[旧文归档] 基于Google Hack进行信息收集

一、前情提要
在渗透测试过程中,第一步就是进行信息收集,信息收集的重要性不用再次赘述,而对于信息收集的过程,很多人将其写成了工具、脚本,于是我们就有了很多指纹识别工具、敏感文件、目录扫描工具,敏感信息探测工具,信息收集工具等等。有了这些工具,我们可以在短时间内快速的收集我们想要的信息,并且通过研究和积累,我们使用具有高命中性、通用性的字典、特征文件作为核心,在渗透测试之初快速进行信息收集。
但这些工具具有一些共同的致命的特点,就是为了达到更高的覆盖率,通常会发送大量的攻击请求至服务器,这些请求会留下痕迹,在遇到有防护手段的web服务器时,将会导致很多的麻烦,同时,安全人员也会根据黑客的行为进行画像,进行攻击防护和溯源。
这时候可能会想到,通过使用大量的代理服务器来隐匿自己的行踪,并绕过安全防护手段的监控,不得不说,在拥有大量代理池的情况下,这确实是解决问题的办法,但是并不能完全奏效,一些高级安全防护人员会从访问时间、访问频率、访问文件类型等等一系列大量特征,对攻击人员进行分组聚类,并采取杀伤链溯源的方式,将黑客从众多的代理中“揪”出来。
因此,能否在不惊动目标服务器的情况下,对目标网站进行前期最重要的信息收集,并且尽可能的获得更多的信息呢?随着这个理念的产生,有了我们今天的课题,也就是利用搜索引擎来对目标网站进行信息收集的工作。
现今,我们使用了大大小小的搜索引擎,国内外搜索引擎不计其数,每个国家都有自己的搜索引擎,我们在此选择当仁不让的“全球第一”搜索引擎Google。
同样的,这条道路也有很多的前辈涉足过,但是作为安全学习的一部分,自己走一遍才是最重要的。早在我第一次写的目录扫描器Alisa中,就简单使用了Google Hacking作为目录扫描的一部分,而在这里将其单拿出来,作为重点进行讨论。
二、Google基础铺垫
与我的其他文章一样,我们先来简略地铺垫一下Google基础性知识,这些知识你可以通过百度搜索(黑人问号脸,哈哈哈)轻易的得到,也可以参照Google官方帮助手册,如果你真的感兴趣的话,你可以购买相应的书籍进行进一步的学习。
1.基础法则
- Google 不区分大小写,除了 or 被用作布尔运算符时,就必须写做OR。
- Google 通配符(*),不同于在其他任何语言中的使用,星号在一个搜索短语中仅仅表示一个单词。
- Google 保留忽略的权利,where、how以及一些通用的单词、字母和单个数字,会被Google默认忽略。
- Google限制最多搜索32个单词,包含搜索项和高级运算符。不过也有一些其他方法绕过这种限制,比如使用通配符来代替某些搜索项。
2.基础查询
最简单的查询包含一个单词或者在搜索界面输入的单词组合,如 chicken attack。稍微复杂一点的是短语搜索,将要搜索的一组单词包括在双引号找那个进行搜索。当Google遇到一个短语的时候,它会严格按照你给定的顺序对短语中的所有单词进行搜索,Google不会排除在短语中找到的常用词,如“chicken attack”。
我们还可以使用布尔运算符和特殊字符进行查询,最常用的是 AND,用来在一个查询中包含多个搜索项。但是对于Google来讲,AND是多余的,默认情况下,Google会自动搜索你查询中的所有元素。
**加号(+)**会强制包含跟着它的单词。例如Google默认排除了一些常用词,但我们想强制Google来搜索这些词,我们就可以搜索 +and justice for +all。
另一个常用的布尔运算符是 NOT,在功能上与 AND 运算符是相反的,NOT运算符把一个单词排除出一个搜索之外。使用这个运算符最好的方法就是在一个搜索单词前加上减号(-)。减号与搜索项之间不含空格。例如 hacker -jacket。
另一个运算符是 OR。还可以用**竖线符(|)**来表示。可以指示Google 在查询时落在其中一个或另一个查询上。
Google不会受到括号影响。我们可以利用括号增加查询语句的可读性。例如:
intext:(password|passcode) intext:(username|userid|user) filetype:csv
在搜索无效的时候也不要紧,多看看Google给出的提示。
3.高级运算符
在这里我直接放置一张高级运算符速查表,对于每一个的具体使用方法以及使用细节以及额外需要注意的点,各位看官自行学习。
| 高级运算符 | 特性/要点 |
|---|---|
| intitle | 在页面的标题里查找字符串 与其他运算符混合使用效果佳 |
| allintitle | 在一个页面的标题里查找所有搜索项 与其他运算符或搜索项混合使用效果差 |
| inurl | 在一个页面的URL里查找字符串 与其他运算符混合使用效果佳 (有时 site 和 filetype 做的比 inurl 好) |
| allinurl | 在一个页面的URL里查找所有搜索项 与其他运算符或搜索项混合使用效果差 |
| filetype | 基于文件扩展名搜索特殊类型文件 需要一个额外搜索项 其他运算符或搜索项混合使用效果差 |
| allintext | 别用它 |
| site | 把一个搜索限定在一个特别的网站或域中 与其他运算符混合使用效果佳 能够单独使用 |
| link | 搜索一个网站的链接或者URL 无法与其他运算符或搜索项混合使用 可以扩展成包含目录名、文件名、参数等内容的完整URL |
| inanchor | 在链接的描述性文字中查找文本 其他运算符或搜索项混合使用效果佳 用作寻找网站之间的关系 |
| daterange | 寻找在一个特定日期范围内索引过的页面 需要一个搜索项 与其他运算符或搜索项混合使用效果佳 可以被as_qdr淘汰 |
| numrange | 在特定范围内查找一个数字 与其他运算符或搜索项混合使用效果佳 需要两个参数,可以简写 |
| cache | 显示Google缓存的页面拷贝 无法与其他运算符或搜索项混合使用 有很多妙用,但结果优点不可预测 |
| info | 显示关于一个页面的总结信息 无法与其他运算符或搜索项混合使用 直接搜网站名或URL会得到相同的结果 |
| related | 显示与所给网站或URL相关的站点 无法与其他运算符或搜索项混合使用 |
| stocks | 为一个股票代码显示Yahoo财经的股票列表 无法与其他运算符或搜索项混合使用 与本次课题无关 |
| define | 显示单词或短语的各种不同含义 无法与其他运算符或搜索项混合使用 与本次课题无关 |
我们在网上看到的一些十分实用十分高级的Google技巧,大多来自上述高级运算符之间的组合使用,因此,深入理解并熟练运用这些运算符是十分有必要的,在此我强烈建议,如果你在阅读到这部分之前是一名使用Google Hack的小白,先暂停一下,在搜索引擎上亲自使用一些,看一看返回的结果,闭上眼,用心去体验。
如果觉得手动输入还是很别扭的话,点击网址https://pentest-tools.com/information-gathering/google-hacking,里面会有一些简单的样例可以供我们理解。
三、Google Hacking入门
在知晓了Google搜索语法之后,我们就可以进行简单的Google Hack了。
我们先来看看,除了在”日站“、”渗透“的时候使用Google Hack,我们做为一名”信息爆炸时代“的”年轻人“,合理使用Google搜索这一利器,能带给我们什么样的好处呢?
先看几个有意思的东西。
搜索play pacman,可以直接玩耍吃豆人游戏。

搜索flip a coin,性感硬币,在线抛出。

搜索sunrise & sunset,后面跟地名,可以获得当地的日出日落时间。

除了这些Google提供的“便民功能”之外,善用高级运算符的搜索,也可以给我们带来意想不到的结果,例如:
intitle:index .of 1080p
怎么样,还充什么爱奇艺会员吗?(我爱奇艺会员还有3年到期。。)
filetype:mobi 三体
怎么样,还在kindle上花钱吗?其他类型的文件大体如此。将上述两种结合在一起,你就可以获得更加精准的搜索。
site:zhihu.com 胸大 体验
想要合法看图怎么办?比如知乎,经常有人在知乎发问,***是种什么体验?那么我们把关键字加入“胸大”二字,看看有关胸大和体验的提问,再看看答案的配图,你会回来感谢我的。

intitle:写真 inanchor:下载
留图不留种,菊花万人捅?不存在的兄弟,我们只看有下载链接的网站。
简单的搜索就能获得这些,只要你姿势多,大量免费资源唾手可得。岂不美哉?
我就这么跟你说吧,国内有千千万万的服务、网站、资源提供商,只是收集了一些免费的东西,汇总在一起,加个壳,然后就收费向外出售,不只是网站,一些小密圈、公众号、教育收费项目、所谓的VIP项目,也一样!你付费觉得是在支持作者,实际上你是在交智商税!这方面的案例太多了!身边的很多朋友越来越开始支持知识付费,这本身无可厚非,但你花钱买了别人公布在互联网上的东西,你居然还不知道,这难道不是可悲吗??在开章我就提到,作为一名”信息爆炸时代“的”年轻人“,你应该跟得上时代的步伐,善用Google,你就知道一些收费作者有多不要脸,会用Google,你就知道你能节省多长时间,能用Google,你就知道你身边的人有多弱,弱到自己都不知道自己弱。这段话可能有点愤世嫉俗,我不讨论政治,我也不是崇洋媚外,我只是不想用一个搜医院能给自己搜死的搜索引擎而已。以工作来讲,面向百度和CSDN的程序员,和面向Google和Stack Overflow的程序员的区别,我想不用我多说了。
不过在此还要多说一句,对于有版权的资源,无论是人道主义,还是法律的约束,我们应该支持版权,熟悉我的人都知道,52pojie上烂大街的软件和游戏,我也去steam买正版,不是因为我有钱,而是因为这件“商品”使我愉悦,我愿意支付他的价值,愿意让为之付出努力的人得到回报。
最后再教一招,在你Google搜索的URL上添加参数 &safe=off,你就知道“没时间解释了,快上车”是什么意思了。不要问我为什么能科学的上网,不直接去看一些P开头的网站,因为我们要优雅,不要色情。没想到我也是个“绅士”,哈哈哈哈。
说到这,再开个车,想看高质量的“小视频”,不要去搜那些你想的出的关键字,都被人监控和屏蔽了,试试“有钱真好”。
除此之外,Google还有很多的彩蛋等着大家去发现,有兴趣的可以去看看,一些链接会被放在第七章。
我们接着看看,Google Hack在黑客或白帽子进行入侵或资料收集时,都能产生哪些效用:
- 在入侵之前,可以利用Google Hack技术进行信息收集(本次讨论的课题)。
- 在发现或者公布某个漏洞之后,利用Google Hack技术大量收集这个漏洞的主机或网站,可能用来“抓鸡”或进行安全态势分析、
- 在入侵过程中搜索,开辟其他的思路,访问历史遗留后门等等。
接下来我们将在第四章进行信息收集部分的集中研究。
在这里要赘述一下,我们认知中,通常的搜索引擎是通过爬取来获得网站全部内容的,换言之,网站上未进行连接指向的文件和目录,在理论上不会被搜索引擎抓取到,并且,网站与搜索引擎通过 robots 协议来约束能够爬取和不能够爬取的页面。那也就是说,一个网站能够被Google抓取的内容是极其有限的。
但是在实际搜索中发现,Google能够抓到一些没有链接的文件或目录之外,还十分惊奇的能够抓取到更深的目录,在工作中,甚至发现了Google抓取到一些网站需要登录之后才能使用的后台功能链接,直接访问会被重定向至登录页面。Google从何手段得知这些页面我们不得而知,但一个简单的想法可能是:Google可能会从Chrome的历史浏览记录里获得数据(瞎猜的)。
还有一点需要注意的是,Google缓存访问的匿名性。
Google会把抓取到的绝大部分Web数据保存一份拷贝。这些都可以通过搜索页面的缓存链接来访问。在访问Google的缓存链接时,不仅仅从 Google 数据库加载页面,也会连接真实的服务器来访问图表和其他非 HTML 内容。我们希望通过访问Google缓存,来进行访问的匿名性,即不向目标服务器发送任一数据包,却可以拿走目标服务器的敏感数据。我们无需通过代理服务器,使用一个快速的剪贴和URL修改,就能以相当匿名的方式浏览一个缓存页面。举个例子,考虑查询 site:phrack.org,我么并非直接点击缓存链接,而是右击缓存链接,然后把这个URL拷贝到剪贴板。最后在这个URL的末尾附加上参数 &strip=1 。这个缓存页面已经剥离了外部引用,不会引入原始服务器的元素,但页面可能已经无法辨认。
四、信息收集
终于到了本次课题的重点部分,我们按照在渗透测试中信息收集的流程,进行分解,看看使用 Google Hacking如何实现这些功能。
1.基础信息收集
子域名查询,使用site限定范围并使用*来进行泛查询,最后用-排除掉主域名,得到的就是子域名:
site:*.example.com -www.example.com
**C段查询,**如果你知道这个网站的IP,你也可以使用site结合通配符来查询在C段上存在的网站:
site:18.18.18.*
2.敏感文件收集
备份文件查询,备份文件大致可分为网站备份文件、单页面的备份文件、配置文件的备份文件,讲道理,现在都9102年了,大概只有安全意识为0的运维人员或开发人员会把这些文件放在网站目录中,找到它们的概率较低,但一旦找到了,可以说本次入侵基本就结束了:
对于网站备份文件,可以使用常用压缩文件扩展名作为搜索目标:
site:example.com filetype:zip
site:example.com filetype:rar
site:example.com filetype:tar
site:example.com filetype:tar.gz
site:example.com filetype:7z
site:example.com filetype:cab
site:example.com filetype:gz
site:example.com filetype:iso
site:example.com filetype:bz2
site:example.com filetype:jar
可以看到,这里我列举了常见的一些压缩格式,为什么我不用布尔逻辑汇总在一条查询里呢?因为在实际测试中,发现 filetype 和 ext 运算符与布尔逻辑的合作性并不是很好,经常有查不到东西的情况出现,因此我们宁愿多进行几次查询,来增加我们查询的命中率。
对于单页面的备份文件,道理也是一样的,常见的单页备份文件扩展名为:bkf、bkp、bak、old、backup,不过不完全是这些,我还见过有人在后面添加时间,如 config.php.201812,这部分可以自行拓展。
配置文件,配置文件也能为攻击者提供大量的有用信息,需要注意的是,我们想找的是存放着线上应用真实的配置文件,不是配置文件的样例模板,因此在构造搜索语句时,有几点可以注意一下:
- 使用独一无二的单词或短语。
- 过滤掉单词 sample example test how to tutorial 来排除明显的样例文件。
- 用 -cvs 过滤掉CVS库,它里面经常存放着默认配置文件。
- 在一个配置文件中查找出一个最常被修改的域,对这个域执行一个精简搜索来减少潜在的无用文件过样例文件。
如果想宽泛的进行查询,通过文件名即可:
site:example.com filetype:conf
site:example.com filetype:cnf
site:example.com filetype:xml
site:example.com filetype:ini
site:example.com filetype:dll
site:example.com filetype:ctl
site:example.com filetype:inf
site:example.com filetype:cfg...
根据不同文件名的后缀,结合你想查的东西,可以增加运算符,获得更精准的命中:
site:example.com filetype:cnf my.cnf -cvs -example
site:example.com filetype:cfg mrtg "target[*]" -sample -cvs -example
也可以通过查询URL获得一些命中:
site:example.com inurl:config "fetch = +refs/heads/*:refs/remotes/origin/*"
site:example.com inurl:configuration.php intext:"class JConfig {"
更多的,需要我们根据不同的配置文件进行精心构造,也可以参照GHDB。
日志文件,日志文件通常以 log 结尾,最简单的基础搜索就是:
site:example.com filetype:log inurl:log
或者更简单的如:
site:example.com ext:log log
这个类型在 GHDB 中也有整理。不同类型的日志文件泄漏了不同类型的信息。可以在攻击中被利用。
数据库文件,有的管理人员定期会将数据库备份并将备份文件统一放入某一文件夹中。使用 filetype 即可:
site:example.com filetype:sql
site:example.com filetype:dbf
site:example.com filetype:mdb
site:example.com filetype:wdb
使用 filetype 可能会导致覆盖不全,因为如果是二进制格式的文件,Google 不能理解这个文件的格式,那我们就不能使用 filetype 运算符查找文件,因此,我们还应该使用 inurl 进行查询,来增加命中率:
site:example.com inurl:db|backupdb...
除了真实的数据库文件,还可能存在一些数据库转储文件,数据库任意格式的输出都能构成一个数据库转储。使用一个完整的数据库转储,数据库管理员能完整地重建一个数据库。这意味着一个完整转储的细节不仅仅是数据库表格的结构,还包含着每张表中的每一条记录。类似的搜索如:
site:example.com intext:"Dumping data for table"
然后通过搜索额外的感兴趣的单词或短语,以助于缩小范围。同时我们还可以通过 filetype 及其他的高级运算符来进一步缩小。
样例文件,web服务器软件经常会在 web 目录里存有手册和文档一起提供给用户,这些文件告诉用户如何进行使用或理解。这些文件将会带来一些安全风险。
例如Apache Tomcat的默认样例目录,使用以下语句搜索:
site:example.com intitle:"apache tomcat/" "Apache Tomcat examples"
又例如snoop servlet的漏洞:
site:example.com inurl:/examples/jsp/snp/snoop.jsp
再比如使用 mysql_connect 函数的 PHP 脚本泄漏了机器名、用户名和明文密码,如 db_connect.inc。
这样的例子还有很多,这里不进行一一列举,可以多尝试一下template、example等关键字。
其他敏感文件,除了上面提到的这些,还有一些能带给我们敏感信息的文件,如robots.txt文件。里面可能写了不希望爬虫爬取的目录,这些目录通常就是敏感目录。
site:example.com (inurl:"robot.txt" | inurl:"robots.txt" ) intext:disallow filetype:txt
注册表,如果现在还能在网站目录中搜到注册表,那也是没谁了,不过还是记录一下:
site:example.com filetype: reg HKEY_CURRENT_USER username
3.敏感目录收集
目录列表,这可以说是比较喜闻乐见的一种漏洞类型了,在报告里,它是低危,但是在渗透中,它能带来的效用却很高,在实战中,遇见的几率也是略低。典型的目录列表有一个描述当前目录的标题、一个可以点击的文件和目录列表,通常还有一个标注目录列表底部的页脚。
目录列表将存在以下问题:
- 无法保障进出数据的安全。不阻止用户下载特定的文件或访问特定的目录。
- 会显示一些信息,这些信息能帮助攻击者了解到关于Web服务器特定的技术细节。
- 无法分辨哪些是公共文件,哪些是后台文件。
- 经常是偶然被显示出来,因为只要顶层索引文件遗失或失效时,很多Web服务器就会显示一个目录列表。
使用下面两条基本可以即快又准的搜索到包含目录遍历的位置:
site:example.com intitle:index .of "parent directory"
site:example.com intitle:index .of name size
想要查看指定目录的遍历也是可以的:
site:example.com intitle:index .of inurl:admin
除了文件信息,目录列表还能给我们带来很多有用的数据,如服务器软件名、服务器版本号、服务器操作系统等。
我们也可以结合目录列表和其他运算符,直接找到我们较感兴趣的东西,如:
site:example.com intitle:index .of "Application Data/Microsoft/Credentials"
site:example.com intitle:index .of etc|.sh_history|.bash_history|passwd|people.lst|htpasswd|...
临时文件目录,临时文件目录可以泄漏一些敏感信息,历史上也记录了很多类似的漏洞:
site:example.com inurl:tmp|temp|cache...
登录位置查询,有用户登录的位置,通常来带用户中心、评论、个人信息管理、管理后台,随之而来的就存在很多漏洞,如评论存储型XSS、头像上传、越权、CSRF等等。因此查找登录位置也是重中之重,首先,我们可以使用intext查找登录位置的关键字。
site:example.com intext:管理|后台|登陆|用户名|密码|帐号|注册|admin|login|manage|manager|register|houtai|guanli|forgotten
还可以用inurl查找位置:
site:example.com inurl:admin|login|manage|manager|register|prelogin|logincheck
这部分大家也可以添加自己在渗透测试中遇见的一些登录位置遇见的关键字。
还可以根据版权信息、指纹信息查找。网站首页通常具有版权信息,这个信息可能会在登录页面再次出现:
site:example.com intext:"Powered by"
site:example.com intext:"XX科技"
敏感目录,除了上面提到的,如果你有额外希望关注的敏感目录,如“信息公开”,使用inurl直接查询就可以:
site:example.com inurl:xxgk
4.敏感信息收集
错误消息收集,首先是收集数据库报错信息,这部分信息可能暴露出SQL语句,路径等其他信息。并且,这样的点很容易出现SQL注入漏洞。
site:example.com intext:"sql syntax near"|"syntax error has occurred"| "incorrect syntax near"|"unexpected end of SQL command"|"mysql_connect()"| "mysql_query()"|"Warning: pg_connect()"
其次是,由于一些报错信息,会导致泄漏出服务器的敏感路径,我们可以直接搜索这些敏感路径,也能为我们的渗透测试来带有用的信息:
site:example.com intext:"/var/lib/"|"/var/www/"|"D:\"|"C:\"
用户名、密码和其他秘密信息,最简单的就是某些网站上直接上用户名或密码写出来:
site:example.com intext:(password|passcode|pass|密码) intext:(username|userid|user|用户|账户)
实战中没有那么简单,但是确实是有命中的,比如一些平台发布一些应用的操作方法,里面会提供一些默认的账户及口令,遇到一些安全意识较差的,没改密码的,还是有可能的。
更多的情况是在网站提供的doc格式的操作手册里搜索,这部分将在Office文档收集部分详述。
电子邮箱地址查找,电子邮件可作为社工的一个关键入口。
site:example.com intext:邮箱|邮件|email|e-mail
上面的方法比较low,但是存在一定的命中。
site:example.com intext:"@qq.com"|"@163.com"...
这个方法。。也比较low,而且搜索结果一言难尽,有些网站为了防止邮箱被抓取,会把@符号换为别的,如#等,还有的留邮箱直接留了一个Base64。这部分算个坑,大家自己琢磨把。
电话号码,电话号码也是信息收集的一部分,同样的,可以按照关键字查询:
site:example.com intext:电话|手机号|联系方式|请拨打...
手机号可以长成这样:13500882588(长春市出租车语音广告招商热线),或者这样:0431-87651234(出租车投诉电话),不要问我为什么这两个记得这么清楚,你要是常在长春打车,你也一定能记住。。
因此我尝试了numrange的搜索方法,但是效果不佳,不过对于座机号码,可以利用前面的区号来搜索,拿长春举例,长春的座机号码前面为0431,因此就可以在页面上搜索出现0431的位置,来判断是否包含电话号码。
5.Office文档收集
对于渗透测试来说,office文档中的东西也可以是比较juicy的。
对于搜索固定文件名称,最常见的使用类似 filetype:xls 这种形式的,但是由于Google不一定能完全解析到这些文件,在过程中还有一些坑,测试时发现其实使用 inurl 就可以达到目的,而且效果较好。
因此,重点在于专注内容来寻找敏感文件。
我们可以结合 intitle 、intext、inurl 、单词、短语进行测试收集,最简单的例子如:
site:example.com filetype:doc "密码"
site:example.com filetype:xls|xlxs "密码"
site:example.com filetype:doc intitle:"管理"
6.指纹识别
指纹识别技术是来判断一个网站是否使用成型的CMS,根据CMS的版本,以及历史爆出的漏洞进行定向攻击的手段,在实际渗透测试中能大大的提高效率。
那么我们使用Google Hacking能否进行指纹识别呢?答案是肯定的,但是效果不一定会好。
我们知道正常的指纹识别通过访问特征文件来确定,这部分其实也可以理解为一个目录扫描工具,想利用Google Hack的话,我们不直接访问目标文件,而是通过访问Google缓存,查看是否有类似的记录。
这种方法能不能完成我们的目标?答案是能,但是会有几个问题。
第一,Google抓取的页面不一定是完全的,所以有很大记录无法正确匹配指纹;第二,这种大量的访问请求与目录扫描简直无异,违背了我们当初使用Google搜索那种“大海捞针”、十分优雅的感觉,所以在本次课题中将不予讨论,但是在技术上是有可实现性的。
7.功能性文件收集
除了普通的信息收集,对于一个网站功能点的收集也是一个重点
文件上传功能,作为能产生高危漏洞的功能点之一,文件上传功能受到攻击者额外的青睐,
site:example.com inurl:upload|upfile|saveup intext:提交|确定|上传
文件下载功能,与文件上传相对,关键字由up变为down,上传变为下载,不赘述。
文件读取功能,这部分带来的漏洞就是文件包含,我们可以尝试常用的关键字:
site:example.com inurl:"path="|"readfile="|"file="|"url="
留言评论功能,如下:
site:example.com intext:提交|确定|评论
个人空间,常见的越权、储存型XSS等漏洞的汇聚地:
site:example.com intext:个人信息管理|会员|个人空间 OR inurl:member|zone
其他功能大家自行拓展。
8.易受攻击文件收集
易受攻击的文件,包含那些被报过漏洞的页面,或容易遭到攻击的功能页面。
这部分参考GHDB,以及我们日常积累的漏洞页面。举个例子,曾经报出的 Weblogic SSRF漏洞,就可以通过下面的搜索被找到:
site:example.com inurl:"/uddiexplorer/SetupUDDIExplorer.jsp"
如果你积累的够多,这个信息收集框架就能活活被你搞成漏洞扫描器。
9.被入侵位置查询
这是一个在实战中拓展的思路,有一次日一个站,这个站之前被黑过,连webshell还没来得及删直接加了一个防护,各种绕不过,但是后来发现页面被挂了博彩页面,通过搜索被挂了相同博彩页面的网站后,发现了是借由某个最新发布的漏洞批量搞的,于是使用相同的点入侵这个站就拿下来了。因此,搜寻已经遭受入侵的证据,也是信息收集中应有的步骤。
博彩、广告、反共言论查询,这部分通过intext来实现即可,由于搜索字符长度的限制,我们将关键字拆分,分为多次查询完成,同样的,这部分大家可以自由扩展。
site:example.com intext:博彩|澳门|反共|色情|百家乐|轮盘|时时彩|荷官|香港彩|娱乐城|性爱|大陆|共匪|楼凤|外围|良家|一夜情|交友|上门服务
site:example.com intext:裸聊|找小姐|返水|自拍|六合彩|同城交友|丝袜|少妇|小姐|狼友|桑拿|夜生活|真人娱乐|真钱|娱乐城|免费试玩|随时结算
site:example.com intext:老虎机|真人娱乐|返点|德州扑克|棋牌|进入直播|游戏账号|"VIP俱乐部"|菠菜...
历史遗留后门文件,在遭受攻击之后,有的黑客可能会留下webshell,以便更加方便的远程操作服务器,因此通过搜寻服务器上是否包含一些小马、大马、黑页或其他的文件,也可以给我们提供帮助。
site:example.com intext:剑眉大侠|不灭之魂|仗剑孤行|通杀版|法客论坛|上传的口令|"导出DLL文件出错"|"token虚拟机管理"|老子的绝对路径|免杀版
site:example.com intext:法克|后门|木马|小马|大马|脱库|黑客|一句话后门|挂马|清马|"扫描IP"|开放端口|提权|执行命令|设置密码|提升权限
site:example.com intext:一句话木马|过狗|安全狗|"K8飞刀"|"K8拉登哥哥"|"K8搞基大队"|反弹端口|"hacked by"...
除了关键字之外,还可以利用常见的木马文件名称来查找:
site:example.com inurl:phpspy|udf|JFolder|JspSpyJDK5|AspxSpy2014Final...
webshell 文件名可以通过在 github 上搜索相关的项目得到,不过这种方式会存在一定的误报,而且命中率也比较低,可以作为与intext查找的互补使用。
其他特征文件,除了木马和黑页之外,还可以拓展其他思路,例如,部分黑客在拿下一台服务器权限后想要进一步内网渗透,除了远程连接的这台服务器,然后把自己的工具全装在服务器上(汗,年轻的时候还真这么干过)之外,更好的方式是利用代理来实现,使用起来比较方便著名的有regeorg+proxifier的组合,黑客需要将regeorg对应语言的文件上传至服务器,在未更改的情况下,访问该页面会出现Georg says, 'All seems fine'的字样,我们可以通过搜索这个关键字来查看服务器是否遭受了内网渗透:
site:example.com intext:"Georg says" intext:"All seems fine"
类似地,使用 AWVS 等扫描器,对weblogic、struts2等漏洞进行测试验证时,也会向服务器上上传测试文件,我们也可以用里面的验证字段来搜索,类似:
site:example.com intext:"Struts2 Exploit Test"
10.历史记录查询
搜索引擎由于爬虫的周期性,通常对于网站抓取的更新是要慢于网站本身的更新一段时间的,因此,在使用搜索时,可能搜索到一些已经消失的页面,不过并不影响我们在其中获取敏感信息。如果想要从 Google 缓存中得到数据,则考虑使用 cache 关键字。
五、代码实现
在思路清晰、查询语句基本成熟之后,我们希望能够将其编写成代码,能够在实际使用时由计算机替我们快速实现。
于是,就迎来了我Github上的第五个小可爱:Elena。
核心的文件在包google_hack下,google_search提供google查询类,ghdb.json记录整理好并可以使用的搜索语法,google_hack将两者结合在一起,进行查询。logfile文件夹下存放日志文件。config文件夹下settings文件是用户自定义设置文件。
module包内,logger提供日志输出及记录功能,report提供将查询结果返回html格式的报告。
这里没有使用 Google提供给我们的 API,因为每天免费一百条,查多了就会收费。
为了解决直接查询会被封IP的情况,我们使用采用代理池随机抽取的方案。具体代码请移步 Github 查阅,欢迎指导。这里放两张截图。
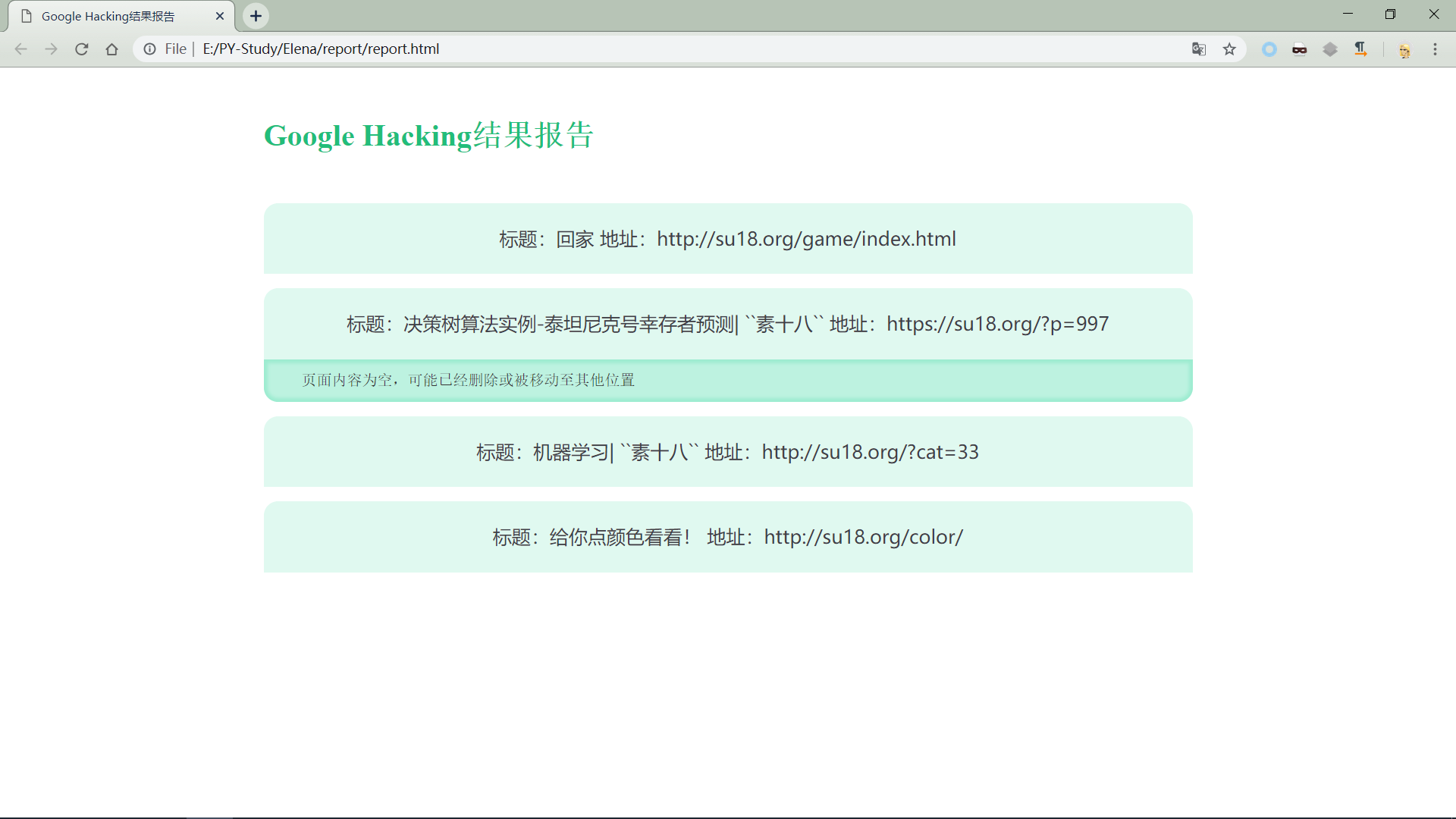
在测试样例中,为了展示效果,我们对 http://su18.org 查询了四个在Google中抓取到的目录。
程序运行:
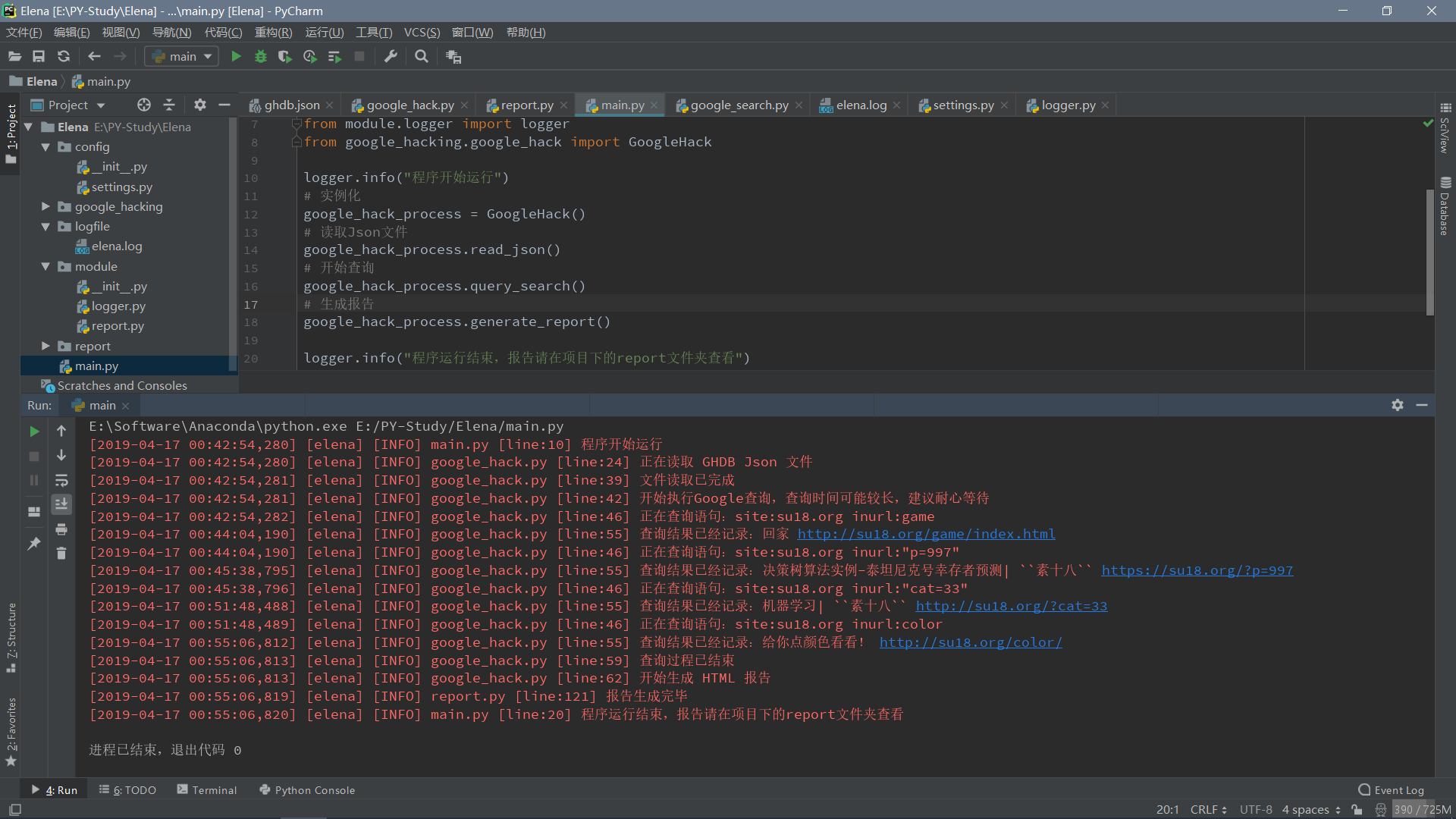
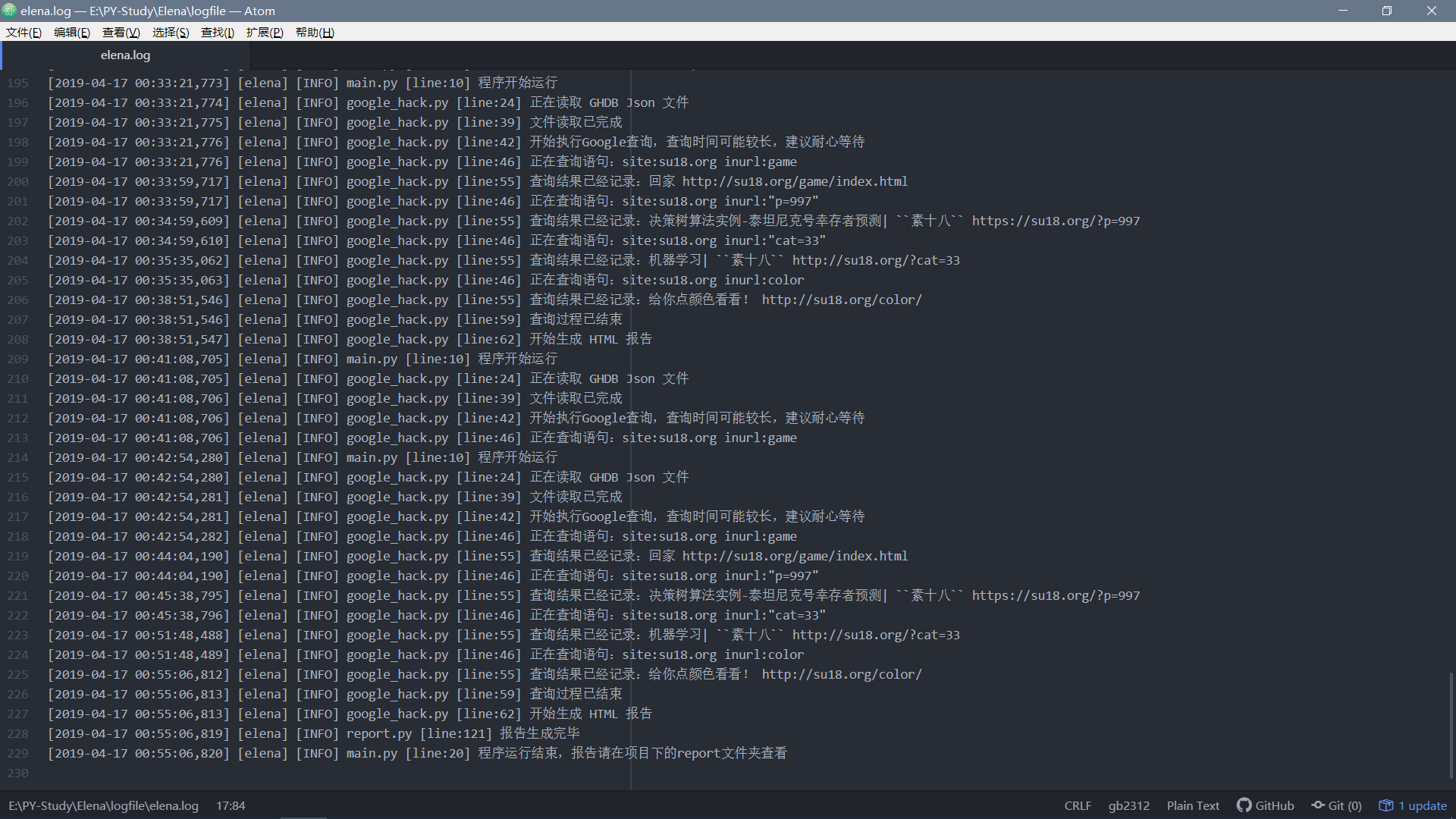
日志记录:
报告样例:
点击条目会返回目标页面源码:
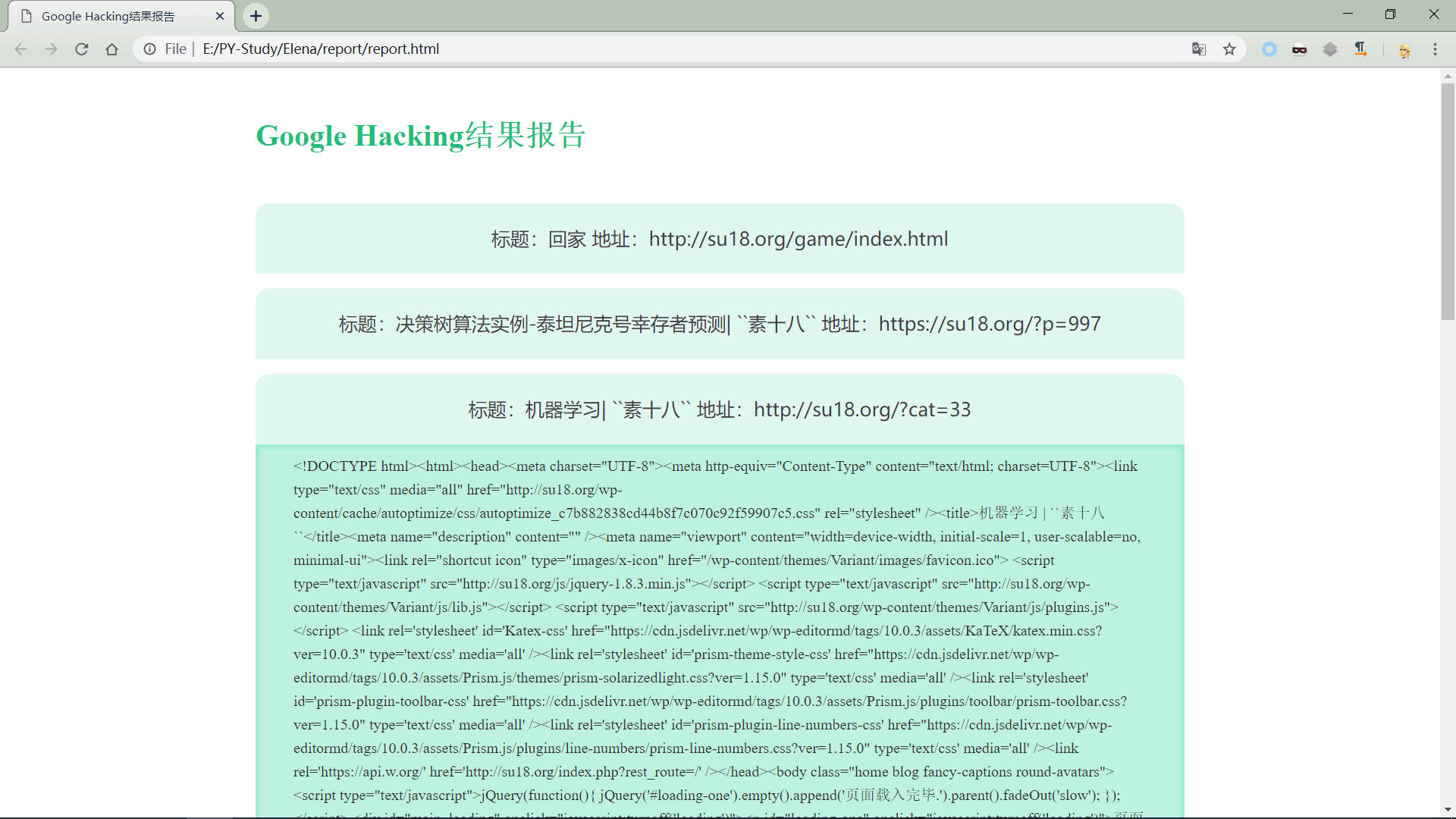
实际上可以看到,在编写程序的后期,为了保证程序查询结果的健壮性,及报告的充实性,在从Google 查询中得到结果后,还是直接访问了我们查询到的网站地址,并获取了一些信息添加到报告之中。
而且,由于本人没有那么多代理,所以程序写的是单线程(汗)。
项目地址:https://github.com/su18/Elena
六、一些补充
本章99%的搜索语句我都测试并优化过,建议各位自行测试加深印象,对于思路,千万不要被我的想法和分类固化,因为还有很多方面我没有覆盖到,希望各位自行发散。
到此为止,我们已经完成了这次的课题,对Google Hack进行的学习、研究并利用python代码进行实现,但是额外再想一下,虽然我们已经成功做到了“不向目标服务器发送一个数据包,但却从中拿走了敏感数据”,其实是指做了一个替代,原本要打到目标服务器中的数据,被打到了 Google 上,尽管我们一再精简,但还是有很多数据包将要发送。
我们可能会担忧,在这期间,我们的网络运营商以及能够获取这部分数据的团体,可以通过我们的流量来检测我们的行为,或者Google本身就能够通过我们的行为知道我们的目标是什么。
这显然不是我们想要的,那怎么进一步进行隐匿呢?
第一是使用代理,因为除此之外我暂时想不出更有效的方案了。在向Google发送请求时使用代理,来隐藏自己。
第二是使用一些匿名的搜索引擎,如 duckduckgo ,它承诺在处理我们的请求时不会保存用户数据用于其他目的(但是我们也不知道)。
第三是不使用自己的资源进行请求,我们在网站找到一些能够替我们请求并返回结果的页面(类似SSRF那种),以他们作为我们的上层代理。(除了提供这种服务的网站之外,属于利用其它网站的漏洞进行恶意访问,理论上违法,这里只是纯技术上的讨论,请勿实践,另外,这些网站也不一定拥有能够连接到Google的网络服务。)
在样例中和代码中,各位可以手动试用一下上述搜索语句,并按照自己的喜好进行精简或优化,以获得更加精准的目标命中或更加广阔的结果返回。更多的用法和拓展也需要大家去补充了。
虽然我们本文使用了Google这个搜索引擎进行这方面的实现,但是作为国内最大的搜索引擎百度,在信息收集方面,并不是一无是处,首先,对于中文的智能语义化处理,百度就较Google稍强。另外百度贴吧,百度网盘里,资源也是大大的有。有兴趣的也可以试试其他国家的或比较著名的搜索引擎,都会有意想不到的发现。
同时不要忘了,这篇文章仅仅是我作为安全学习路上一篇记录,尽管努力地编写优雅的代码,但是由于入门级的Python水平加上时间的不允许,也只能是作为一个学习过程的产物,并不是什么拿的上台面的东西,而作为信息收集部分的工具,仅仅是针对单一网站进行的操作,如果你想针对全网进行收集,可以修改我的脚本,但是也千万不要忘了使用已经近乎成熟的利器:https://www.shodan.io/、https://www.zoomeye.org/ 。
总结一下:学习Google Hacking在实战中是有帮助的,造个轮子没别的意思,就是在练习写python的过程中顺便熟悉知识点,整理思路。差不多就到这吧。
七、参考文档及拓展资料
《Google Hacking 渗透性测试者的利剑》 清华大学出版社 沈卢斌译
www.google.com/help/basics.html Google基础搜索文档
http://www.mrjoeyjohnson.com/Google.Hacking.Filters.pdf 很棒的Google Hack 学习资料
https://www.exploit-db.com/google-hacking-database/ GHDB
https://www.cifnews.com/article/29108 Google搜索的20个技巧
https://zhuanlan.zhihu.com/p/41410213 Google彩蛋
http://www.zarias.com/funny-google-searches/ 有趣的Google搜索
https://www.vendasta.com/blog/32-fun-google-tricks Google小技巧
https://zety.com/work-life/google-search-hacks 40+Google贴士
https://pentest-tools.com/information-gathering/google-hacking Google Hacking 小工具
http://www.dianbo.org/9238/ 搜索研究院(资源较老,但很有借鉴性)
https://github.com/opsdisk/pagodo/blob/master/google_dorks_20181229_113249.txt 一些Google语法
https://github.com/K0rz3n/GoogleHacking-Page/blob/master/Google%20Hacking%20Database.md 一些参考
https://www.cnblogs.com/xudong0520/p/5797828.html 一些参考
http://www.mamicode.com/info-detail-552937.html 一些Google Hack技巧
https://github.com/anthonyhseb/googlesearch Google Search