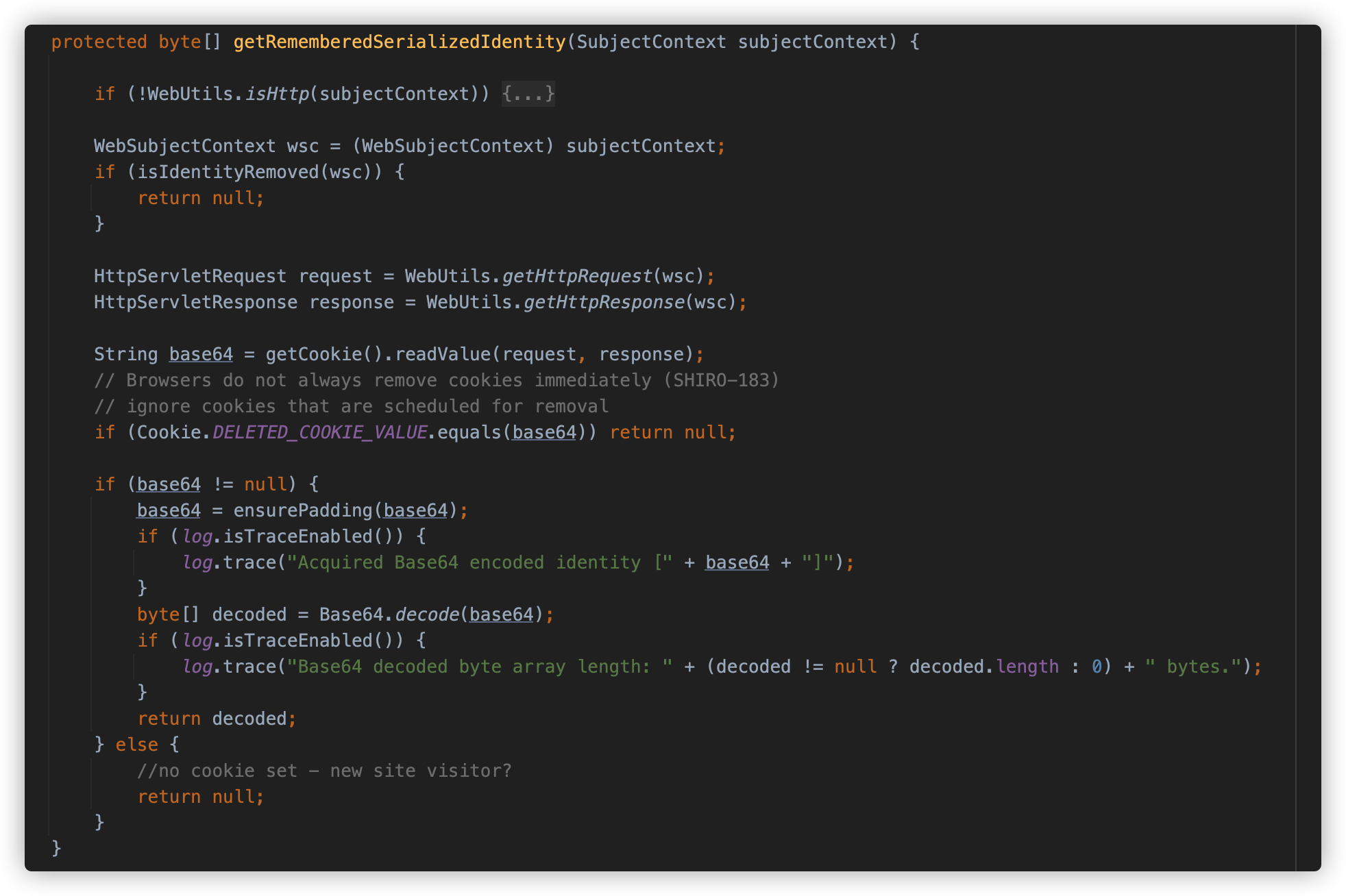
简单来说就是获取 Cookie 中的内容并 Base64 解码返回 byte 数组。
漏洞点
大概了解上面几个类的关键点后,就可以来关注这个漏洞的利用了。之前提到过,在 Filter 处理流程中,无论是 ShiroFilter 还是 IniShiroFilter, doFilter 方法都是继承至 AbstractShiroFilter,会调用 AbstractShiroFilter#doFilterInternal 方法,使用保存的 SecurityManager 创建 Subject 对象。具体调用流程大概如下:
AbstractShiroFilter.doFilterInternal()
AbstractShiroFilter.createSubject()
WebSubject.Builder.buildWebSubject()
Subject.Builder.buildSubject()
DefaultSecurityManager.createSubject()
DefaultSecurityManager.resolvePrincipals()
DefaultSecurityManager.getRememberedIdentity()
AbstractRememberMeManager.getRememberedPrincipals()
CookieRememberMeManager.getRememberedSerializedIdentity()
创建 Subject 对象后,会试图从利用当前的上下文中的信息来解析当前用户的身份,将会调用 DefaultSecurityManager#resolvePrincipals 方法,继续调用 AbstractRememberMeManager#getRememberedPrincipals 方法,如下图:
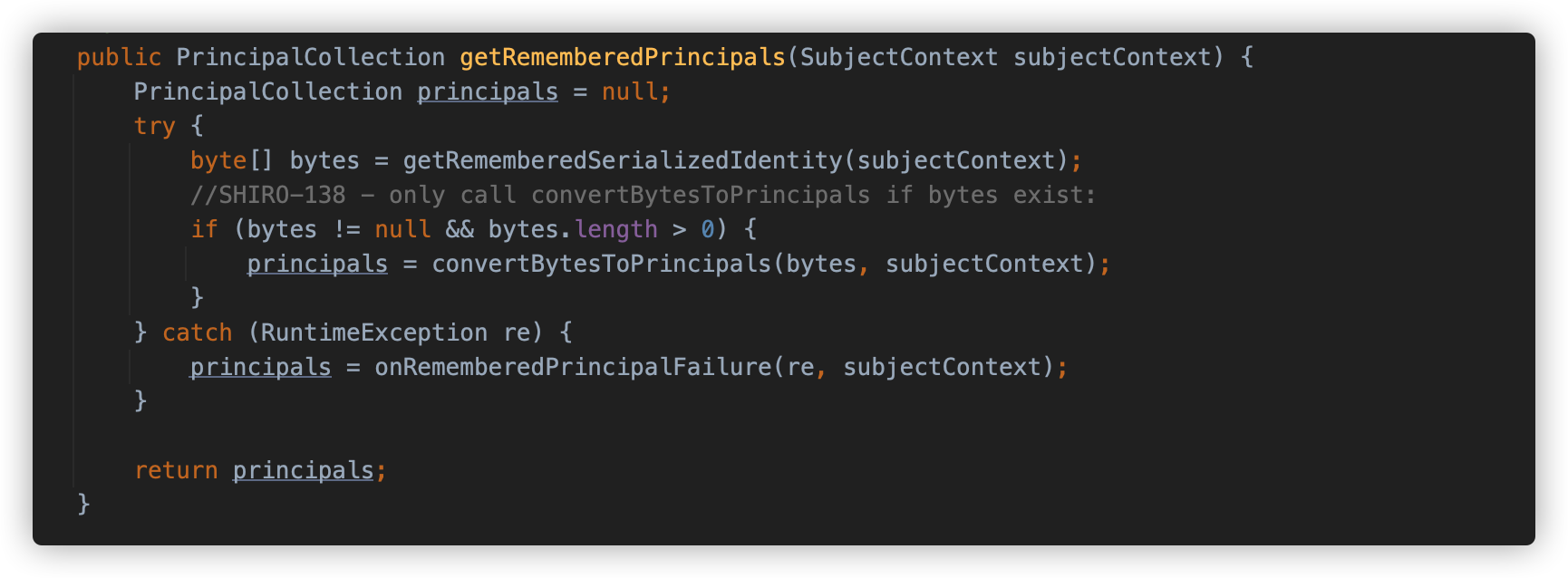
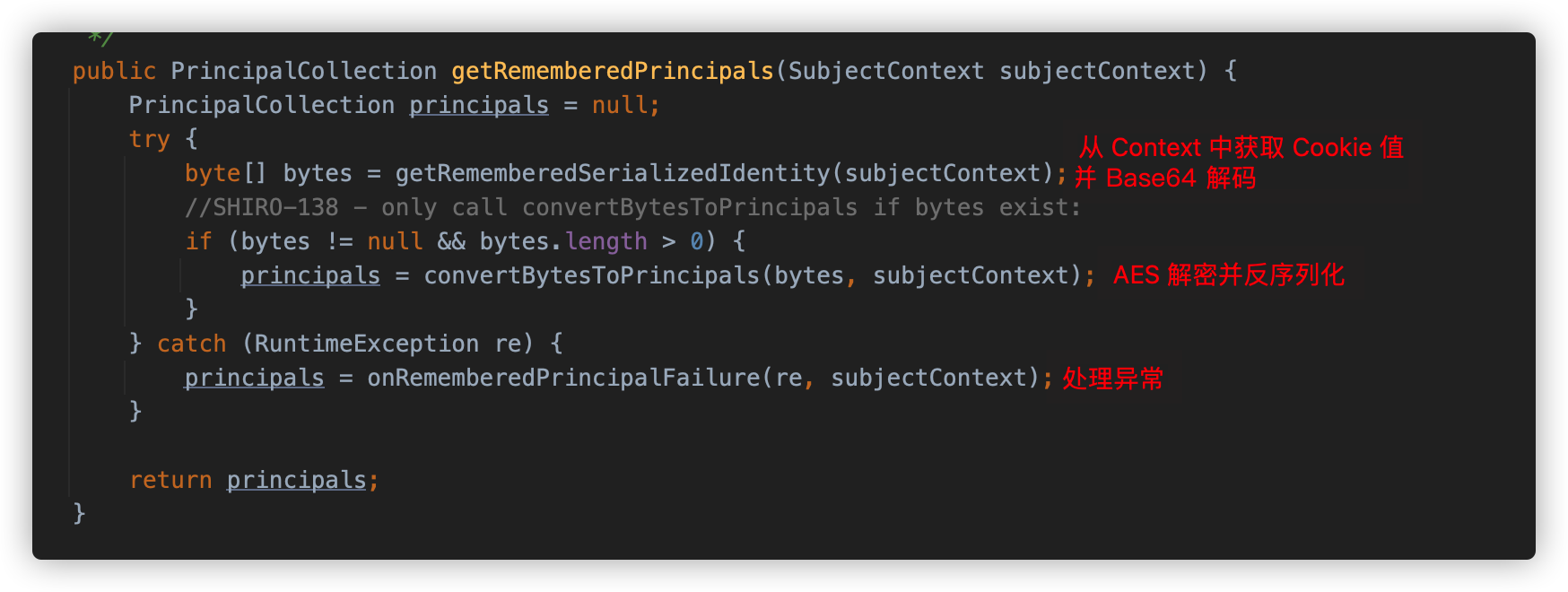
这个方法就是将 SubjectContext 中的信息转为 PrincipalCollection 的关键方法,也是漏洞触发点。在 try 语句块中共有两个方法,分别是 getRememberedSerializedIdentity 和 convertBytesToPrincipals 方法。
刚才提到,CookieRememberMeManager 对 getRememberedSerializedIdentity 的实现是获取 Cookie 并 Base64 解码,并将解码后的 byte 数组穿入 convertBytesToPrincipals 处理,这个方法执行了两个操作:decrypt 和 deserialize。

decrypt 是使用 AesCipherService 进行解密。
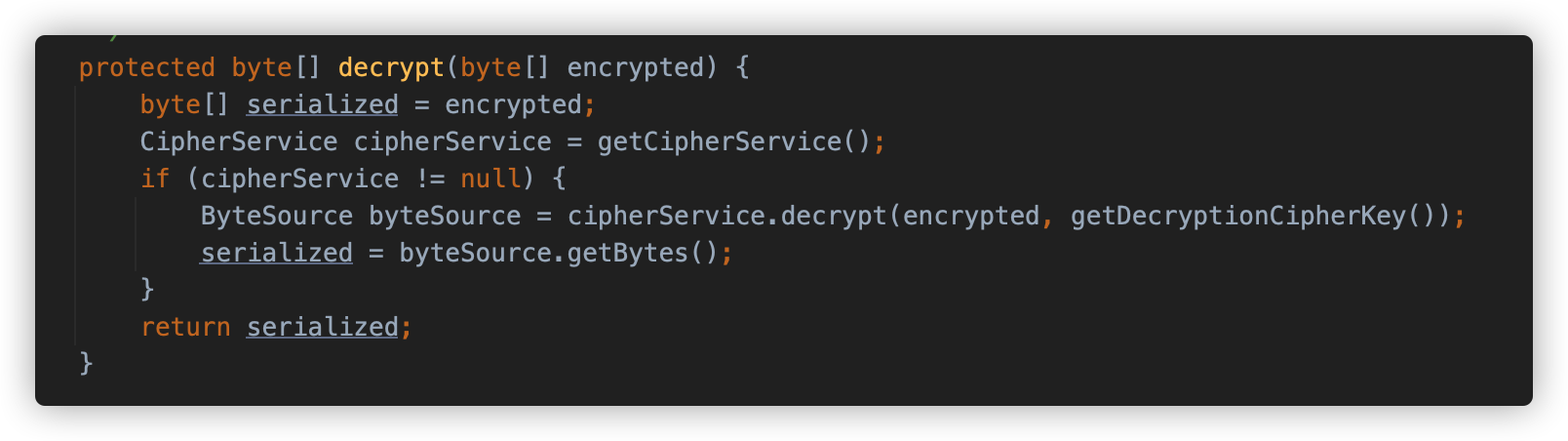
deserialize 调用 this.serializer#deserialize 方法反序列化解密后的数据。

在 Shiro 中,序列化器的默认实现是 DefaultSerializer,可以看到其 deserialize 方法使用 Java 原生反序列化,使用 ByteArrayInputStream 将 byte 转为 ObjectInputStream ,并调用 readObject 方法执行反序列化操作。
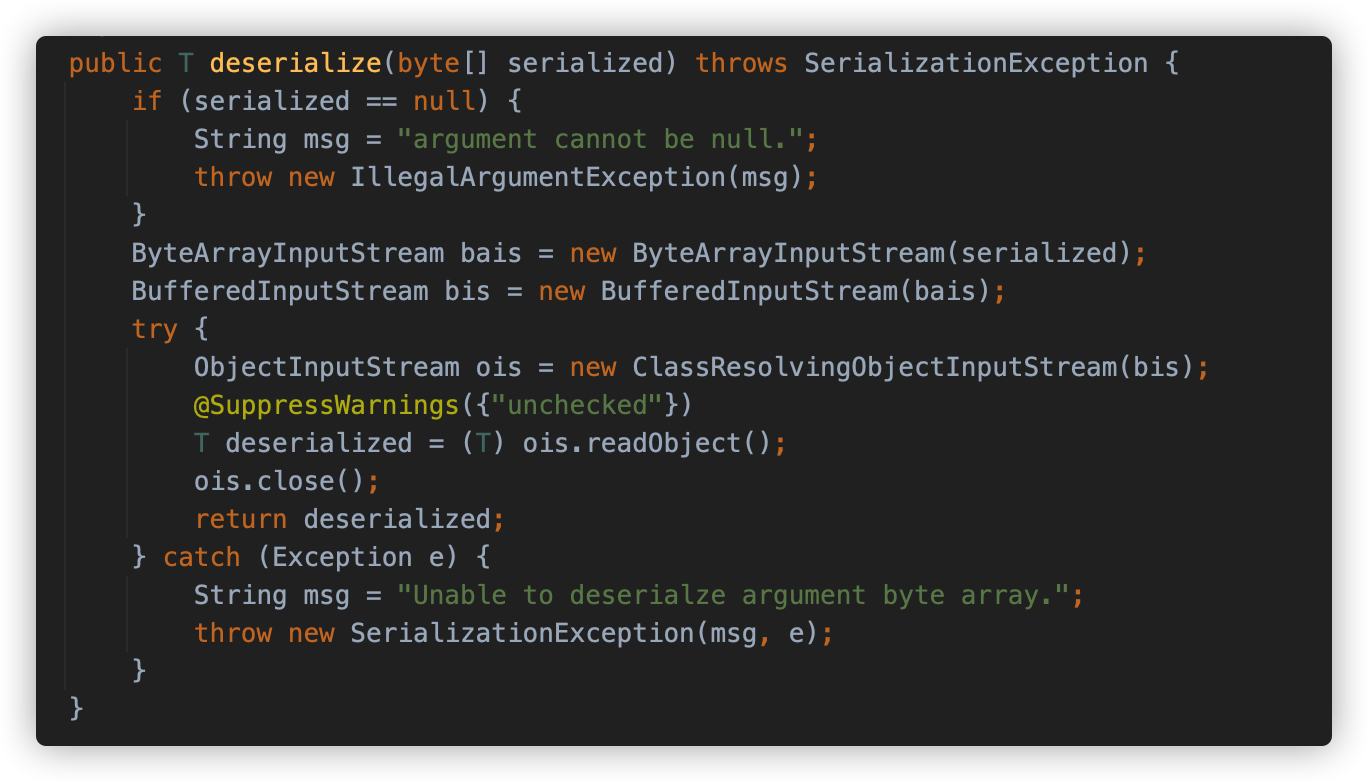
反序列化得到的 PrincipalCollection 会被 set 到 SubjectContext 供后续的校验调用。
以上就是 Shiro 创建 Subject 时执行的逻辑,跟下来后就看到了完整的漏洞触发链:攻击者构造恶意的反序列化数据,使用硬编码的 AES 加密,然后 Base64 编码放在 Cookie 中,即可触发漏洞利用。
小坑
漏洞流程到这里就明白了,接下来就是使用环境内存在的 Gadget 进行攻击了,但是这个有一个小问题。在使用一些 Gadget 如 CC6 时会报错:Unable to load clazz named [[Lorg.apache.commons.collections.Transformer;]。
很多文章对其描述如下:
Shiro 使用 ClassResolvingObjectInputStream 执行反序列化的操作,这个类重写了 resolveClass ,实际使用 ClassLoader.loadClass() 方式而非 ObjectInputStream 中的 Class.forName() 的方式。而 forName 的方式可以加载任意的数组类型,loadClass 只能加载原生的类型的 Object Array。
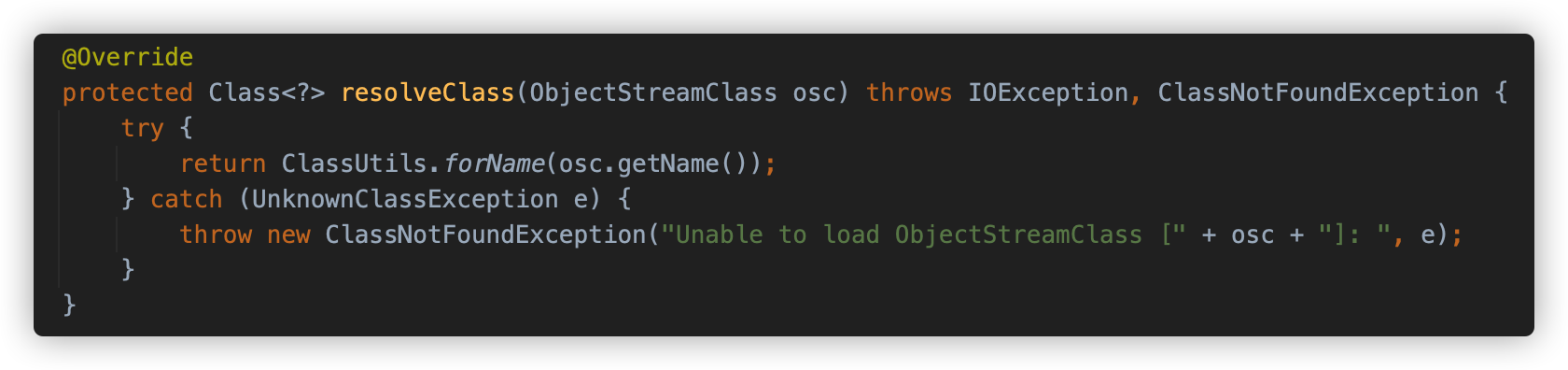
在代码审计知识星球中的《Java安全漫谈 - 15.TemplatesImpl在Shiro中的利用.pdf》 及 《Shiro-1-2-4-RememberMe反序列化漏洞分析-CVE-2016-4437.pdf》两篇文章中针对此问题进行了讨论和调试。
其中 @rai4over 师傅指出,ClassLoader.loadClass() 其实也是可以加载数组类型, 而且在 Tomcat 情况下,最终的调用还是使用 Class.forName()。
P牛没给出调试过程,给出了他的结论:如果反序列化流中包含非 Java 自身的数组,则会出现无法加载类的错误。
总结下来,这可能还是类加载器的问题。网上多篇文章中都给出了此问题的两个解决方案:
- 使用 RMI 中的 Gadget 做跳板,再执行 CC 反序列化链,这样可以加载;
- 改造 CC 链,组合 InvokerTransformer 与 TemplatesImpl,避免使用 Transformer 数组。
这两部分知识在我之前的《Java 反序列化取经路》及《Java RMI 攻击由浅入深》中均有知识铺垫,非常简单,不再重复粘贴代码。
关于此漏洞还有诸多延伸,将在后续章节中进行详解。
漏洞修复
早在 SHIRO-441,就有人提出了硬编码可能导致的安全信息泄露问题,但是官方并未理睬,直到 foxglovesecurity 团队的 @breenmachine 发出了关于 Java 反序列化的文章,漏洞提交者看了这篇文章,发掘了整个流程,将硬编码解密和反序列化结合起来,才引起了官方重视。
Shiro 在 1.2.5 的更新 Commit-4d5bb00 中针对此漏洞进行了修复,描述为:Force RememberMe cipher to be set to survive JVM restart.If the property is not set, a new cipher will be generated.
也就是说,应用程序需要用户手动配置一个 cipherKey,如果不设置,将会生成一个新 key。

通过代码更新可以看出,Shiro 移除了 AbstractRememberMeManager 中的硬编码 key 成员变量 DEFAULT_CIPHER_KEY_BYTES,在程序初始化时使用了 AesCipherService 生成了新的 key。
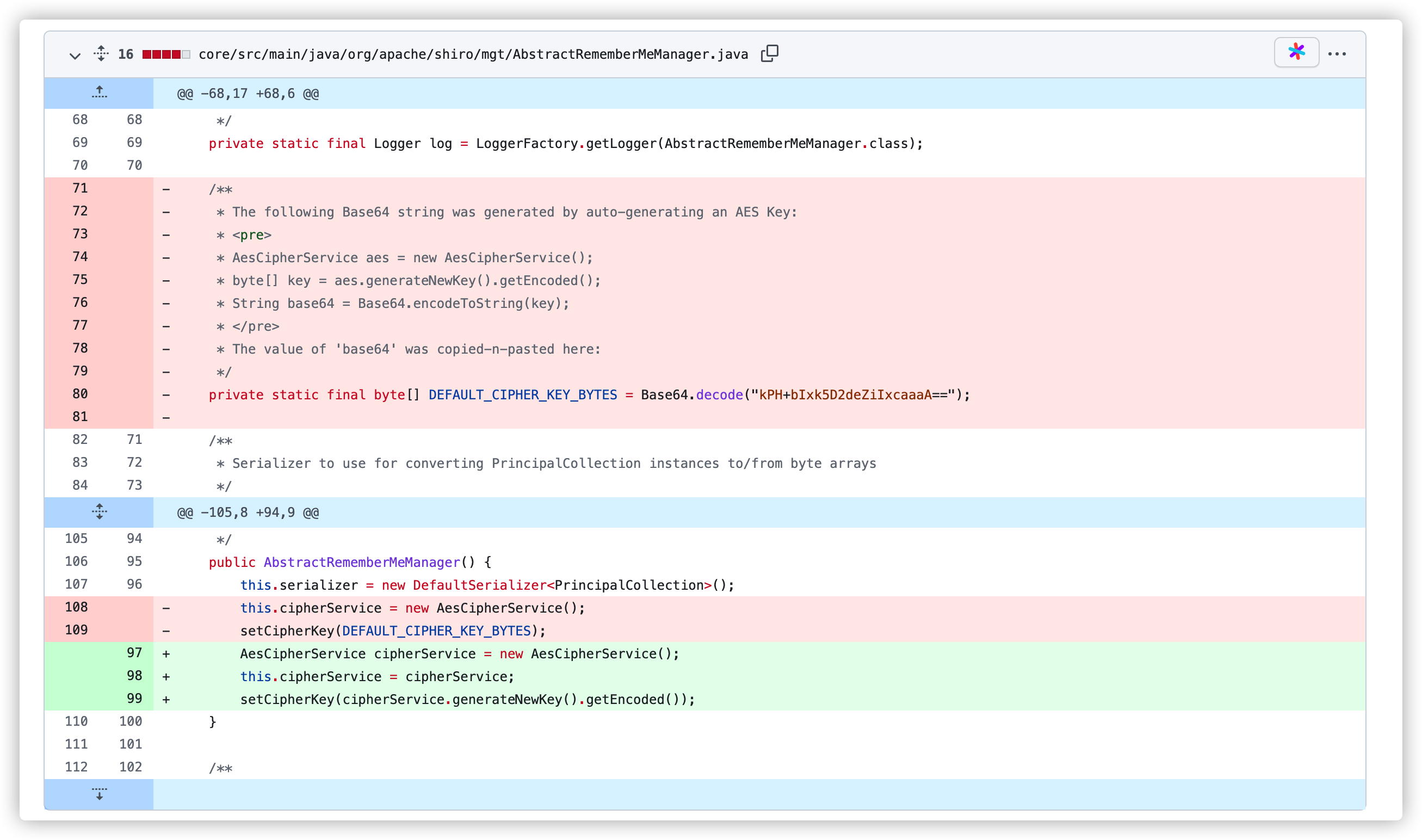
这一更新就缓解了硬编码的问题,但是并不代表程序完全安全,因为反序列化流程没变,如果用户自己将 cipherKey 设置为原本硬编码的key,或者比较常见的 key,那程序还是会受到攻击。
CVE-2016-6802
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2016-6802 / CNVD-2016-07814 |
| 影响版本 | shiro < 1.3.2 |
| 漏洞描述 | Shiro 使用非根 servlet 上下文路径中存在安全漏洞。远程攻击者通过构造的请求, 利用此漏洞可绕过目标 servlet 过滤器并获取访问权限。 |
| 漏洞关键字 | 绕过 | Context Path | 非根 | /x/../ |
| 漏洞补丁 | Commit-b15ab92 |
| 相关链接 | https://www.cnblogs.com/backlion/p/14055279.html |
漏洞详解
本漏洞类似 CVE-2010-3863,依旧是路径标准化导致的问题,不过之前是在 Request URI 上,本漏洞是在 Context Path 上。
之前提到,Shiro 调用 WebUtils.getPathWithinApplication() 方法获取请求路径。逻辑如下:
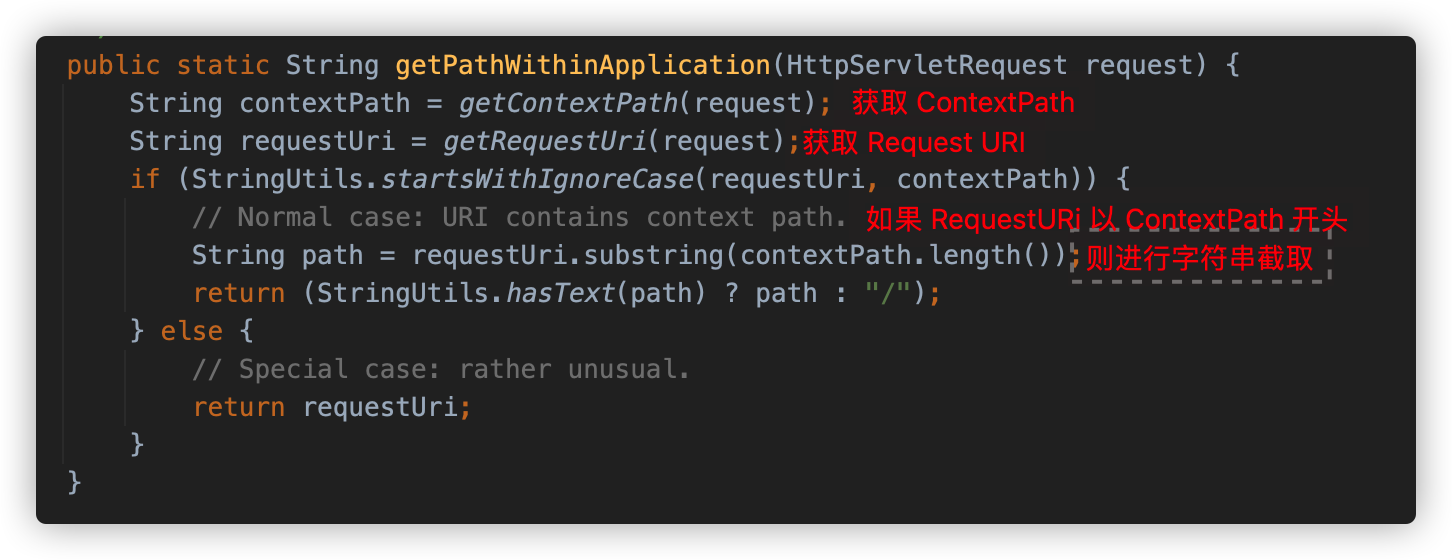
其中调用 WebUtils.getContextPath() 方法,获取 javax.servlet.include.context_path 属性或调用 request.getContextPath() 获取 Context 值。并调用 decodeRequestString 进行 URLDecode。
由于获取的 Context Path 没有标准化处理,如果是非常规的路径,例如 CVE-2010-3863 中出现过的 /./,或者跳跃路径 /su18/../,都会导致在 StringUtils.startsWithIgnoreCase() 方法判断时失效,直接返回完整的 Request URI 。
这样 Shiro 匹配不到配置路径,就会在某些配置下发生绕过,如下图:
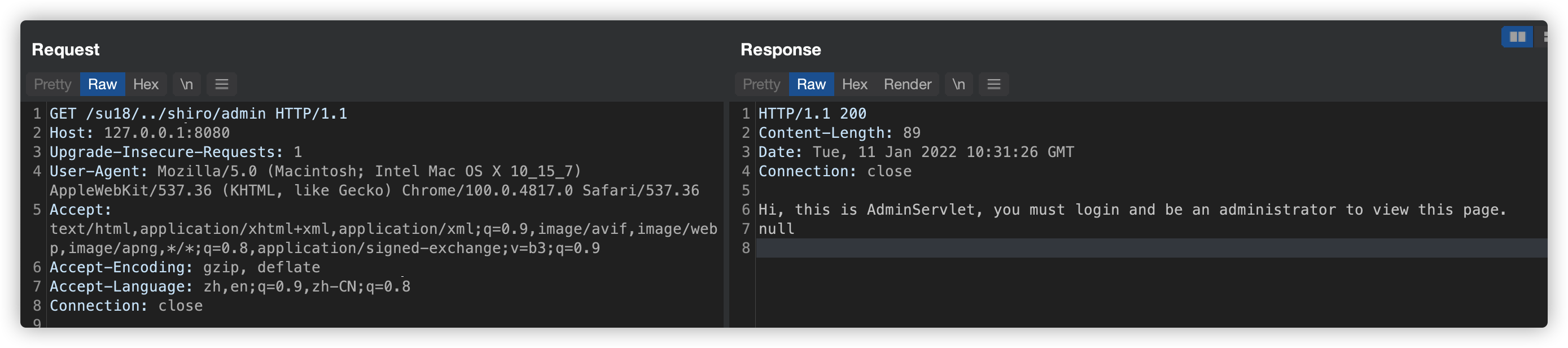
ContextPath
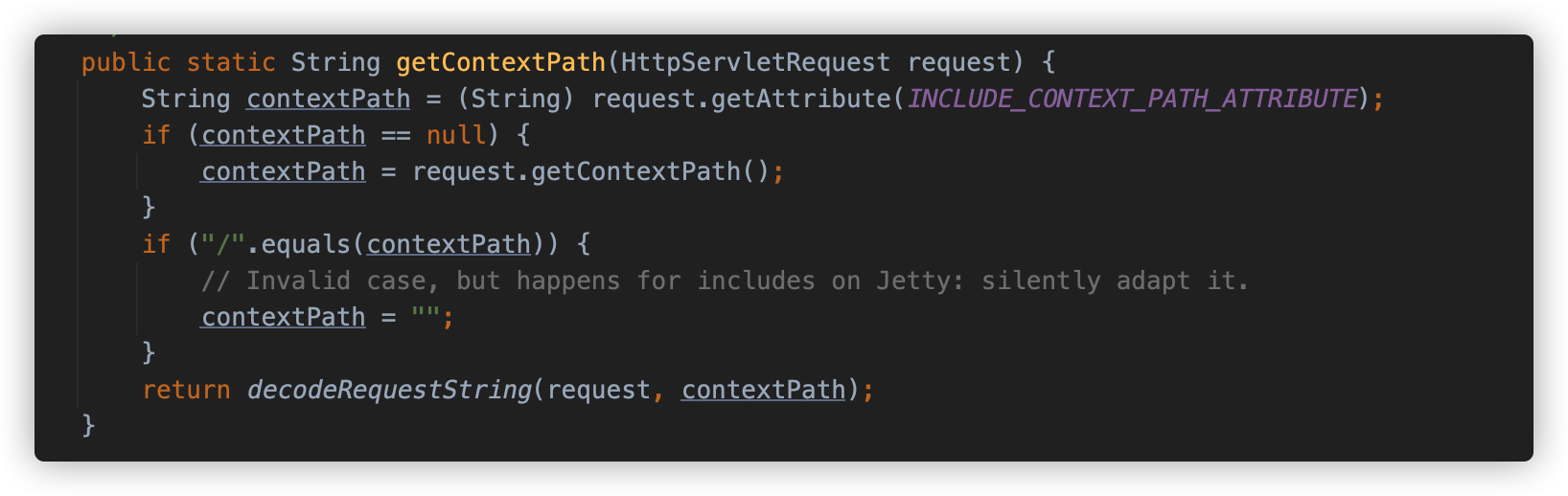
到这里漏洞原理基本说清楚了,但是有一个需要关注的点是,request.getContextPath() 为什么会返回 "/su18/../shiro",应用程序怎么处理的 Context Path?
这里以 Tomcat 为例,request.getContextPath() 方法的实际实现在 org.apache.catalina.connector.Request 中,这个逻辑其实自己 DEBUG 一下很快就清楚了,我这里简单描述一下其中的逻辑。
方法从 ServletContext 中获取 ContextPath,然后获取 RequestURI。

然后从第二个 "/" 开始,每次截取到下一个 "/",做路径标准化,对比 ContextPath,直到两者相等,则 substring 到指定位置后返回。
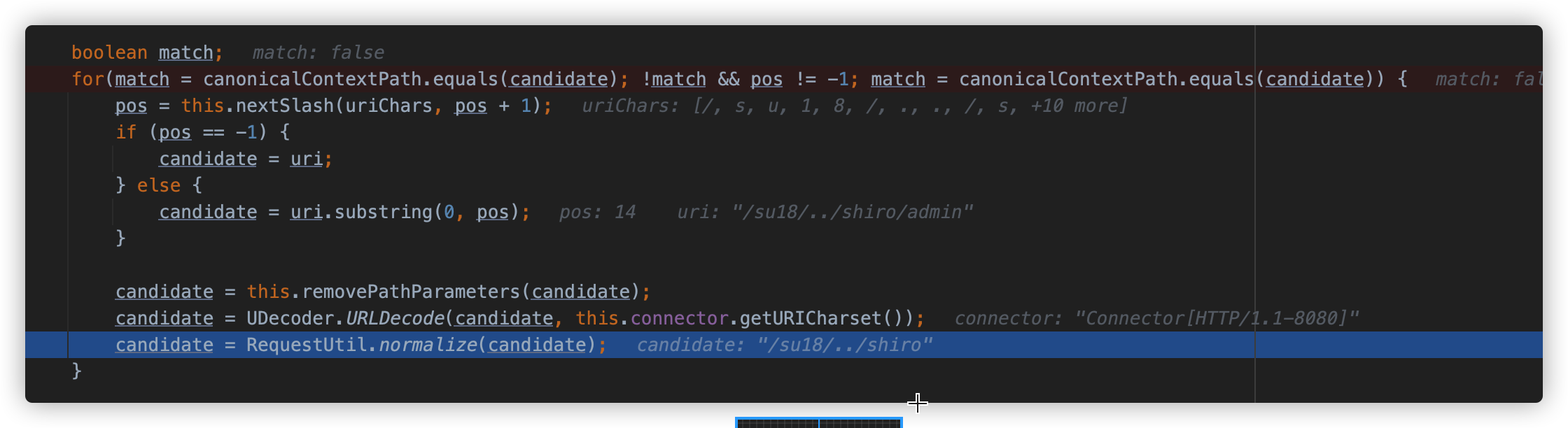
例如,访问 "/su18/../shiro/admin",而 context path 是 "/shiro",就会有如下的过程:
- "/su18/" 标准化为-> "/su18" 匹配 "/shiro" 失败;
- "/su18/.." 标准化为-> "/" 匹配 "/shiro" 失败;
- "/su18/../shiro" 标准化为-> "/shiro" 匹配 "/shiro" 成功,于是返回
于是 request.getContextPath() 就返回 "/su18/../shiro" 了。
漏洞修复
Shiro 在 1.3.2 版本的更新 Commit-b15ab92 中针对此漏洞进行了修复。
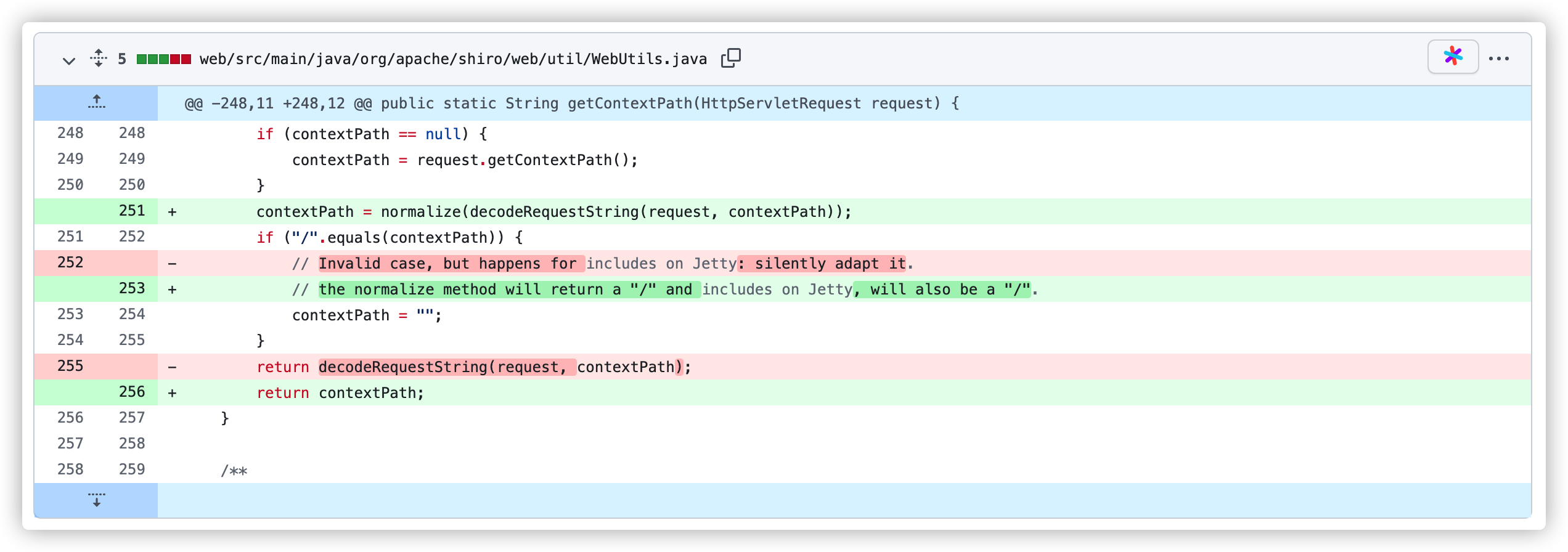
通过代码可以看出,在 WebUtils.getContextPath 方法进行了更新,使用了修复 CVE-2010-3863 时更新的路径标准化方法 normalize 来处理 Context Path 之后再返回。
本次更新还附带相关的测试文件,里面提供了很多的案例,其实可以用作 fuzz 思路。

但这里提出几个思考:
- shiro 用
request.getContextPath()获取之后自己做标准化,为什么不直接request.getServletContext().getContextPath()? - shiro 从
request.getRequestURI()中获取然后截取,为什么不直接用request.getServletPath()?
CVE-2019-12422
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2019-12422 / CNVD-2016-07814 / SHIRO-721 |
| 影响版本 | shiro < 1.4.2 (1.2.5, 1.2.6, 1.3.0, 1.3.1, 1.3.2, 1.4.0-RC2, 1.4.0, 1.4.1) |
| 漏洞描述 | RememberMe Cookie 默认通过 AES-128-CBC 模式加密,这种加密方式容易受到 Padding Oracle Attack 攻击,攻击者利用有效的 RememberMe Cookie 作为前缀, 然后精心构造 RememberMe Cookie 值来实现反序列化漏洞攻击。 |
| 漏洞关键字 | 反序列化 | RememberMe | Padding | CBC |
| 漏洞补丁 | Commit-a801878 |
| 相关链接 | https://blog.skullsecurity.org/2016/12 https://resources.infosecinstitute.com/topic/padding-oracle-attack-2/ https://codeantenna.com/a/OwWV5Ivtsi |
漏洞详解
本次漏洞实际并不是针对 shiro 代码逻辑的漏洞,而是针对 shiro 使用的 AES-128-CBC 加密模式的攻击,首先了解一下这种加密方式。
AES-128-CBC
AES 全称 Advanced Encryption Standard (高级加密标准),是一种为了取代其前任标准(DES)而成为新标准的对称分组加密算法。这里有几个关键字:
- 对称:所谓对称加密,即使用同一组 key 进行明文和密文的转换。
- 分组加密算法:将明文分成多个等长的模块(block),使用确定的算法和对称密钥对每组分别加密解密。常见的有 ECB、CBC、PCBC、CFB、OFB、CTR 等几种算法。
- 分组长度固定为 128bit 。
- 密钥 key 的长度可以为 128 bit(16字节)、192 bit(24字节)、256 bit(32字节)。根据密钥的长度不同,推荐加密轮数也不同,上述三个密钥长度分别迭代 10/12/14 轮。加密轮数越多,安全性越好,同时也更耗费时间。
因此 AES-128-CBC 模式就代表使用 AES 密钥长度为 128 bit,使用 CBC 分组算法的加密模式。
再来了解一下 CBC,全称 Cipher Block Chaining (密文分组链接模式),简单来说,是一种使用前一个密文组与当前明文组 XOR 后再进行加密的模式。
关于 AES 加解密流程实现可以看这篇文章,关于 CBC 分组的实现可以看这篇文章。这里就不占篇幅描述了。
CBC 模式下,有三种填充方式,用于在分组数据不足时,在结尾进行填充,用于补齐:
- NoPadding:不填充,明文长度必须是 16 Bytes 的倍数。
- PKCS5Padding:以完整字节填充 , 每个填充字节的值是用于填充的字节数 。即要填充 N 个字节 , 每个字节都为 N。
- ISO10126Padding:以随机字节填充 , 最后一个字节为填充字节的个数。
Shiro 中使用的是 PKCS5Padding,也就是说,可能出现的 padding byte 值只可能为:
- 1 个字节的 padding 为 0x01
- 2 个字节的 padding 为 0x02,0x02
- 3 个字节的 padding 为 0x03,0x03,0x03
- 4 个字节的 padding 为 0x04,0x04,0x04,0x04
- ...
当待加密的数据长度刚好满足分组长度的倍数时,仍然需要填充一个分组长度,也就是说,明文长度如果是 16n,加密后的数据长度为 16(n+1) 。
Padding Oracle Attack
Padding Oracle Attack 就是针对 CBC 模式分组加密算法的一种攻击手段,可以查看这篇文章学习,英文有困难的小伙伴可以查看这篇文章,说的非常清晰。
这里还是简单的描述一下攻击思路,在加密时,最后一个分组如果长度不够,会进行填充,然后使用倒数第二个分组的密文作为 IV 进行异或,然后进行 AES 加密。
在解密时,先对密文组(CiperText)使用密钥 (Key) 进行 AES 解密,得到一个中间值(MediumValue),然后再异或 IV (也就是上一个密文组) 就会得到这个分组的明文分组(PlainText)。
这个明文分组,是经过 PKCS5Padding 规范填充过的,因此它一定是遵从 PKCS5Padding 的规范的,这个规范就是本次的攻击验证点。
Padding Oracle Attack 就是利用了异或的魅力以及 PKCS5Padding 规范的可穷举性进行的攻击,wikipedia 中给出解释:

这个攻击逻辑我想了小一天,看了 fynch3r 师傅的博客,又咨询了下,最后想通了,这里用比较清晰的话描述出来,供跟我一样密码学和数学基础较差的朋友理解:
- 攻击者修改倒数第二组密文的最后一个字节,发送到服务器,服务器解密后得到 MediumValue,将其与攻击者修改后的倒数第二组密文异或,得到 PlainText,然后对其进行 Padding 校验,此时校验大概率会失败,因为修改过的密文与 MediumValue 异或后不是原本的 Padding 了。
- 此时攻击者遍历修改倒数第二组密文的最后一个字节 ( 0x00 - 0xFF , 最多遍历 255 次 ),使其与 MediumValue 异或,直到最后一个字节异或的结果是 0x01 ,这样得到的 PlainText 是符合 Padding 规范的,攻击者期待程序返回不一样的结果进行判断。这种情况下攻击者可以知道:MediumValue 异或攻击者遍历修改倒数第二组密文的结果的最后一个字节为 0x01 ,根据异或的运算法则,MediumValue 最后一个字节就是 0x01 异或攻击者修改的字节。此时攻击者得到了
MediumValue[8]的值。此时攻击者知道了MediumValue[8]的值,还可以知道原倒数第二组密文最后一个字节的值,就可以计算出原PlainText[8]的值, - 接下来攻击者遍历修改倒数第二组密文的倒数第二个字节,此时攻击者希望异或运算后得到的明文分组的最后两个字节为 0x02 0x02,这样是符合 Padding 规范的,并且由于已经计算了出了
PlainText[8]的值,因此在这轮遍历中可以用原倒数第二组密文最后一个字节的值异或PlainText[8]再异或 0x02 作为倒数第二组密文的最后一个字节,因为它与MediumValue[8]的异或一定为 0x02,攻击者依旧只需要遍历第二组密文的倒数第二个字节即可。 - 依次类推,可以依次计算出最后一组密文中全部的 MediumValue 及 PlainText。
- 舍弃掉最后一组密文,向服务器提交第一组至倒数第二组密文,迭代之前的操作,获得倒数第二组明文。依次规律,直到获得所有分组的明文。
看了全网,发现这部分流程还是 Epicccal 师傅的相关博客写的最为清晰。
至此,攻击者可以在不知道密钥 Key 的情况下得到全部明文的值。但这有两个前提:
- 服务器会对解密结果进行 padding 校验,并且结果可以从响应中进行判断(类似 SQL 盲注)。
- 攻击者已知能正确解密和使用的密文以及初始向量 IV。
CBC Byte-Flipping Attack
到现在已经可以使用 Padding Oracle Attack 在不知道 key 的情况下获取全部明文的值,但这仅仅是信息泄露,能不能进一步篡改信息呢?这里就用到了 CBC 字节翻转攻击。
相关原理可看这篇文章以及这篇文章。这里还是简单描述:通过修改密文进而篡改明文。
在解密时,会使用 MediumValue 与上一组密文进行异或来得到明文,现在知道上一组密文,也知道本组的明文,就能计算出本组的 MediumValue,如果想要异或出不一样的数据,我们只需要篡改上一组的密文,使其跟 MediumValue 能异或出指定的数据即可。
这是一个逆推的过程:
- 获取最后一组密文,由 Padding Oracle Attack 爆破出其 MediumValue ,根据篡改后的明文与 MediumValue 异或,得到前一轮的密文。
- 再使用计算出来的前一轮的密文继续爆破出对应的 MediumValue,再根据篡改后的明文进行异或,再得到前一轮的密文。
- 以此类推到第一组,异或出的值作为起始 IV。
拼接起始 IV 以及全部计算出的每组的密文即可获得一个可以使服务器解密为指定明文数据的密文了。
Attack In Shiro
在了解上面的基础知识后,就很好理解后面的攻击流程了,攻击者通过已知 RememberMe 密文使用 Padding Oracle Attack 爆破和篡改密文,构造可解密的恶意的反序列化数据,触发反序列化漏洞。
之前提到过 Padding Oracle Attack 是利用类似于盲注的思想来判断是否爆破成功的,在校验 Padding 失败时的返回信息应该不同,那 shiro 是否满足这个条件呢?
关注点依旧从 AbstractRememberMeManager#getRememberedPrincipals 中开始,
负责解密的 convertBytesToPrincipals 方法会调用 CipherService 的 decrypt 方法,接下来的调用链大概如下:
org.apache.shiro.crypto.JcaCipherService#decrypt()
javax.crypto.Cipher#doFinal()
com.sun.crypto.provider.AESCipher#engineDoFinal()
com.sun.crypto.provider.CipherCore#doFinal()
com.sun.crypto.provider.CipherCore#fillOutputBuffer()
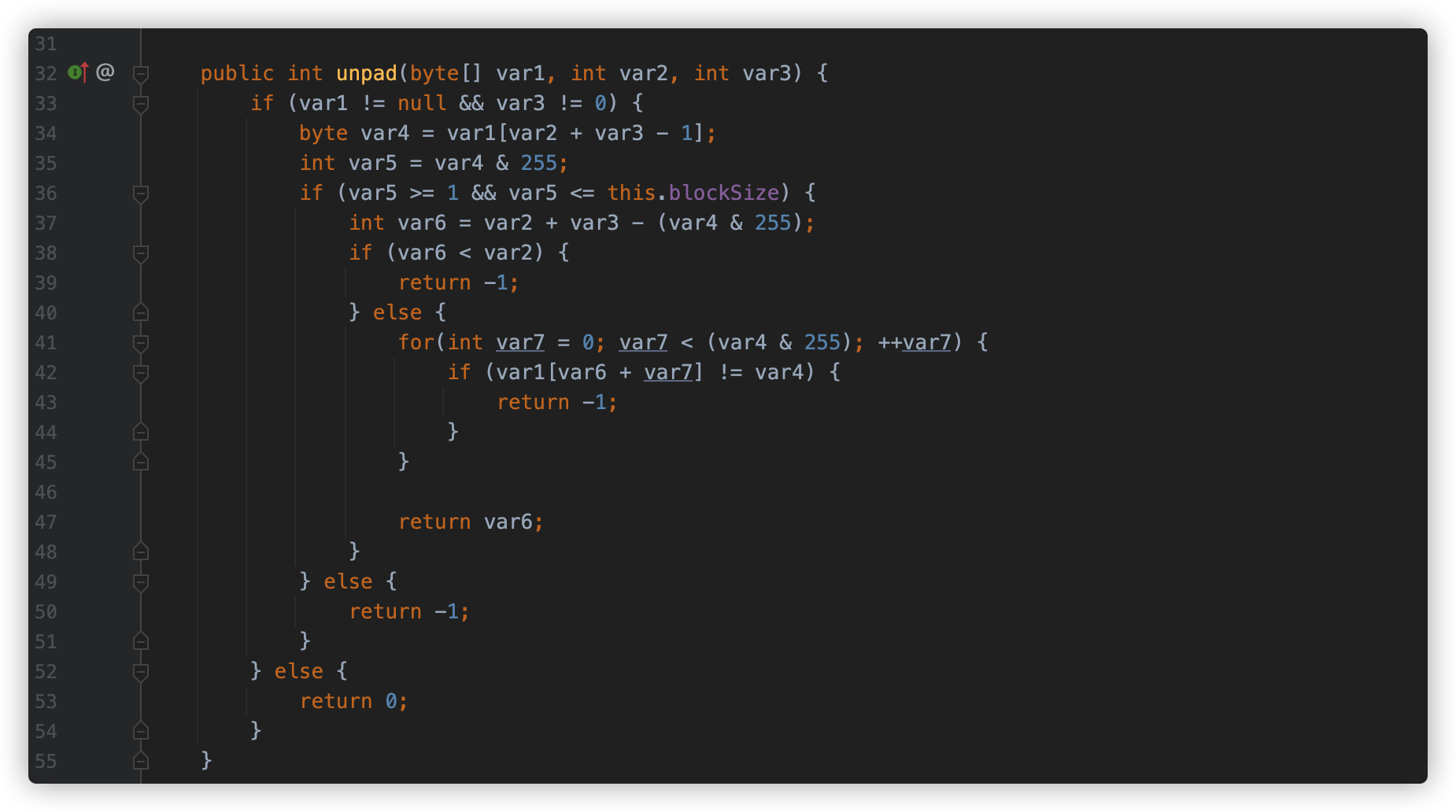
com.sun.crypto.provider.CipherCore#unpad()
com.sun.crypto.provider.PKCS5Padding#unpad()
其中 PKCS5Padding#unpad 方法中会判断数据是否符合填充格式,如果不符合,将会返回 -1。
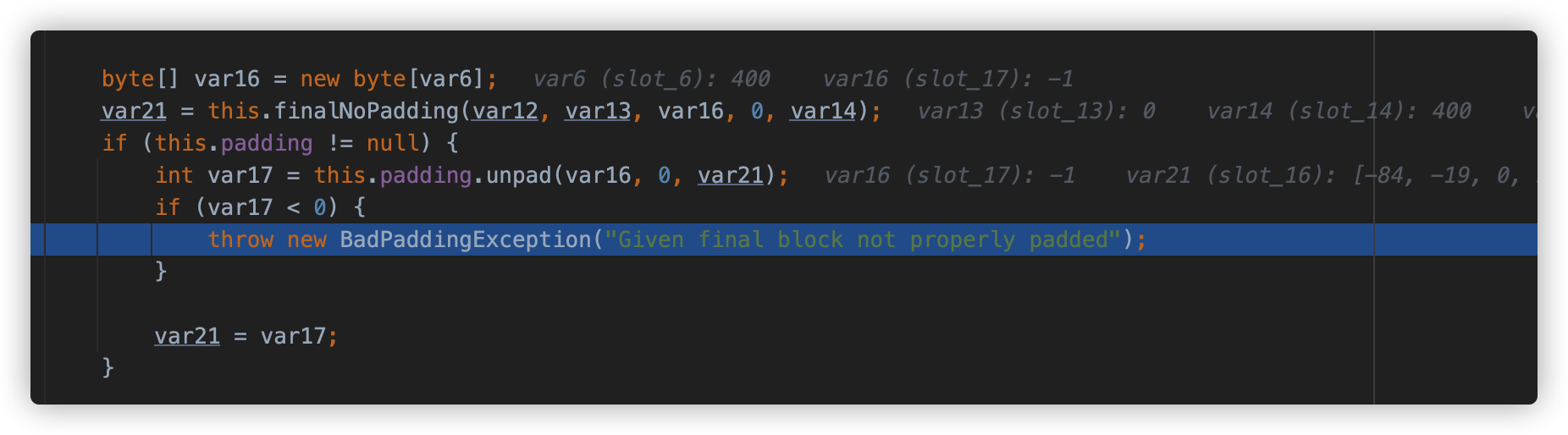
CipherCore#doFinal 方法根据返回结果抛出 BadPaddingException 异常。
被 JcaCipherService#crypt 方法 catch 住并抛出 CryptoException 异常。

被 AbstractRememberMeManager#getRememberedPrincipals 方法 catch 住,并调用 onRememberedPrincipalFailure 处理。

解析身份信息失败,将会调用 forgetIdentity 方法移除 rememberMe cookie。
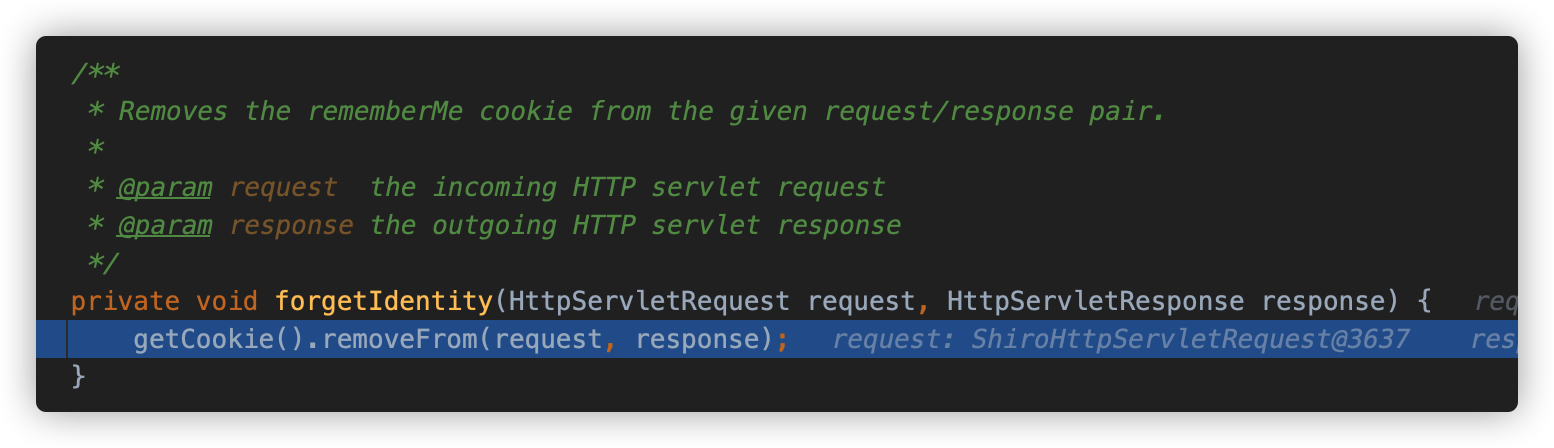
并为响应 header 添加 deleteMe 头部。
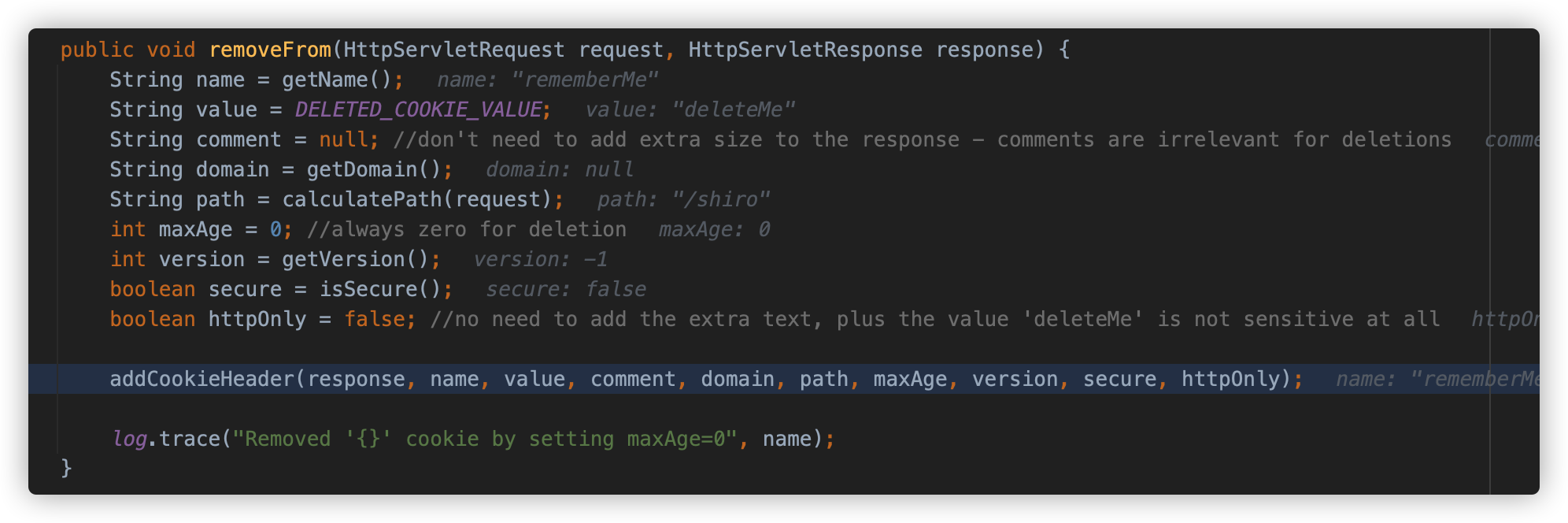
具体逻辑如下:
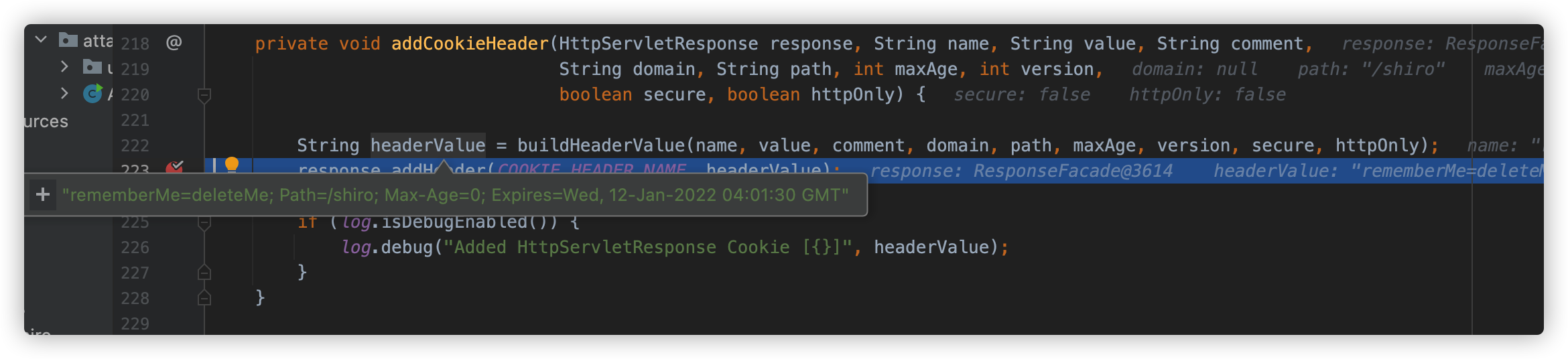
由此可见,只要 padding 错误,服务端就会返回一个 cookie: rememberMe=deleteMe;,攻击者可以借由此特征进行 Padding Oracle Attack。
漏洞复现
到此全部基础知识补充完毕,可以开始真实的攻击了。在这里由于时间、精力和技术的限制,就不再自行实现相关逻辑,直接使用 longofo 师傅的项目。
首先获取一个有效的 rememberMe 值,其次生成一个反序列化利用的 payload,然后使用如下参数执行攻击。
java -jar PaddingOracleAttack.jar http://127.0.0.1:8080/shiro/index "F5Dktxan5VMiWyF...MM" 16 /Users/phoebe/IdeaProjects/ysoserial-su18/URLDNS.bin
将生成的 payload 放在 rememberMe 中发送至服务器。
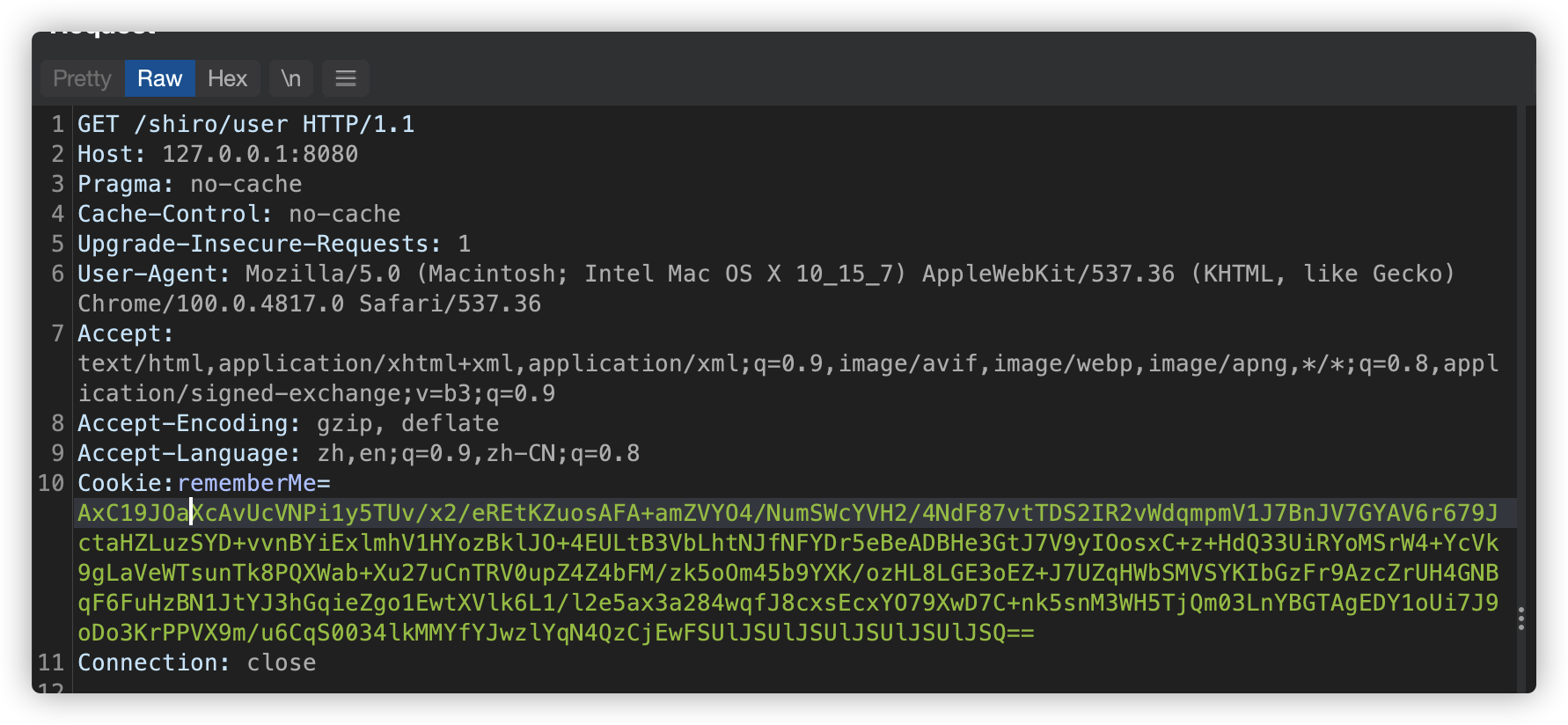
服务端成功解密并反序列化数据。
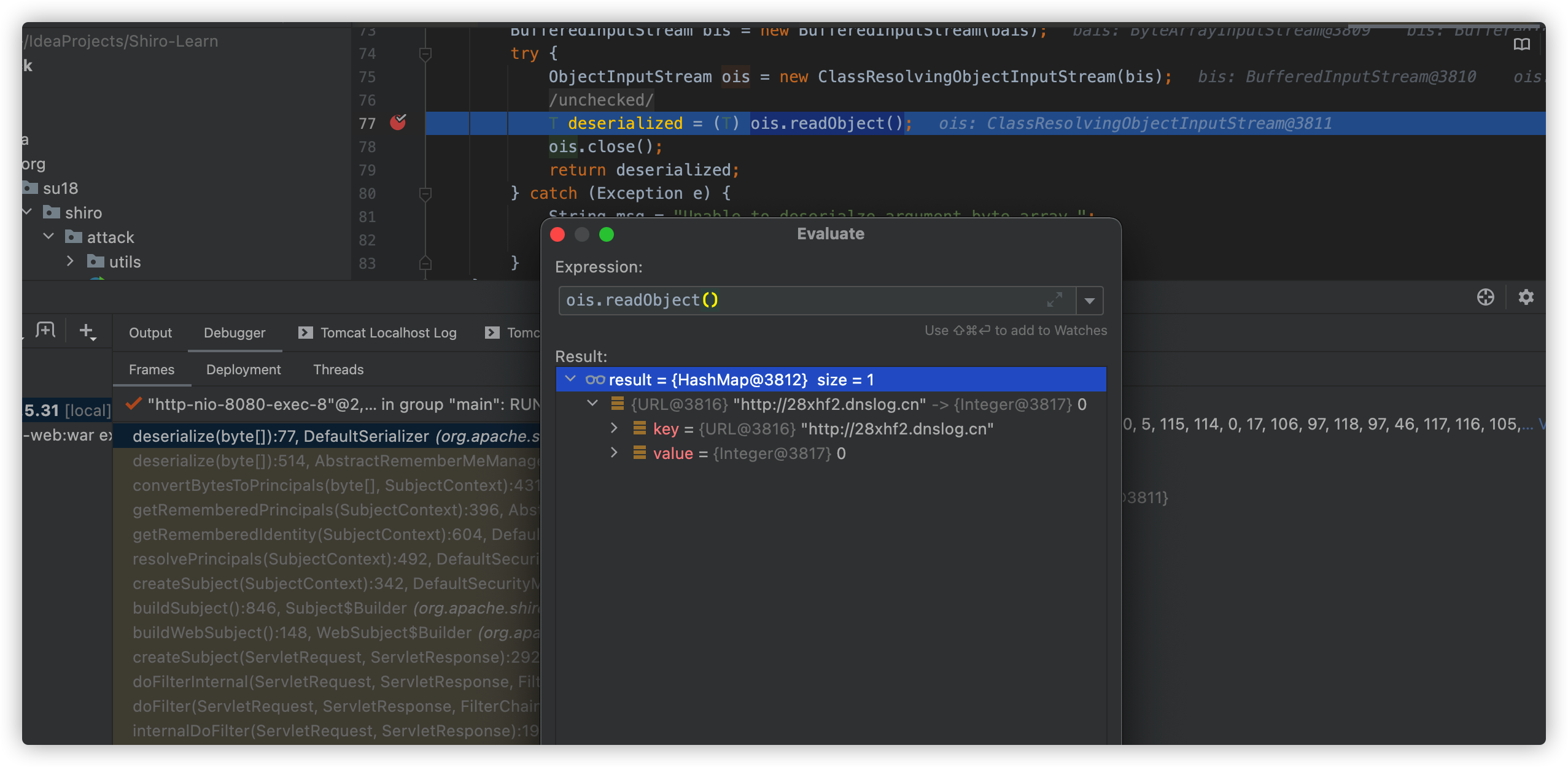
反序列化的执行逻辑与 SHIRO-550 一致,这里不再重复。
问题
这个漏洞已经完全走通了,但是存在一个严峻的问题是:
每个字节的爆破最多情况下需要 255 次,一个加密组 16 个字节,最大可能需要 255*16=4080 次爆破。
根据不通长度的 payload 将生成若干个加密组区块,每个加密块都需要进行上述爆破流程。在复杂的 payload 下,爆破生成完整的篡改包需要发出的请求数将会是天文数字。
在测试时,使用 URLDNS 进行测试,根据 payload 长度,共分了 21 个数据分组,生成篡改包共发送了 42051 个请求包,如下图。
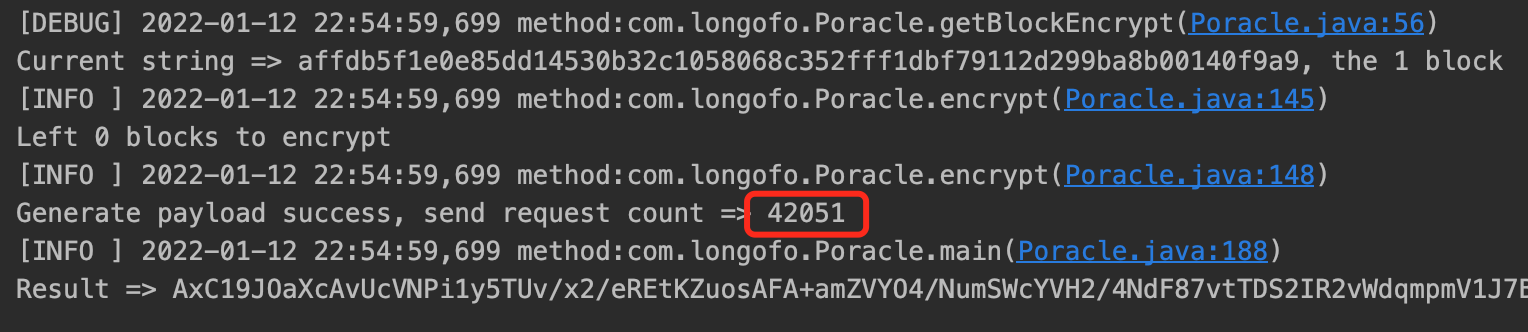
如果是使用 CC6 配合 TemplatesImpl 的 gadget,需要爆破的密文组将达到惊人的 150 个,按平均每组发送 2000 个爆破包来算(非常保守的估计),想要成功执行一次反序列化,需要发送 30W 个请求!
因此,在真实情况下,执行此漏洞的攻击代价过大,最好的方式也只能是结合 RMI 的两条链曲线救国,将真正的执行点放在其他位置,但即使是这样,也要发送几万条的请求,实在是过于离谱。
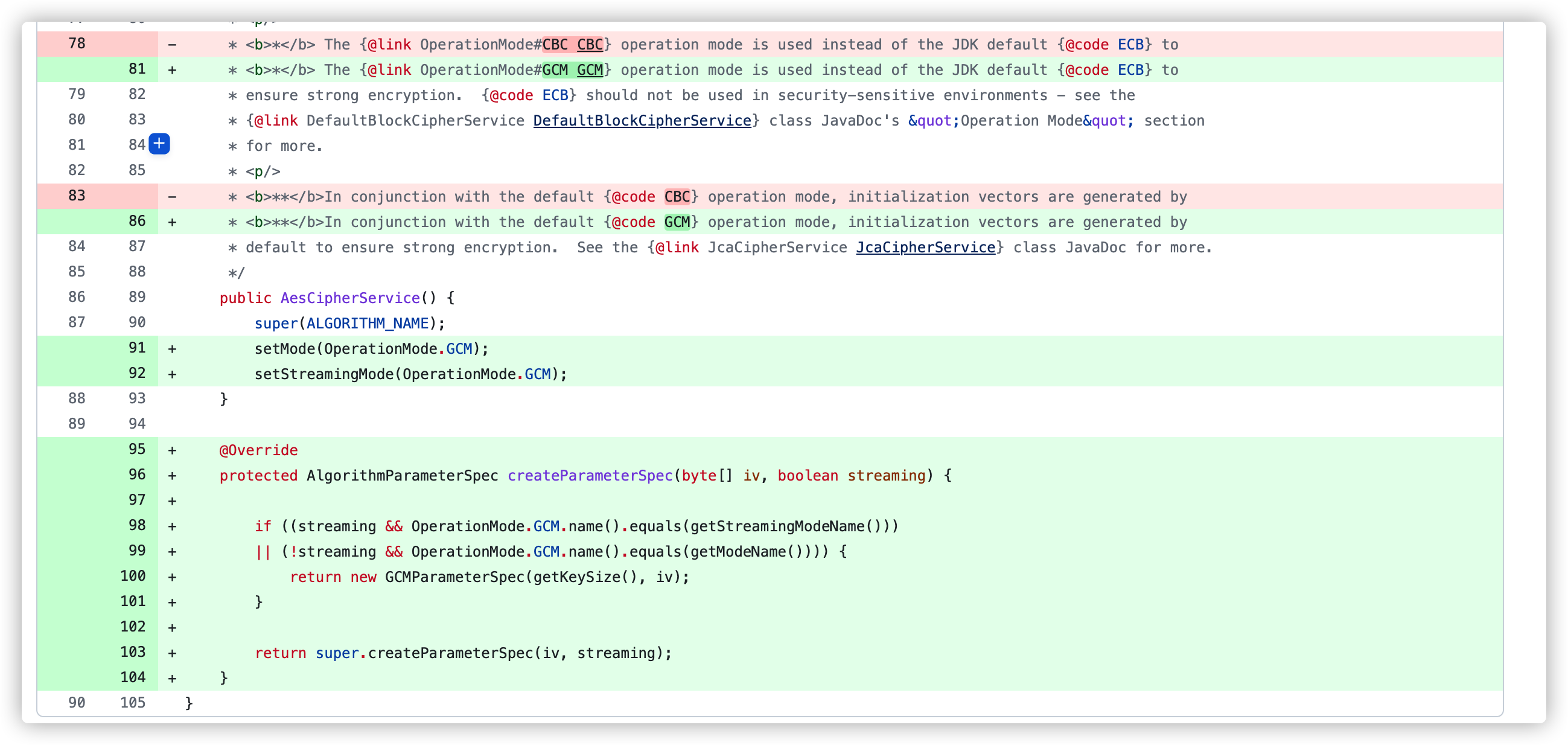
漏洞修复
在 1.4.2 版本的更新 Commit-a801878 中针对此漏洞进行了修复 ,在父级类 JcaCipherService 中抽象出了一个 createParameterSpec() 方法返回加密算法对应的类。
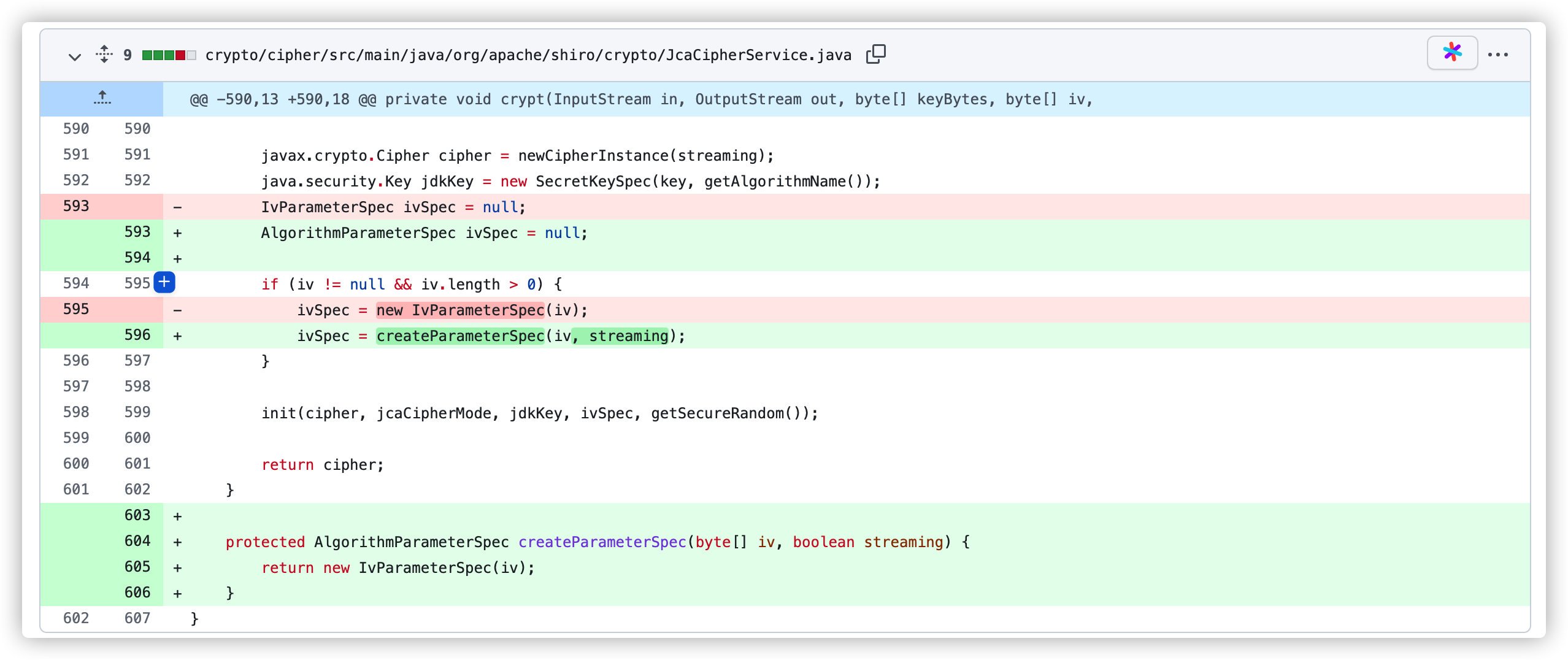
并在 AesCipherService 中重写了这个方法,默认使用 GCM 加密模式,避免此类攻击。